文章目录
优化不合理
现象(梯度很小):
1.模型loss基本不变(梯度消失)
2.模型的loss最后收敛很高(陷入局部最优)
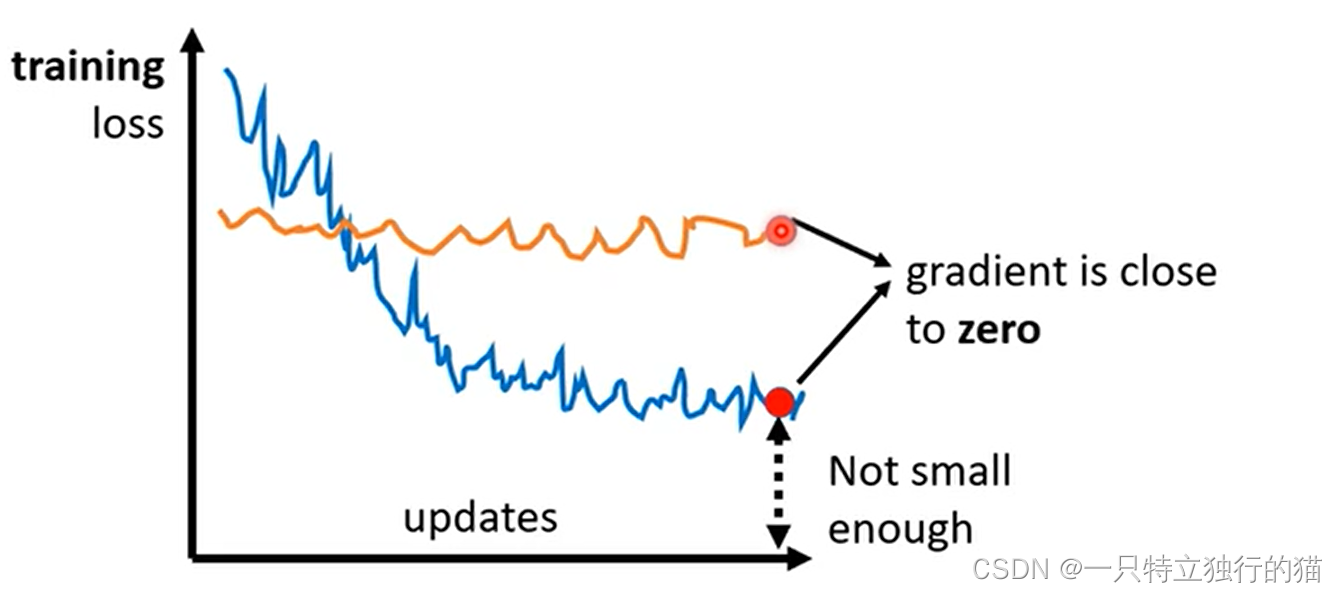
梯度消失原因:
1.陷入鞍点(saddle point)
2.陷入局部极值点(最大值或最小值)
解决方法1(泰勒展开)
判断梯度消失是由哪种原因引起的:
由于机器学习模型的函数特别复杂,为了简化计算,使用hessian矩阵进行近似。
假设对于模型的参数θ,设θ‘=θ+Δθ,在θ处进行泰勒展开,保留前三项,则可以得到下列式子
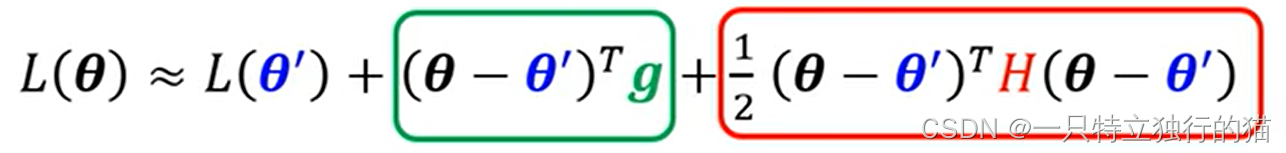 其中,g为L在θ处的梯度,H为Hessian矩阵,计算方法如下:
其中,g为L在θ处的梯度,H为Hessian矩阵,计算方法如下:
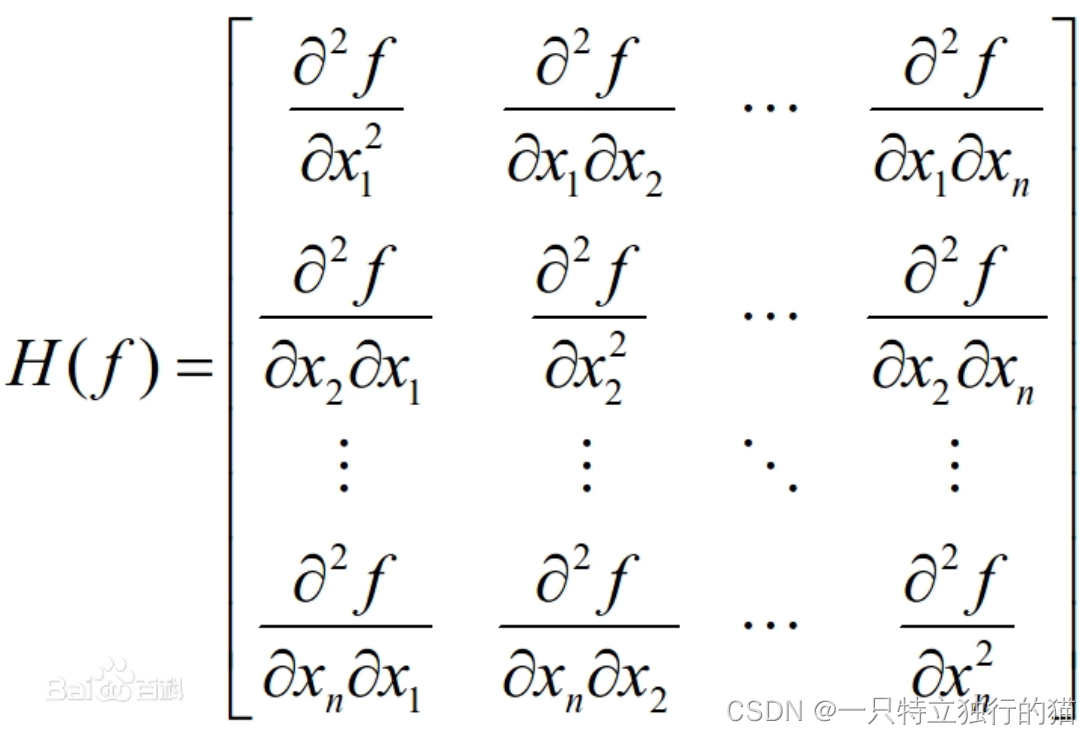 泰勒展开如下:
泰勒展开如下:
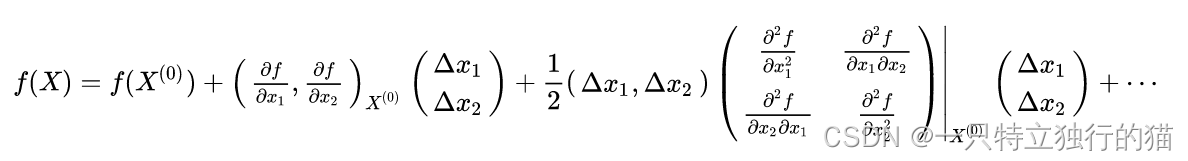 当陷入局部极值点时,g趋向于0,可以忽略不计,则L(θ)和L(θ’)的差异取决于在红色框框柱的式子。
当陷入局部极值点时,g趋向于0,可以忽略不计,则L(θ)和L(θ’)的差异取决于在红色框框柱的式子。
此时就会出现三种情况:
对于所有的θ’
1. 对 于 ∀ θ , ( θ − θ ′ ) T H ( θ − θ ′ ) > 0 , 则 为 局 部 最 小 值 1.对于∀θ,(θ-θ')^TH(θ-θ')>0,则为局部最小值 1.对于∀θ,(θ−θ′)TH(θ−θ′)>0,则为局部最小值
2. 对 于 ∀ θ , ( θ − θ ′ ) T H ( θ − θ ′ ) < 0 , 则 为 局 部 最 大 值 2.对于∀θ,(θ-θ')^TH(θ-θ')<0,则为局部最大值 2.对于∀θ,(θ−θ′)TH(θ−θ′)<0,则为局部最大值
3. 对 于 ∀ θ , ( θ − θ ′ ) T H ( θ − θ ′ ) > 0 或 ( θ − θ ′ ) T H ( θ − θ ′ ) < 0 , 则 为 鞍 点 3.