目录
1.局部最小值(local minima)与鞍点(saddle point)
1.局部最小值(local minima)与鞍点(saddle point)
当loss无法下降时,可能梯度已经接近0了,这时,局部最小值(local minima)与鞍点(saddle point)都有可能,统称为critical point。

此时,需要判断属于哪种情况,计算Hessian即可:


2.批次(Batch)与动量(momentum)
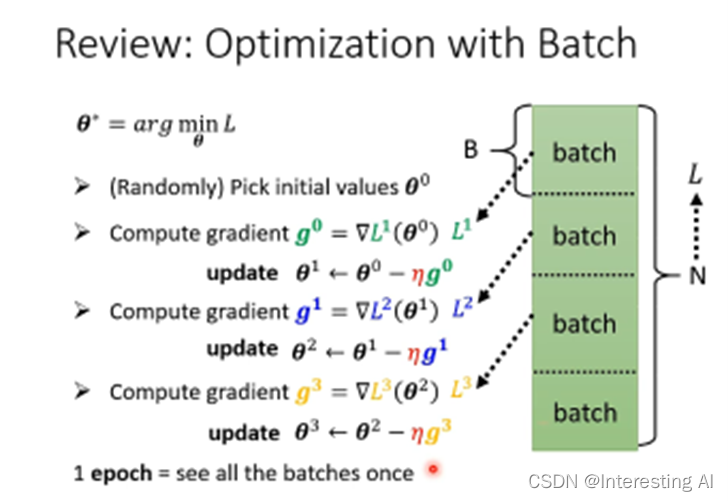

在物理学的角度上,小球走到local minimal,当动量比较大的时候,会越过这个小坡。
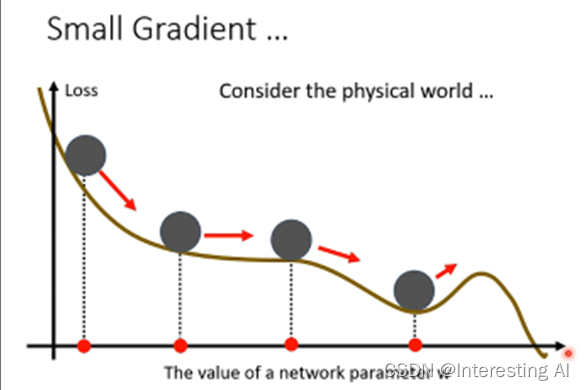
正常的梯度下降,每计算一次梯度,往它的反方向计算一次更新一次参数。

加上动量的梯度下降,可以理解为更新的方向为Gradient的负反方向加上前一次移动的方向。
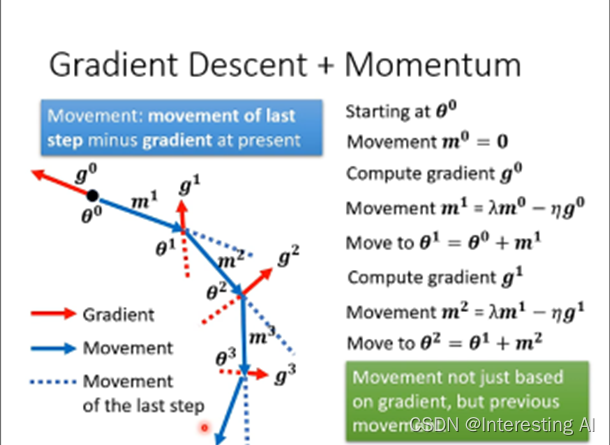
另一种解读是,所谓的momentum,update的方向不是只考虑现在Gradient,而是考虑过去所有Gradient的总和。


3.自动调整学习率(learning rate)
前面在loss不下降的时候,我们说可能是critical point,但是也有可能是下面这种情况:

learning rate应该为每一个参数特制化:
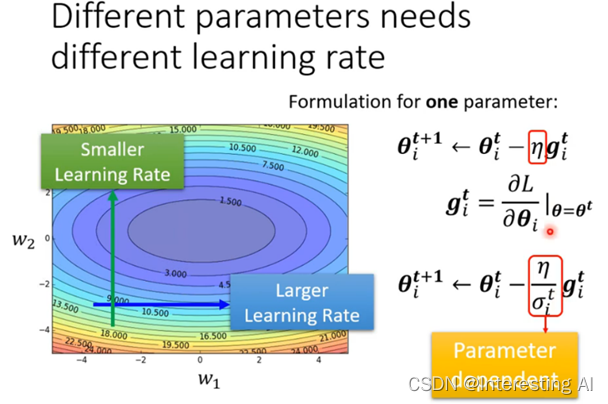
(1)最常见的一种修改学习率的方法是均方根,这种方法被用在Adagrad里面。
(2)可以自己调整现在的gradient的重要性—RMSProp。
(3)Adam: RMSProp + Momentum。
(4)Learning Rate Scheduling,使学习率 η随时间变化。
4.loss损失函数也可能有影响

