上一篇博客写了基于线性探测实现哈希表的一些方法,但若是负载因子较大时,哈希表的查找数据效率还是会很低,下面将使用开散列来实现哈希表的一些操作
开散列
又称为链地址法(开链法)
首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个集合称为一个桶,桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中
例如:数据集合{10,51,14,33,18,29},哈希函数Hash(key) = key%m(m为内存单元的个数,可以自定义),在这里定义为10
Hash(10)=0 Hash(51)= 1 Hash(14)=4 Hash(33)=3 Hash(18)=8 Hash(29)=9
Hash(21)=1 Hash(23)=3
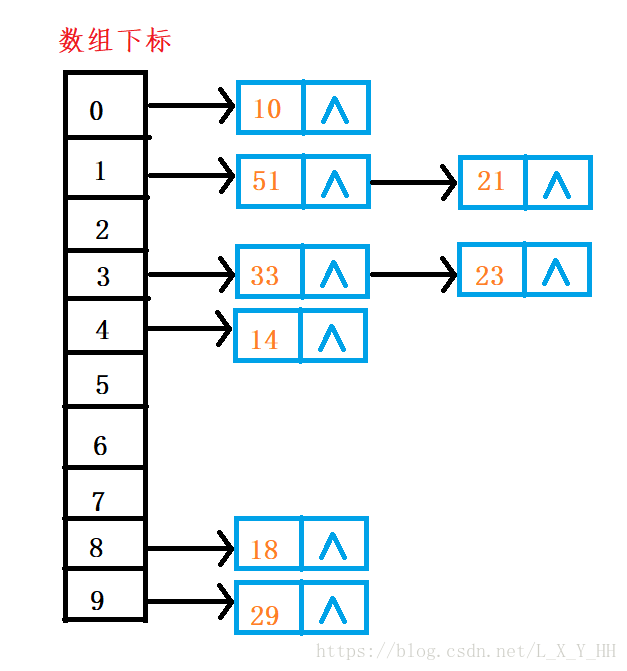
哈希表的结构
哈希表有数组构成,数组中的元素为哈希表元素的指针,哈希表中的元素由一个键值对和指向下一个哈希表元素的指针构成,还要哈希表中元素的个数,还有指定哈希表的下标是由哪个哈希函数计算得来的
3 #define HashMaxSize 1000
4 typedef int KeyType;
5 typedef int ValueType;
6 typedef size_t (*HashFunc)(KeyType key);
7
8 typedef enum
9 {
10 Empty,//空状态
11 Valid,//有效状态
12 Delete,//被删改的状态
13 }Stat;
14
15 typedef struct HashElem
16 {
17 KeyType key;
18 ValueType value;
19 struct HashElem* next;
20 }HashElem;
21
22 typedef struct HashTable
23 {
24 HashElem* data[HashMaxSize];
25 size_t size;
26 HashFunc func;
27 }HashTable;
28
1.哈希表的初始化操作
将哈希表中的元素个数置为0,由于数组元素代表的是由相同下标的哈希表元素构成的单链表,因为单链表有带头节点和不带头结点之分,在本方法中,单链表一律采用不带头结点的单链表,即数组元素为链表的头指针,因此初始化操作,要将单链表的头结点置为NULL
27 void HashInit(HashTable* hashtable,HashFunc hash_func)
28 {
29 if(hashtable == NULL)
30 {
31 //非法操作
32 return ;
33 }
34 hashtable->size = 0;
35 hashtable->func = hash_func;
36 size_t i = 0;
37 for(;i < HashMaxSize ; ++i)
38 {
39 hashtable->data[i] = NULL;
40 }
41 return ;
42 }
2.哈希表的销毁操作
将哈希表中的元素个数置为0,并且要遍历链表中的节点,并释放内存
44 void HashDestroy(HashTable* hashtable)
45 {
46 if(hashtable == NULL)
47 {
48 return ;
49 }
50 hashtable->size = 0;
51 hashtable->func = NULL;
52 //遍历所有链表进行释放内存
53 size_t i = 0;
54 for(;i < HashMaxSize ; ++i)
55 {
56 HashElem* cur = hashtable->data[i];
57 while(cur != NULL)
58 {
59 HashElem* next = cur->next;
60 DestroyElem(cur);
61 }
62 cur = cur->next;
63 }
64 return ;
65 }
22 void DestroyElem(HashElem* cur)
23 {
24 free(cur);
25 }
26
3.哈希表的插入操作
(1)根据要插入的key值计算出要插入的位置offset,
(2)在offset对应的链表中查看当前的key是否存在
a)若存在,就认为插入失败
b)若不存在,就要创建新的节点,并采用头插法进行插入操作(此处使用头插法仅仅为了操作方便),同时将哈希表的元素个数加1
80 void HashInsert(HashTable* hashtable,KeyType key,ValueType value)
81 {
82 if(hashtable == NULL)
83 {
84 return ;
85 }
86 //1.根据key计算出offset
87 size_t offset = hashtable->func(key);
88 //2.在offset对应的链表中查找看当前的key是否存在,若存在就认为插入失败
89 HashElem* ret = HashBackedFind(hashtable->data[offset],key);
90 if(ret = NULL)
91 {
92 //找到了,说明找到了重复key的值,认为插入失败
93 return ;
94 }
95 //3.若不存在就可以插入,使用头插法
96 HashElem* new_node = CreateElem(key,value);
97 //头插法