对于∀θ,(θ-θ')^TH(θ-θ')>0 或(θ-θ')^TH(θ-θ')<0,则为鞍点 3.对于∀θ,(θ−θ′)TH(θ−θ′)>0或(θ−θ′)TH(θ−θ′)<0,则为鞍点
但是由于无法穷举所有的θ’,所以需要用到一个数学结论:
eigen value:特征值(下图部分关于最大最小值的判断有误)

推导如下:
可以把(θ-θ’)看成特征向量的集合,即u是特征向量。

这样就将穷举θ转化为了,求负的特征值对应的特征向量,然后根据
θ − θ ′ = u θ-θ'=u θ−θ′=u
得出θ,对θ’进行更新。
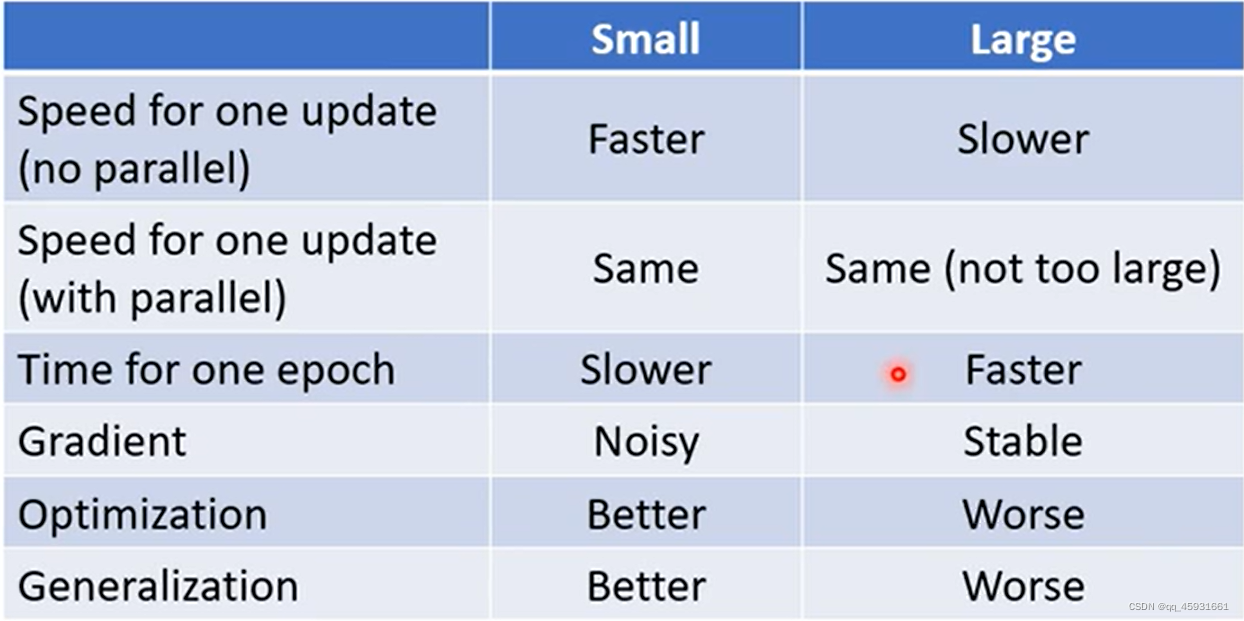
解决方法2(改变batch)
设置batch,这里有两张图
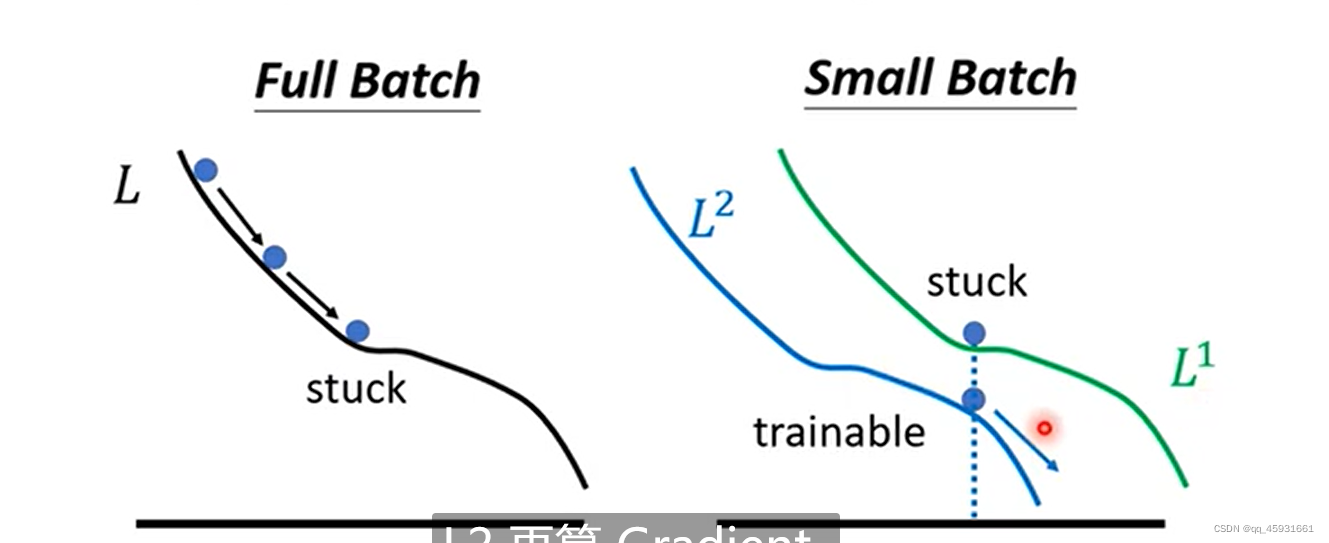 大的batch收敛平稳,训练速度快,但是往往在测试集上表现差;小的batch收敛噪音大,训练速度慢,但是往往在测试集上表现好。