在分类中,通常会加上softmax:
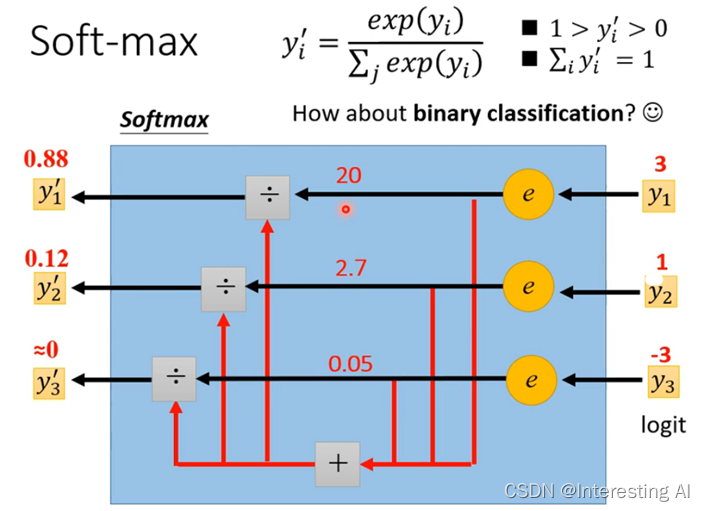
如果是分类成两类,则更常用sigmoid,但其实这两者的方法结果是一样的。下面是损失函数:
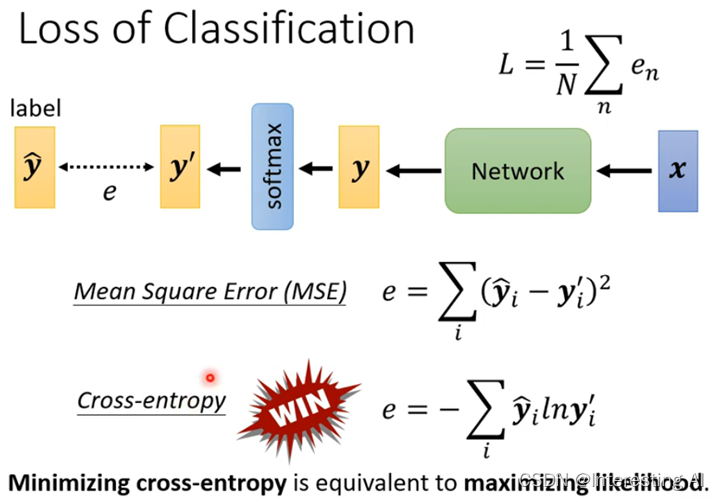
事实上,交叉熵在分类中是最常用的。在PyTorch中,CrossEntropyLoss这个函数已经包含了softmax,这两者是绑定在一起的。从图中可以看出,当 loss 很大时,MSE很平坦,不能梯度下降到 loss 小的地方,卡住了;但是交叉熵可以一路梯度下降下去。

5. 批次标准化(Batch Normalization)
希望对于不同的参数,对 loss 的影响范围都比较均匀,像下面的右图:

方法是特征归一化(Feature Normalization):
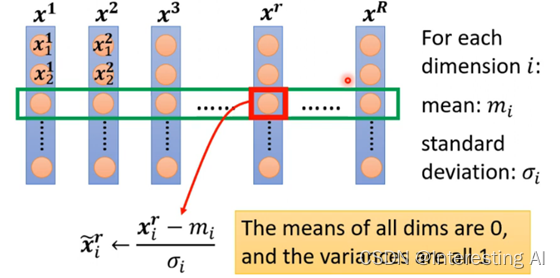
归一化之后,每个维度的特征的平均值为0,方差为1。一般来说,特征归一化使梯度下降收敛更快。后一步的输出同样也需要归一化,这些归一化都是针对于一个Batch的。一些比较有名的Normalization:
