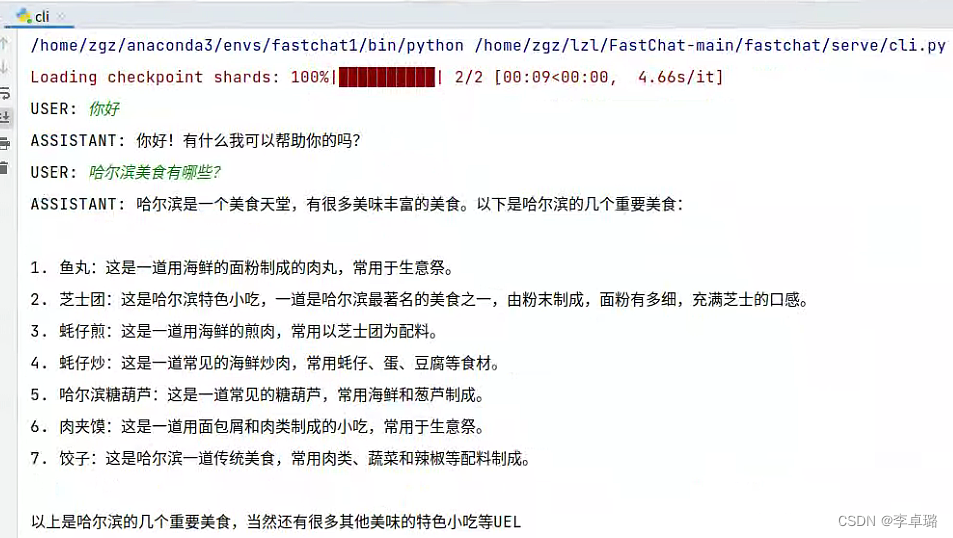
1、Vicuna【小羊驼】-FastChat"更快的对话" 介绍
3 月底,UC伯克利开源大语言模型Vicuna来了,这是一个与 GPT-4 性能相匹配的 LLaMA 微调版本。“缺啥补啥缺啥练啥,傻子也突出”!
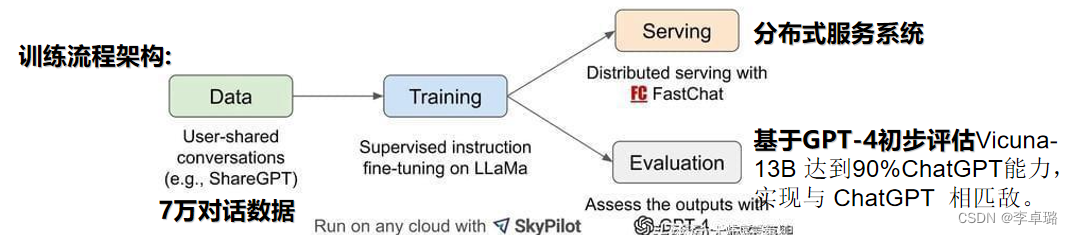
Vicuna 使用从 ShareGPT 收集的用户共享数据对 LLaMA 模型进行微调(ShareGPT 是一个 ChatGPT 数据共享网站,用户会上传自己觉得有趣的 ChatGPT 回答)。利用ShareGPT的7万对话数据对LLaMA微调。
Vicuna训练硬件:8块 A100 80G的GPU(比Alpaca训练花销便宜一半)
相对于Alpaca 进行了如下改进:
1.内存优化:将最大上下文长度从 512 扩展到 2048,利用梯度检查点和闪存注意力来解决内存压力问题。
2.多轮对话:该研究调整训练损失以考虑多轮对话,并仅根据聊天机器人的输出计算微调损失。
3.通过 Spot (SkyPilot)实例降低训练成本。
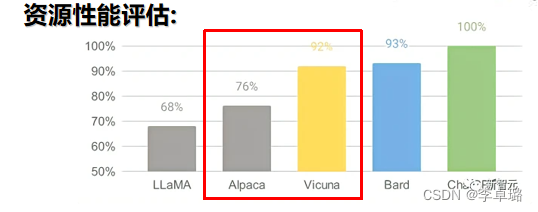
结果:Vicuna 比 Alpaca 的生成质量更好,速度也更快。仍然不擅长涉及推理或数学的任务
运行界面:
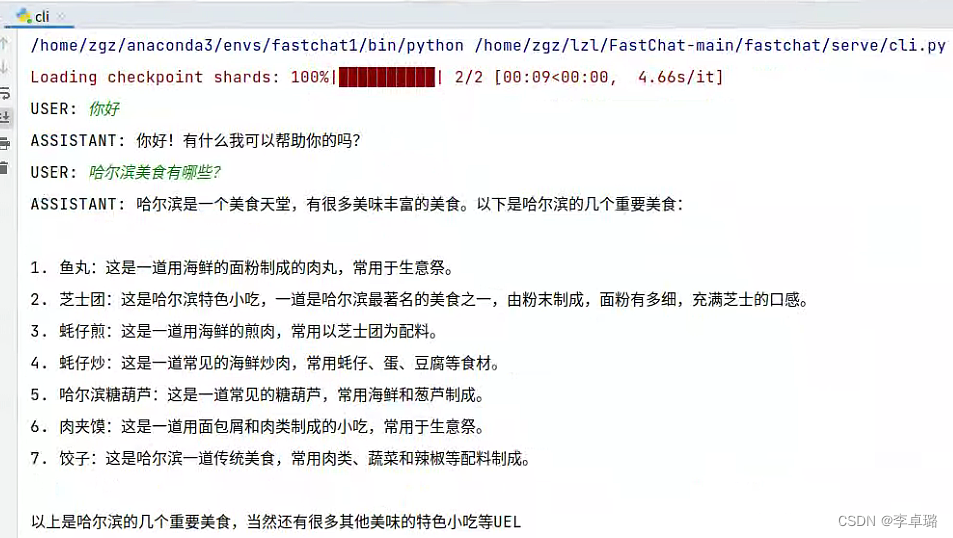
2、Vicuna【小羊驼】实战
