背景:小组成员都习惯用python,但是有spark计算的需求,需要一个快速上手的环境
https://www.cnblogs.com/zhw-080/archive/2016/08/05/5740580.html
这位朋友已经写得很详细,就是自己手写环境变量够不够细心的问题
第一步:安装anaconda
试一下命令行启动,确保ipython从anaconda启动
第二步:安装spark(需要提前安装JDK)
到官网下载spark安装包
http://spark.apache.org/downloads.html
我直接下的最新版本
第三步:配置系统环境变量
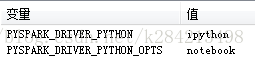
直接贴出
Path中的内容
C:\ProgramData\Oracle\Java\javapath;
%SystemRoot%\system32;%SystemRoot%;
%SystemRoot%\System32\Wbem;
%SYSTEMROOT%\System32\WindowsPowerShell\v1.0\;
D:\Anaconda3;
%JAVA_HOME%\bin;
%JAVA_HOME%\jre\bin;
%SPARK_HOME%\bin;
%SPARK_HOME%\sbin;
D:\spark-2.2.0-bin-hadoop2.7\spark-2.2.0-bin-hadoop2.7\python\pyspark
PYTHONPATH中内容
%SPARK_HOME%\python\lib\py4j;
%SPARK_HOME%\python\lib\pyspark;
D:\Anaconda3
第四步:拷贝 E:\spark\python\pyspark 到 D:\anaconda\Lib\site-packages 目录下
第五步:启动 配置好后在cmd中直接输入 pyspark
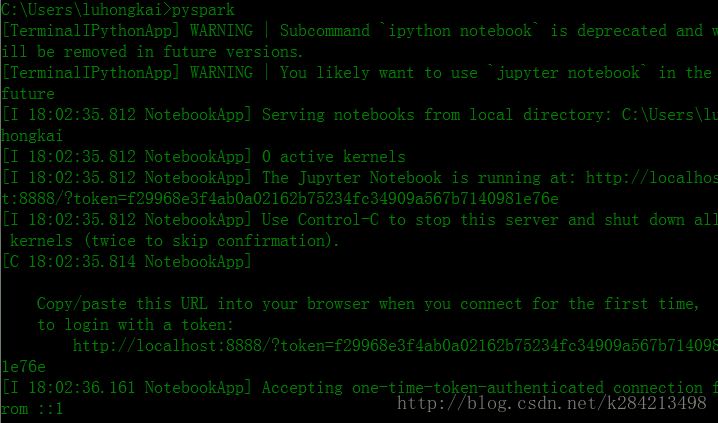
成功的话网页会自动打开http://localhost:8888/tree#
测试:
from pyspark import SparkContext
sc = SparkContext.getOrCreate()#我这里不用getOrCreate会报错
print("pyspark version:" + str(sc.version))pyspark version:2.2.0
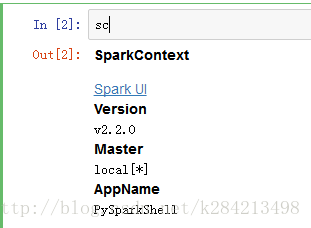
这里还有很多可以学习和测试的例子
https://www.iteblog.com/archives/1395.html
遇到的问题
我直接在cmd中启动pyspark后,未做任何import,读取到的sc是这样的 空值
from pyspark import SparkContext
sc=SparkContext("local","PySparkShell")#这种方法启动会遇到
Cannot run multiple SparkContexts at once; existing SparkContext(app=PySparkShell, master=local[*]) created by <module> at D:\Anaconda3\lib\site-packages\IPython\utils\py3compat.py:186 的问题
就算用getOrCreate()启动,sqlContext = SQLContext(sc)也是会报错,因为已经启动过,再启动数据库那边一样会报错
Another instance of Derby may have already booted the database C:\Users\luhongkai\metastore_db.
Caused by: java.sql.SQLException: Unable to open a test connection to the given database. JDBC url = jdbc:derby:;databaseName=metastore_db;create=true, username = APP. Terminating connection pool (set lazyInit to true if you expect to start your database after your app). Original Exception: ------总之各种各样的问题
我在想是不是cmd打开pyspark和import的时候启动过一个SparkContext,然后再启动就会有问题
尝试手动启动
import os
import sys
spark_path = "D:/spark-2.2.0-bin-hadoop2.7/spark-2.2.0-bin-hadoop2.7"
os.environ['SPARK_HOME'] = spark_path
os.environ['HADOOP_HOME'] = spark_path
sys.path.append(spark_path + "/bin")
sys.path.append(spark_path + "/python")
sys.path.append(spark_path + "/python/pyspark/")
sys.path.append(spark_path + "/python/lib")
sys.path.append(spark_path + "/python/lib/pyspark.zip")
sys.path.append(spark_path + "/python/lib/py4j-0.10.4-src.zip")
from pyspark import SparkContext
from pyspark import SparkConf
sc = SparkContext("local", "test")
凑合着用吧
后续会尝试
spark_df=sqlContext.createDataFrame(pandas_df)
的一些用法