大的batch收敛平稳,训练速度快,但是往往在测试集上表现差;小的batch收敛噪音大,训练速度慢,但是往往在测试集上表现好。
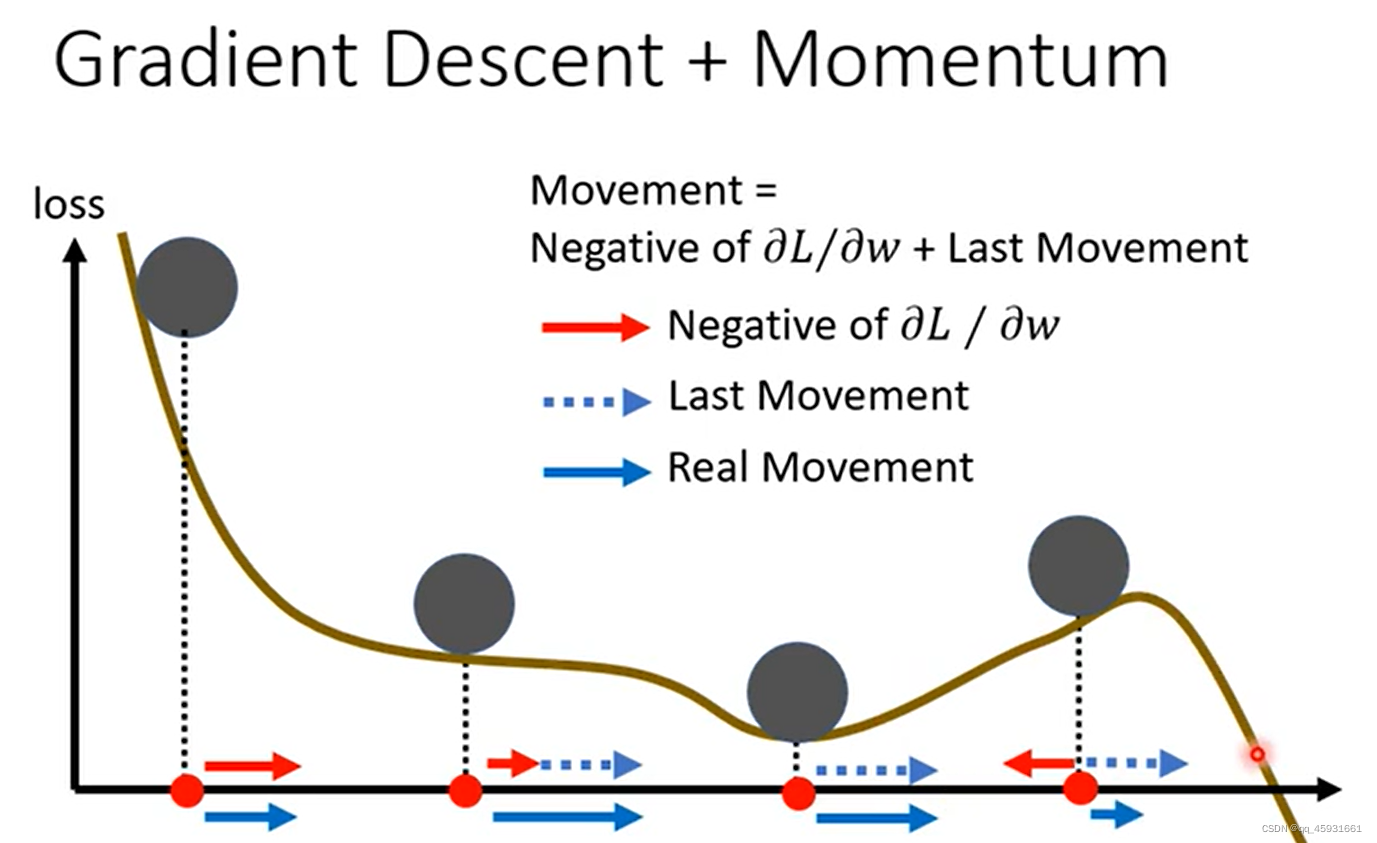
解决方法3(设置momentum)
momentum(动量)
考虑物理世界中,如果一个小球从高处沿着斜坡滑下,当他遇到局部最低点的时候,由于具有动量(惯性),他会继续往前冲一段路,试图越过前一个坡。
改进梯度下降方式:
m o m e n t u m n + 1 = λ ∗ m o m e n t u m n − η ∗ G r a d i e n t n momentum^{n+1}=λ*momentum^n-η*Gradient^n momentumn+1=λ∗momentumn−η∗Gradientn
θ n + 1 = θ n + m o m e n t u m n + 1 θ^{n+1}=θ^n+momentum^{n+1} θn+1=θn+momentumn+1
(我感觉有点赌,动量的前提是认为翻过这个山能实现更好的效果,但是实际上不一定,可能翻过这个山反而效果反而差)