FastChat模型GitHub代码地址
部署步骤如下:(注意使用的是Linux系统单片3090,如若尝试用Windows请注意内存是否充裕(至少>30G))
创建并配置FastChat虚拟环境
1.前置软件Git
sudo apt install git
2.创建FastChat虚拟环境
conda create -n fastchat python=3.9 #官网要求Python版本要>= 3.8,注意不要安装错版本了
conda activate fastchat
3.安装PyTorch
pytorch官方网址
pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116
安装完后进行如下测试(可忽略)
conda activate fastchat
python
>>> import torch
>>> print(torch.__version__)
1.13.1+cu116
>>> print(torch.version.cuda)
11.6
>>> exit()
4.安装 FastChat
pip install fschat
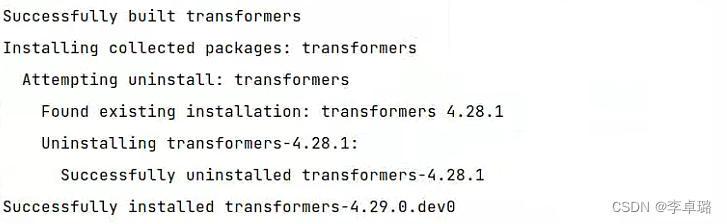
5.安装 huggingface/transformers
不可省略:在fastchat项目下,打开pyproject.toml文件,移除掉dependencies中的transformers(红框内容删除)

pip install git+https://github.com/huggingface/transformers
#确保已经安装好Git,否则安装huggingface/transformers时将报错
(上面没有成功时才考虑)尝试平替
手动下载https://github.com/huggingface/transformers
pip install transformers#尽量选高版本
6.下载 LLaMA
百度PaddlePaddle(7B的模型) https://aistudio.baidu.com/aistudio/datasetdetail/203425/0
请注意:下载的解压、保存文件的路径中 ,不要有中文、特殊符号等。

7. 转换LLaMA的文件,构建FastChat对应的模型Vicuna
#进入到huggingface/transformers项目中,利用transformers中的代码,完成对LLaMA的转换
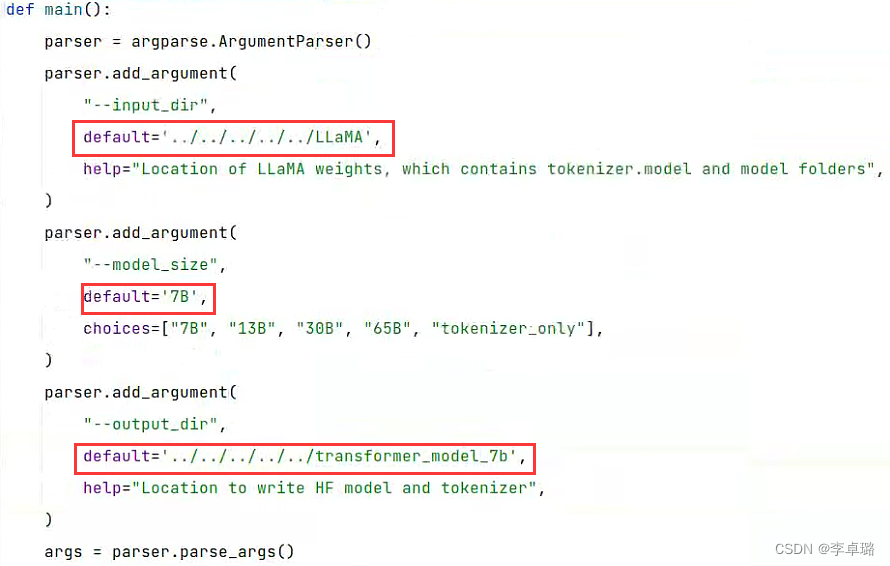
cd src/transformers/models/llama/convert_llama_weights_to_hf.py#不需要指令,手动打卡即可
#--input_dir指定的是刚才你下载好的LLaMA文件地址,这个路径下有个tokenizer.model文件,请仔细核对一下
#--model_size指定用哪个参数数量级的模型,7B代表的是70亿个参数的那个模型(如果你用的种子链接下载的话,还有13B/30B/65B的模型)
#--output_dir是转换后输出的路径
修改convert_llama_weights_to_hf.py文件,添加default变量后执行即可。
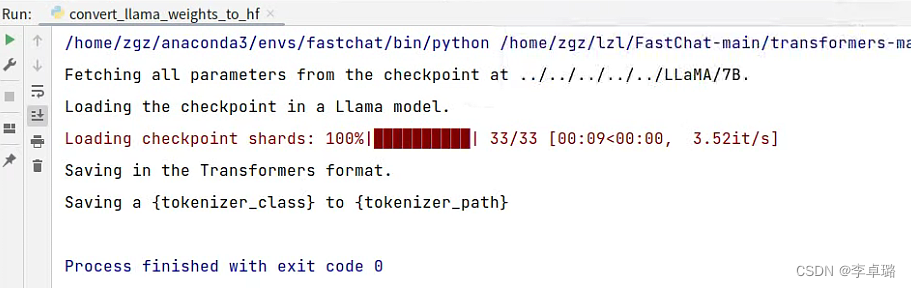
8.生成FastChat对应的模型Vicuna
生成Vicuna模型,即将原始的LLaMA weights转为Vicuna weights
前提:保证内存充足!
Vicuna-13B 需要大约60GB内存
Vicuna-7B 需要大约30GB内存
cd fastchat/model/apply_delta.py#同理手动进去找到apply_delta.py即可
修改apply_delta.py文件,注意一定要删掉required(红框)内容或改为false,因为true指的是命令框输入。

请注意!请注意!请注意!
vicuna-7b-delta-v1.1不是v0!!!
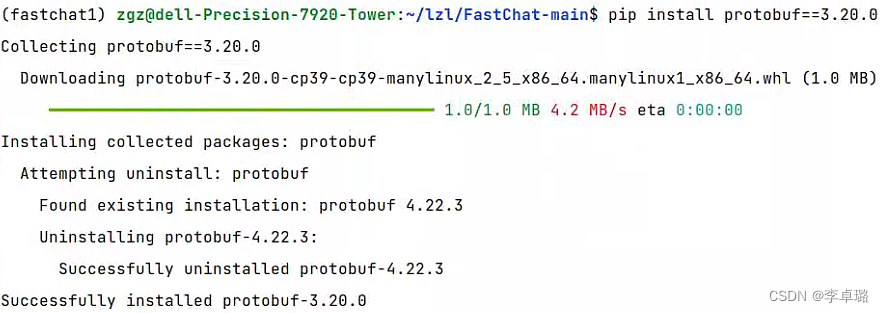
遇到个小错误
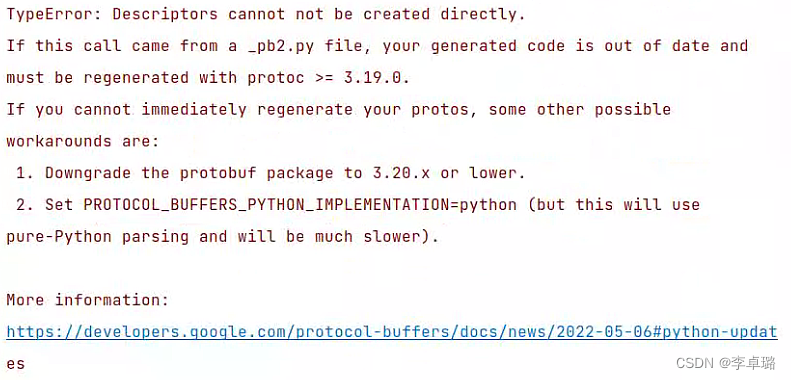
提示我protobuf版本过高,因此uninstall一下后创新install,成功!

9.启动FastChat
cd fastchat/serve/cli.py
找到cli.py进行修改

执行