98 new_node->next = hashtable->data[offset];
99 hashtable->data[offset] = new_node;
100 //4.++size
101 ++hashtable->size;
102 return;
103 }
下面为在链表中查找元素key是否存在的函数HashBackedFind
67 HashElem* HashBackedFind(HashElem* head,KeyType to_find)
68 {
69 HashElem* cur = head;
70 for(;cur != NULL ;cur = cur->next)
71 {
72 if(cur->key == to_find)
73 {
74 return cur ;
75 }
76 }
77 return NULL;
78 }
下面为创建新节点的函数CreateElem
12 HashElem* CreateElem(KeyType key,ValueType value)
13 {
14 HashElem* new_node = (HashElem*)malloc(sizeof(HashElem));
15 new_node->key = key;
16 new_node->value = value;
17 new_node->next = NULL;
18 return new_node;
19
20 }
4.哈希表的查找操作
(1)先对哈希表及查找内容进行合法性判断
(2)根据key值来计算出offset
(3)找到对应的offset链表,遍历链表,尝试寻找元素,方法同上面的方法
105 int HashFind(HashTable* hashtable,KeyType key,ValueType* value)
106 {
107 if(hashtable == NULL || value == NULL)
108 {
109 return 0;
110 }
111 //1.根据key计算出offset
112 size_t offset = hashtable->func(key);
113 //2.找到对应的offset的链表,遍历链表,尝试找到其中的元素
114 HashElem* ret = HashBackedFind(hashtable->data[offset],key);
115 if(ret == NULL)
116 {
117 return 0;
118 }
119 *value = ret->value;
120 return 1;
121 }
122
5.哈希表的删除操作
(1)首先先对哈希表做合法性判断
(2)根据给定的key值计算出对应的下标offset
(3)通过offset找到对应的链表,在链表中找到指定的元素
a)若没找到,直接返回空
b)若找到了,判断找到的节点的前一个节点是否为NULL,若为NULL,说明要删除的节点为头结点,将头结点的指针指向下一个节点
c)若找到了,且要删除的元素的前一个节点部位NULL,说明要删除的节点不是头结点,直接将删除元素的前一个节点的下一个指向要删除节点的下一个元素
143 void HashRemove(HashTable* hashtable,KeyType key)
144 {
145 if(hashtable == NULL)
146 {
147 return ;
148 }
149 if(hashtable->size == 0)
150 {
151 return ;
152 }
153 //1.根据key计算出offset
154 size_t offset = hashtable->func(key);
155 HashElem* pre = NULL;
156 HashElem* cur = NULL;
157 //2.通过 offset 找到对应的链表,在链表中找到指定的元素并进行删除
158 int ret = HashBackedFindEx(hashtable->data[offset],key,&pre,&cur);
159 if(cur == 0)
160 {
161 //没找到,删除失败
162 return ;
163 }
164 if(pre == NULL)
165 {
166 //要删除的元素为链表的头节点
167 hashtable->data[offset] = cur->next;
168 }
169 else
170 {
171 //不是头节点
172 pre->next = cur->next;
173 }
174 DestroyElem(cur);
175 //--size
176 --hashtable->size;
177 return ;
178 }
179
下面是实现在链表中查找要删除的元素的函数HashBackedFindEX
123 int HashBackedFindEx(HashElem* head,KeyType to_find,HashElem** pre_node,HashElem** cur_node)
124 {
125 HashElem* cur = head;
126 HashElem* pre = NULL;
127 for(;cur != NULL;pre = cur,cur = cur->next)
128 {
129 if(cur->key == to_find)
130 {
131 break;
132 }
133 }
134 if(cur == NULL)
135 {
136 return 0;
137 }
138 *pre_node = pre;
139 *cur_node = cur;
140 return 1;
141 }