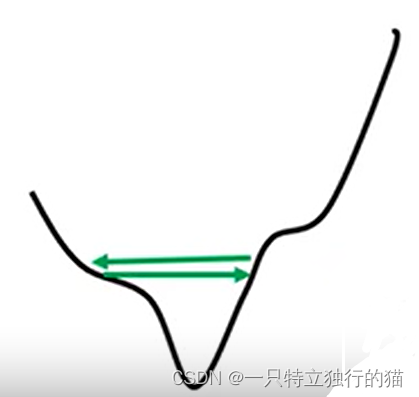
模型震荡
现象:
1.loss不变,但gradient仍很大
解决办法1(Adagrad方法)
当训练含有两个参数的模型时,如果学习率太大,则会反复震荡,如果学习率太小,则在后期训练缓慢。
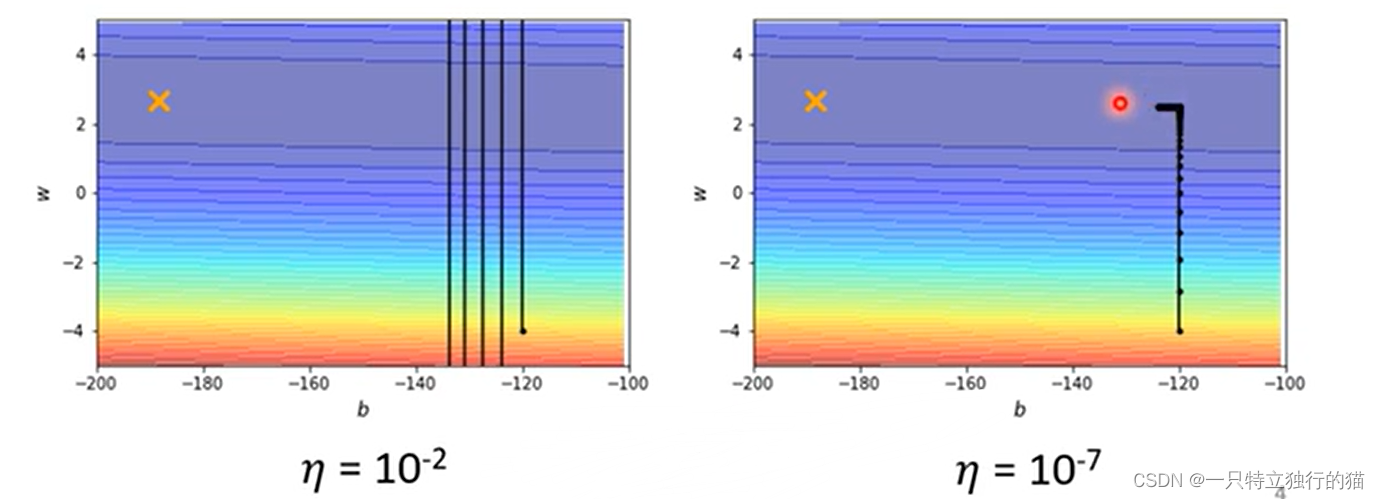
所以需要根据gradient来自适应学习率,当gradient大的时候,学习率应该小,gradient小的时候,学习率应该大。
学习率应该更新如下图红框所示:

t表示epoch的次数,i表示为哪一个参数。第t个epoch的σ计算如下:
σ i t = 1 t + 1 ∑ 1 ≤ t ≤ n g ( i t ) 2 σ^t_i=\sqrt{\frac{1}{t+1}\sum_{\mathclap{1\le t\le n}} g(^t_i)^2} σit=t+111≤t≤n∑g(it)2
上述算法在Adagrad优化技术中用到。
但是上述方法的缺陷是:把每一个梯度视为同等重要,所以可能后期调整速度较慢。
解决办法2(RMSProp方法)
计算公式同上,红框中第t个epoch的σ计算方式变化为:
σ i t = α ( σ i t − 1 ) 2 + ( 1 − α ) ( g i t ) 2 σ^t_i=\sqrt{α(σ^{t-1}_i)^2+(1-α)(g^t_i)^2} σit=α(σit−1)2+(1−α)(git)2
将不同时间段产生的梯度考虑给予不同的权值,越早产生的gradient的权值越低,可以提高学习率的调整速度。
解决办法3:(Adam)
Adam=RMSProp+Momentum
相当于参数更新函数变为如下所示:
σ i t = α ( σ t − 1 ) 2 + ( 1 − α ) ( g t ) 2 σ^t_i=\sqrt{α(σ^{t-1})^2+(1-α)(g^t)^2} σit=α(σt−1)2+(1−α)(gt)2
m o m e n t u m n + 1 = λ ∗ m o m e n t u m n − η σ n ∗ G r a d i e n t n momentum^{n+1}=λ*momentum^n-\frac {η}{σ^n}*Gradient^n momentumn+1=λ∗momentumn−σnη∗Gradientn
θ n + 1 = θ n + m o m e n t u m n + 1 θ^{n+1}=θ^n+momentum^{n+1} θn+1=θn+momentumn+1
简单理解的话,相当于在梯度更新速度上加了一个权值,并且在梯度更新方向上加了一个权值。
优化训练损失函数
如果在分类问题中,使用MES和交叉熵损失函数,则使用MSE时,会因为MSE在分类问题的求导时,求导项含有梯度分之一,所以在梯度很大时,MES对于分类问题train不起来。
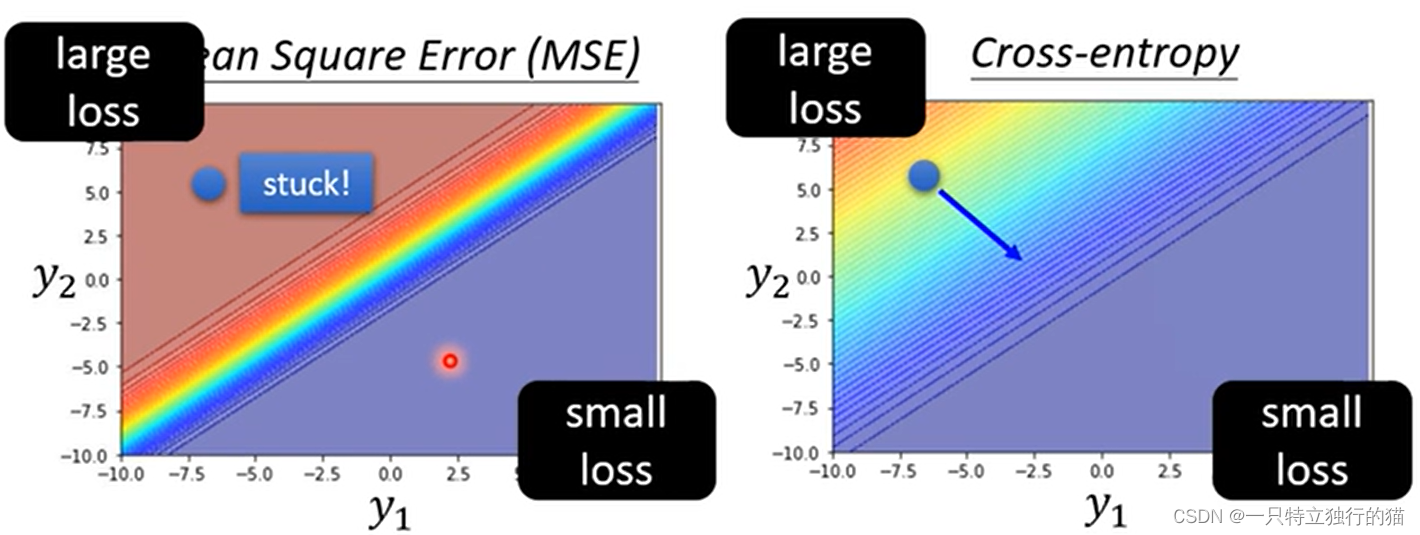 注:pytorch中,cross函数默认会加上softmax,所以不需要在网络的最后一层加上softmax。
注:pytorch中,cross函数默认会加上softmax,所以不需要在网络的最后一层加上softmax。
