学习一个短语!
gain proficiency in 熟练掌握
(用我最爱的文心一言造个句子)

最近羊驼家族百花齐放,赶紧学习一下 ChatBot 的背后细节。Chinese-Vicuna 中文小羊驼是基于 Vicuna 模型使用中文数据 + LORA 方案来微调的一种中文对话模型,是一个具备一些基础通用的中文知识模型,它具体能实现什么功能呢?

但是它也会附和你

接下来看看它实现的具体细节,它一个中文低GPU资源的llama+lora方案,使用一张2080Ti 即可训练该模型(当然训练的是语言大模型的很少的一些层)。它使用 BELLE 和 Guanaco 作为训练数据集;开源的这套代码使用了 PEFT's LORA interface + transformer's trainer + instruction data configuration,完成了中文版小羊驼的训练。其中 PEFT 指的是 State-of-the-art Parameter-Efficient Fine-Tuning (PEFT) methods,是一种高效的微调方法。
PEFT 是什么呢?
随着模型变得越来越大,在消费级硬件上对模型进行全部参数的微调变得不可行。此外,为每个下游任务独立存储和部署微调模型变得非常昂贵,因为微调模型与原始预训练模型的大小相同。PEFT 方法旨在解决这两个问题,PEFT 方法仅微调少量 (额外) 模型参数,同时冻结预训练 LLM 的大部分参数,从而大大降低了计算和存储成本。
其实 LORA 就属于PEFT 中的一种方式,HuggingFace 开源的一个高效微调大模型的 PEFT 库,目前包含LoRA,Prefix Tuning,Prompt Tuning,P-Tuning 四种算法。
LORA 是什么呢?
简单来说,lora 是一种轻量的网络结构,可以以插件的形式连接到大模型上(各种你不可能训动的模型,比如 llama, alpaca, guanaco),然后使用你的小数据集 finetune lora 结构,最终产出一个非常小的权重模型(大约在30M左右),那么这个 lora 模型就可以充分基于大模型的先验知识迁移到你的小数据集场景中。一般在图像生成的 Stable Fusion 中 LORA 用的比较多。随着大模型逐渐统一, lora 对于大模型的落地应用不容小觑。


LoRA 与 Transformer 的结合也很简单,仅在 QKV attention 中 QKV 的映射增加一个旁路(可看下文中具体的 LORA 网络结构),而不动MLP模块。基于大模型的内在低秩特性,增加旁路矩阵来模拟全模型参数微调,LoRA通过简单有效的方案来达成轻量微调的目的,可以将现在的各种大模型通过轻量微调变成各个不同领域的专业模型。
训练中文 vicuna 的数据集组成格式为:
{'instruction': "用一句话描述地球为什么是独一无二的。\\\\n\\n"'input': ""'output': "地球上有适宜生命存在的条件和多样化的生命形式。"}
在训练过程中,通过库 datasets 来加载数据。作者使用的数据集共693987条,每一条都是如上的组织格式,下图展示了前 3 条样本的内容。
from datasets import load_datasetDATA_PATH = ./sample/merge.jsondata = load_dataset("json", data_files=DATA_PATH)

对于数据预处理,以这样一条数据为例:
{'instruction': '将第一段文本中的所有逗号替换为句号。\\\\n\\n\\\\n"在过去的几年中,我一直在努力学习计算机科学和人工智能。"\\\\n','input': '','output': '"在过去的几年中。我一直在努力学习计算机科学和人工智能。"'}
user_prompt 为:
'Below is an instruction that describes a task. Write a response that appropriately completes the request.\\n\\n### Instruction:\\n将第一段文本中的所有逗号替换为句号。\\\\n\\n\\\\n"在过去的几年中,我一直在努力学习计算机科学和人工智能。"\\\\n\\n\\n### Response:\\n'# 注意 user_prompt 只包含一个统一的场景描述 + 'instruction' + 'input'full_tokens = tokenizer(user_prompt + data_point["output"],truncation=True,max_length=256 + 1,padding="max_length",)["input_ids"][:-1] # 不要最后一个 <eos> token
会将 user_prompt + output 均 token 化,并且将 full_tokens pad 到固定长度 256,pad_id 为 0. 在训练和推理过程中,设置模型最大输入数据长度为 256 tokens。# 256 accounts for about 96% of the whole data.

之后这一串 ID 就是输入到模型中的东西,长度固定为 256, 包含了 user_prompt + output 信息;值得注意的是,对应输入的 label 只给了 output 部分的 ID,相当于只对 output 部分计算 loss。
类比于目标检测的训练过程,输入为目标的框的坐标,模型学习预测框的坐标;文本模型为输入文本在词表对应的 ID,模型学习预测文本在词表对应的 ID(模型输出的维度为词表长度维度,这里为 32000),最后将输出的 ID 基于词表映射,就可以得到输出的文本语句。单个样本在 token 化后的 attention_mask 为全 1,即所有的 tokens (包括 pad token)均会参与 attn 计算。
准备完数据后,看下 LORA 模型的结构组成,LLaMA是由 32 层 Transformer 组成,LORA 添加的网络结构只是在 QKV 同维度映射时添加了降维升维两个线性层,一共添加了 32*2 层额外的线性层。在训练过程中,模型学习的就是 lora_A/lora_B 这些层。
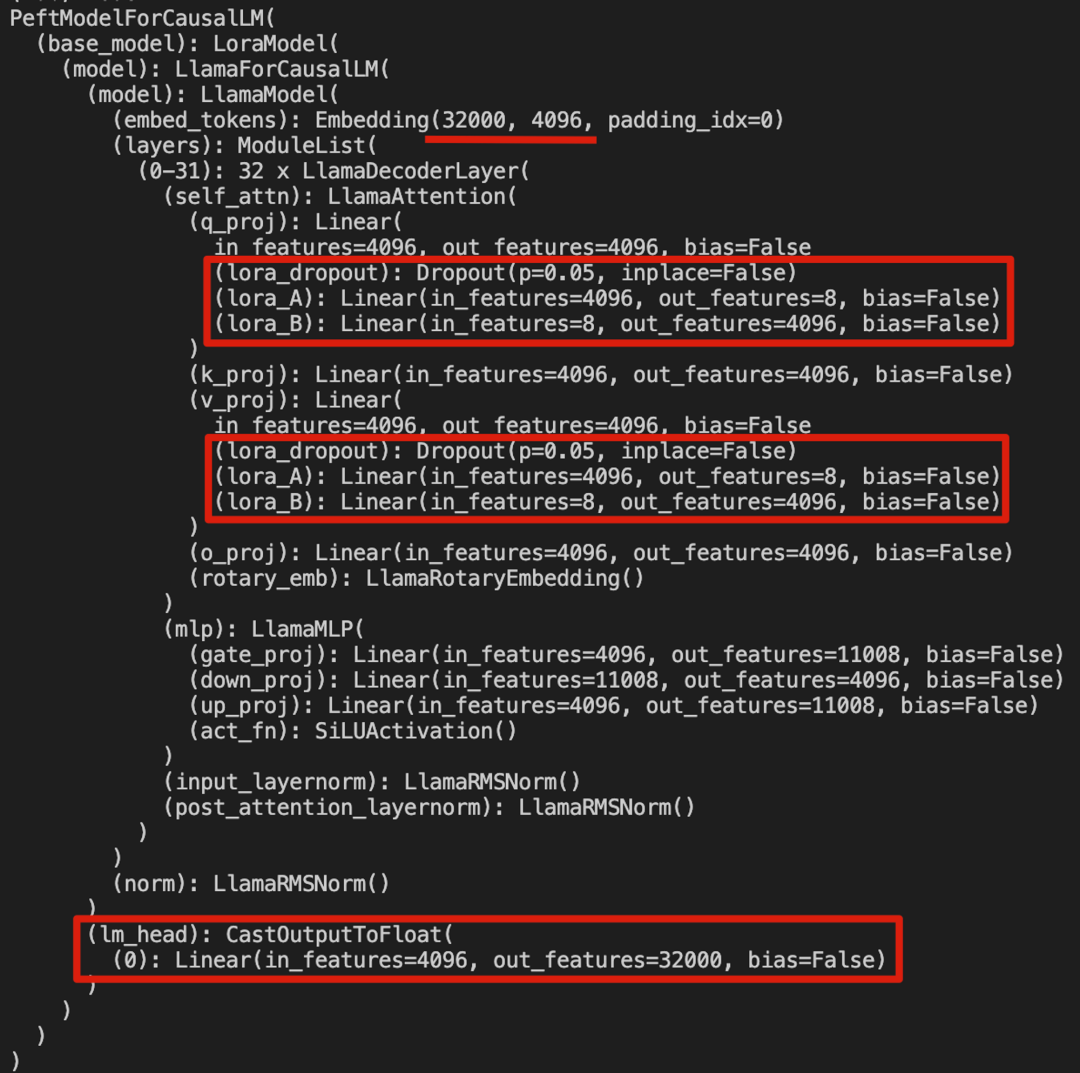
最后简单说一下 NLP 训练对于文本的处理。之前以为 NLP 非常复杂,但是看了Chinese-Vicuna的训练代码,感觉还是逻辑分明的。如果我们要训练一个 NLP 网络,我们需要先找到一个 tokenizer,能够把语言文本基于一个预先设定好的词表来映射成一个 id,这样就把文字/字符变成了数字表示,然后通过一个 nn.Embedding() 来为每一个 id 表征一个高维特征,输入到 transformer 层中的就是这些 id 对应的特征(还会通过使用 pad_token 将输入长度补全到固定长度 256/4096)。对于模型的输出,是通过一个词表长度的 FC 来得到每一个单词的输出概率。最终通过自回归的输出方式,直到预测得到 “<eos>”,就得到了模型的文本输出。