前言
阴影是图像中常见的现象,它们对于场景理解和分析非常重要。由于阴影区域通常比较暗淡,而且与周围物体区别较大,因此在图像处理和计算机视觉领域中,阴影检测是一个重要的研究方向。传统的阴影检测算法通常基于阈值或边缘检测等基本技术,但这些方法难以应对复杂的场景和不同光照条件下的挑战。近年来,随着AI技术的发展,基于卷积神经网络(CNN)的阴影检测方法成为了一个热门的研究方向,并在许多实际场景中取得了较好的性能。本文将介绍如何结合传统的图像处理算法和机器学习技术来实现阴影检测,并探讨这种方法在不同场景下的效果和适用性。
技术方案
step1:对静态图像进行阴影检测前首先通过加权中值滤波进行图像预处理
step2:对于处理后的图像使用mean shift算法将图像分割成若干区域
step3:对分割好的图像区域,提取颜色特征、亮度特征、纹理特征归一化输入svm分类器得到区域对信息,根据区域对信息结合阴影特征完成阴影检测
加权中值滤波是一种基于排序的滤波方法,它可以有效地去除图像中的噪声和小细节。在阴影检测中,加权中值滤波可以用于平滑阴影边缘,从而提高阴影检测的准确性。
Mean Shift算法是一种基于密度估计的聚类方法,可以用于图像分割和目标跟踪等任务。在阴影检测中,Mean Shift算法可以用于聚类图像中的像素,以便进一步分离阴影区域和非阴影区域。
图像特征是指从图像中提取出的代表图像特点的数值量。在阴影检测中,常用的图像特征包括颜色特征、亮度特征、纹理特征等。这些特征可以用来训练分类器,以便将阴影区域和非阴影区域进行区分。
SVM分类器是一种常用的监督学习算法,它可以用于分类和回归等任务。在阴影检测中,SVM分类器可以用于训练一个分类模型,以便将图像中的像素分成阴影区域和非阴影区域。SVM分类器的优点是可以适应不同的图像特征,因此在不同的场景中具有较好的通用性。
代码呈现
图像分割
阴影检测第一步就是对图像进行分割,图像分割用到的mean shift算法将图像分割成若干区域。当然,在做图像分割之前,先做对图像进行了加权中值滤波进行图像预处理。
因为用到了opencv的接口的中值加权滤波,所以需要安装 pip install opencv-contrib-python==3.4.18.65
import cv2
import os
import numpy as np
from sklearn import cluster
from sklearn.cluster import MeanShift, estimate_bandwidth
from itertools import cycle
from PIL import Image
import matplotlib.pyplot as plt
import matplotlib.pylab as pylab
is_Debug = False
def image_preprocess(img):
kernel = 7
filtered = cv2.ximgproc.weightedMedianFilter(img, img, kernel) ##将图像进行加权中值滤波处理
return filtered
def get_segment_parts(img_orig, labels, n_clusters_):
contours_ret = []
segments_ret = []
for i in range(n_clusters_):
img = np.zeros((img_orig.shape), np.uint8)
img[labels == i] = [255,255,255]
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
ret, binary = cv2.threshold(gray,127,255,cv2.THRESH_BINARY)
kernel = np.ones((7,7), dtype=np.uint8)
binary = cv2.morphologyEx(binary, cv2.MORPH_OPEN, kernel)
contours, hierarchy = cv2.findContours(binary,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)[-2:]
if len(contours) == 0: continue
contours_ret.append(contours)
## get contour roi image
imgroi = np.zeros(img_orig.shape, dtype=np.uint8) # Create mask where white is what we want, black otherwise
cv2.drawContours(imgroi, contours, -1, (255,255,255), -1, cv2.LINE_AA) # Draw filled contour in mask
roi = cv2.bitwise_and(img_orig,imgroi)
segments_ret.append(roi)
if is_Debug:
cv2.drawContours(img,contours,-1,(0,0,255),3)
cv2.imwrite('contours_' + str(i) + '.jpg', img)
cv2.imwrite('roi_' + str(i) + '.jpg', roi)
return segments_ret,contours_ret
def image_segment(img_input, top_k=5):
#image = Image.open('1-1.png')
img_pre = image_preprocess(img_input)
image_arr = np.array(img_pre)
original_shape = image_arr.shape
w = original_shape[1] #宽度
h = original_shape[0] #高度
# Flatten image.
X = np.reshape(image_arr, [-1, 3])
bandwidth = estimate_bandwidth(X, quantile=0.1, n_samples=100)
#print(bandwidth)
ms = MeanShift(bandwidth=bandwidth, bin_seeding=True)
ms.fit(X)
labels = ms.labels_
#print(labels.shape)
cluster_centers = ms.cluster_centers_
#print(cluster_centers.shape)
labels_unique = np.unique(labels)
n_clusters_ = len(labels_unique)
#print("number of estimated clusters : %d" % n_clusters_)
segmented_image = np.reshape(labels, original_shape[:2]) # Just take size, ignore RGB channels.
