pyspark安装教程
一、Windows下配置pyspark环境
在python中使用pyspark并不是单纯的导入pyspark包就可以实现的,而是需要由不同的环境共同搭建spark环境,才可以在python中使用pyspark。
搭建pyspark所需环境:python3,jdk,spark,Scala,Hadoop(可选)
1.1 JDK下载安装
下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
打开Windows中的环境变量:
- 创建JAVA_HOME:C:\Program Files\Java\jdk1.8.0_181
- 创建CLASSPATH:.;%JAVA_HOME%\lib;%JAVA_HOME%\lib\tools.jar
在Path添加:%JAVA_HOME%\bin;
测试是否安装成功:打开cmd命令行,输入java -version

1.2 Scala下载安装
下载地址:https://downloads.lightbend.com/scala/2.12.8/scala-2.12.8.msi
下载后进行安装
- 创建SCALA_HOME: C:\Program Files (x86)\scala
- Path添加:%SCALA_HOME%\bin
测试是否安装成功:打开cmd命令行,输入scala -version

1.3 spark下载安装
下载地址:http://mirror.bit.edu.cn/apache/spark/spark-3.0.0-preview2/spark-3.0.0-preview2-bin-hadoop2.7.tgz
也可以选择下载指定版本:http://spark.apache.org/downloads.html
下载好之后解压放在随便一个目录下即可,但是目录名不可以有空格。
环境变量:
- 创建SPARK_HOME:D:\spark-2.2.0-bin-hadoop2.7
- Path添加:%SPARK_HOME%\bin
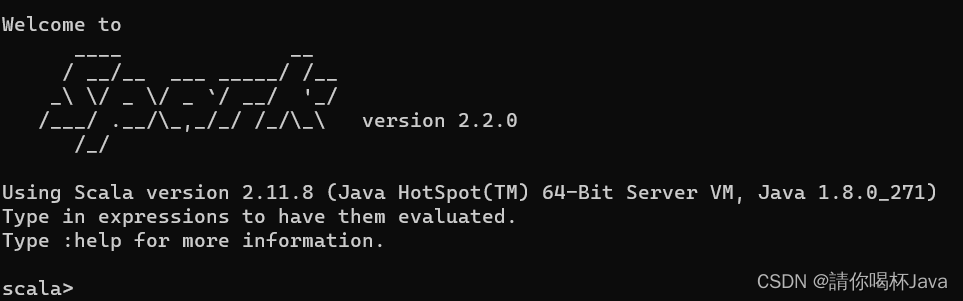
测试是否安装成功:打开cmd命令行,输入spark-shell
1.4 Hadoop下载安装
如果你需要去hdfs取数据的话,就应该先装hadoop。
下载地址:
http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
解压到指定目录即可。
环境变量:
- 创建HADOOP_HOME:D:\hadoop-2.7.7
- Path添加:%HADOOP_HOME%\bin
测试是否安装成功:打开cmd命令行,输入hadoop
hadoop测试时报错:Error: JAVA_HOME is incorrectly set。参考:https://blog.csdn.net/qq_24125575/article/details/76186309
1.5 pyspark下载安装
pycharm中安装pyspark
二、pyspark原理简介
pyspark的实现机制可以用下面这张图来表示
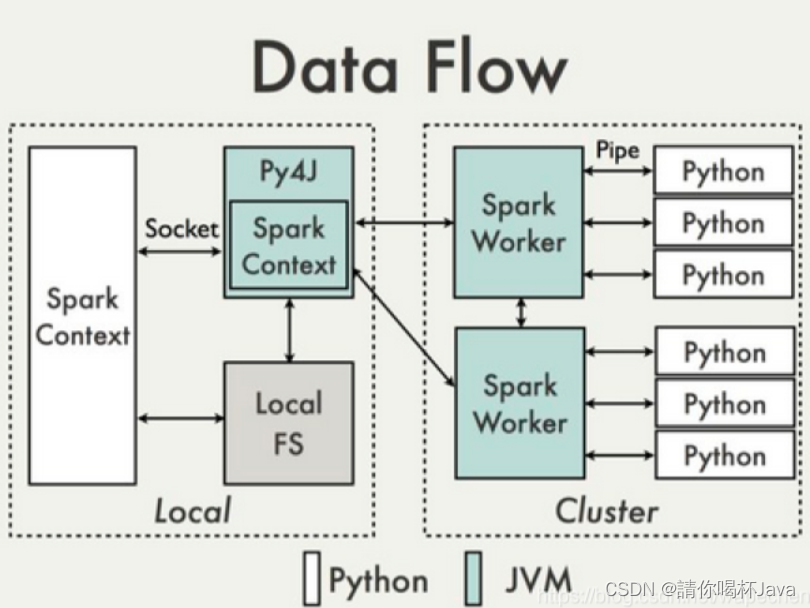
在python driver端,SparkContext利用Py4J启动一个JVM并产生一个JavaSparkContext。Py4J只使用在driver端,用于本地python与java SparkContext objects的通信。大量数据的传输使用的是另一个机制。
RDD在python下的转换会被映射成java环境下PythonRDD。在远端worker机器上,PythonRDD对象启动一些子进程并通过pipes与这些子进程通信,以此send用户代码和数据。