n_clusters_ = min(top_k, n_clusters_)
segments_ret,contours_ret = get_segment_parts(img_input, segmented_image, n_clusters_)
return segments_ret,contours_ret
输入一张带有阴影的图片

分割出来的各个部分的图片如下
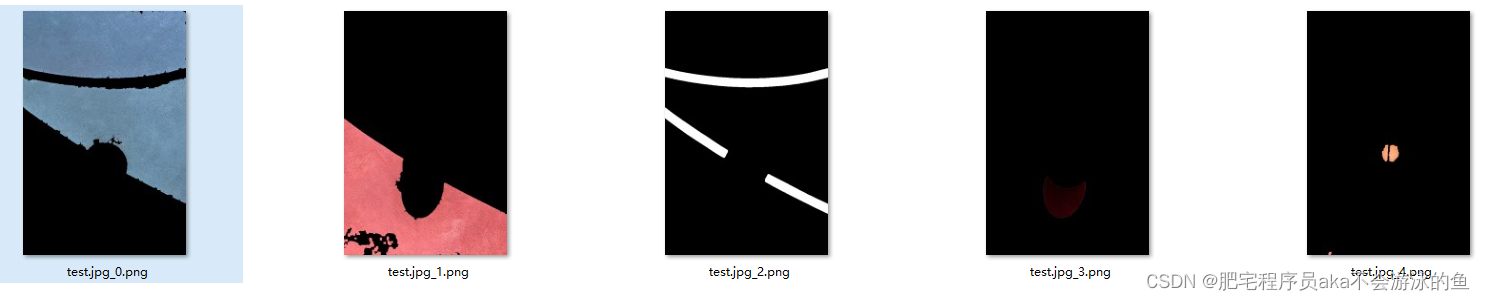
其中第四张图片就是带有阴影的图片

可以看出用上述的技术方案分割出来的各个图块的效果还是比较不错的
特征提取
在完成上述的图像分割之后,需要再对每个分割后的图像单独做图像的特征提取,这里选择的特征主要包含颜色,纹理和亮度特征,具体看代码
from PIL import Image
import numpy as np
import os
from skimage.feature import local_binary_pattern
import cv2
from collections import OrderedDict
from scipy.stats import skew
from scipy.stats import kurtosis
from skimage import feature
def addFeatureList(prefix, value, eps=1e-5):
features = OrderedDict()
for i in range(len(value)):
features[prefix+'_'+str(i)] = value[i] / 255 + eps
return features
class LocalBinaryPatterns:
def __init__(self, numPoints, radius):
# store the number of points and radius
self.numPoints = numPoints
self.radius = radius
def describe(self, image, eps=1e-5):
# compute the Local Binary Pattern representation
# of the image, and then use the LBP representation
# to build the histogram of patterns
lbp = feature.local_binary_pattern(image, self.numPoints,
self.radius, method="uniform")
(hist, _) = np.histogram(lbp.ravel(),
bins=np.arange(0, self.numPoints + 3),
range=(0, self.numPoints + 2))
# normalize the histogram
hist = hist.astype("float")
hist /= (hist.sum() + eps)
# return the histogram of Local Binary Patterns
return hist
def color_feature_ex(img):
features = OrderedDict()
color_featrue = []
r,g,b = cv2.split(img)
# 一阶矩
r_mean = float(r.sum()) / np.count_nonzero(r)
g_mean = float(g.sum()) / np.count_nonzero(g)
b_mean = float(b.sum()) / np.count_nonzero(b)
# 二阶矩
r_std = np.std(r)
g_std = np.std(g)
b_std = np.std(b)
#三阶矩
r_offset = (np.mean(np.abs((r - r_mean)**3)))**(1./3)
g_offset = (np.mean(np.abs((g - g_mean)**3)))**(1./3)
b_offset = (np.mean(np.abs((b - b_mean)**3)))**(1./3)
color_featrue.extend([r_mean,g_mean,b_mean,r_std,g_std,b_std,r_offset,g_offset,b_offset])
features.update(addFeatureList('color', color_featrue))
return features
def texture_feature_ex(img, hist_size=256, lbp_radius=1, lbp_point=8):
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
lbp = LocalBinaryPatterns(5,2)
feature = lbp.describe(img)
feature_ret = OrderedDict()
for i in range(len(feature)):
feature_ret['lbp_'+str(i)] = feature[i]
return feature_ret
def brightness_feature_ex(img, eps=1e-5):
feature_ret = OrderedDict()
lab_img = cv2.cvtColor(img, cv2.COLOR_BGR2LAB)
l,a,b = cv2.split(lab_img) ##Lab颜色空间中的L分量用于表示像素的亮度,取值范围是[0,100],表示从纯黑到纯白
brightness = np.max(l)
feature_ret['brightness'] = brightness / 255.0 + eps
return feature_ret
def image_feature_ex(img):
img_feature_all = OrderedDict()
feature_c = color_feature_ex(img.copy())
feature_t = texture_feature_ex(img.copy())
feature_b = brightness_feature_ex(img.copy())
img_feature_all.update(feature_c)
img_feature_all.update(feature_t)
img_feature_all.update(feature_b)
return img_feature_all
每个图像块提取出来的特征如下所示

其中第一列是图像名,最后一列是标签,1代表有阴影,0代表没有阴影,中间的列则是这个图片的所有特征
svm模型训练
支持向量机(Support Vector Machine,SVM)是一种常用的监督学习算法,在数据分类和回归问题上都有良好的表现。在图像处理和计算机视觉领域中,SVM被广泛应用于图像分割、目标检测、阴影检测等任务中。
SVM算法的基本思想是找到最优的超平面,将不同类别的数据分离开来。在实际应用中,SVM分类器还可以通过引入核函数,将非线性可分的数据映射到高维空间中,从而使得它们可以线性分割。SVM算法的优点是可以得到较高的分类精度,并且在数据维度较高的情况下仍然能够处理。
import os
from image_feature_extract import image_feature_ex
from tqdm import tqdm
import pandas as pd
import numpy as np
import cv2
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
import pickle
from sklearn import svm
from sklearn.metrics import accuracy_score
def model_train(data_root):
key_v = ['color_0', 'color_1', 'color_2', 'color_3', 'color_4', 'color_5', 'color_6', 'color_7',
'color_8', 'lbp_0', 'lbp_1', 'lbp_2', 'lbp_3', 'lbp_4', 'lbp_5', 'lbp_6', 'brightness']
key_l = ['label']
df = pd.read_csv(data_root)
X = df[key_v].values
Y = df[key_l].values
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size = 0.1, random_state=1237)
print('Total {} train {} test {}'.format(len(X), len(X_train), len(X_test)))
#model train
clf = svm.SVC(C=0.8, kernel='rbf', gamma=20, decision_function_shape='ovr')
clf.fit(X_train, y_train.ravel())
#Calculate the accuracy of svc classifier
print("训练集:",clf.score(X_train,y_train))
print("测试集:",clf.score(X_test,y_test))
## save model
s=pickle.dumps(clf)
f=open('svm.model', "wb+")
f.write(s)
f.close()
#model_predict
f2=open('svm.model','rb')
s2=f2.read()
model1=pickle.loads(s2)
predicted = model1.predict(X_test)
acc = accuracy_score(y_test, predicted)
print("test dataset acc ", acc)
在标注的2500条数据上训练svm模型,最终可以得到87.65左右的一个精度

结语
本博客介绍了一种结合传统算法和机器学习算法的阴影检测的技术方案,包括传统的加权中值滤波和Mean Shift算法,以及基于机器学习的图像特征提取和SVM分类器方法。通过最终的效果来看,可以看出这些技术方案都具有一定的优势和适用性,可以根据不同的场景和任务要求来选择使用,但是可能因为标注数据量不够,同时svm这类分类器效果也不够好(其实可以尝试xgb等其他更好的分类器)。
然而,阴影检测仍然是一个具有挑战性的课题,当前存在许多问题有待进一步解决。例如,如何在不同的场景和光照条件下提高阴影检测的准确率和鲁棒性,如何处理复杂场景下的遮挡、反射等问题,如何将阴影检测与目标检测、图像分割等任务结合起来,都是需要进一步探讨和研究的问题。
总之,随着计算机视觉技术的不断发展和应用场景的不断拓展,阴影检测将继续成为一个重要的研究方向和应用领域。我们相信随着学术界和工业界在这个领域的努力与创新,将会有更多更好的技术方案应用于实际场景中,为人类带来更多的实际价值。