冲突-解决-开散列/哈希桶
- 开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。
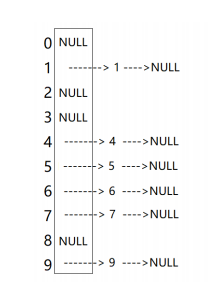
从上图可以看出,开散列中每个桶中放的都是发生哈希冲突的元素。
冲突严重时的解决办法
- 刚才我们提到了,哈希桶其实可以看作将大集合的搜索问题转化为小集合的搜索问题了,那如果冲突严重,就意味着小集合的搜索性能其实也时不佳的,这个时候我们就可以将这个所谓的小集合搜索问题继续进行转化,例如:
- 每个桶的背后是另一个哈希表
- 每个桶的背后是一棵搜索树
- 进行扩容
- 可以降低负载因子,有效降低哈希冲突
- 实现简单,但是成本较高
增加:
- 根据哈希函数得到下标,在数组中找到这个下标的数据,进行判断,若为空,直接插入,若不为空,先判断是否已有key若有直接覆盖value,若没有进行链表头插法。
哈希函数(除留余数法):
private int hashFunc(int key) {
return key % this.array.length;
}
实现增加:
//增加
public void put(int key, int value) {
//首先获取根据哈希函数得到下标
int index = hashFunc(key);
//判断此时有没有这个key如果有就覆盖value
Node head = this.array[index];
if(head == null) {
this.array[index] = new Node(key, value);
this.size++;
if(( (double)this.size / this.array.length ) >= LOAD_FACTOR) {
//进行扩容
resize();
}
return;
}
while (head != null) {
if(head.key == key) {
head.value = value;
return;
}
head = head.next;
}
//此时说明数组里没有key,我们进行头插这个key的结点
head = this.array[index];
Node newHead = new Node(key, value);
newHead.next = head;
this.array[index] = newHead;
this.size ++;
if(( (double)this.size / this.array.length ) >= LOAD_FACTOR) {
//进行扩容
resize();
}
}
扩容:
- 当哈希因子达到0.75此时哈希冲突发生概率就会很大,所以我采用的是利用扩容的方式降低哈希因子
思想:遍历原有数组,将所有数据 根据哈希函数放的新的数组当中。
实现:
private void resize() {
Node[] newArray = new Node[this.array.length * 2];
//遍历原有数据放到新的数组当中
for (Node node : this.array) {
Node next;
for (Node cur = node; cur != null; cur = next) {
next = cur.next;
cur.next = null;
//根据哈希函数得到下标,放到新的数组中
int index = cur.key % newArray.length;
if (newArray[index] != null) {
//头插
cur.next = newArray[index];
}
newArray[index] = cur;
}
}
this.array = newArray;
}
查找:
- 根据哈希函数得到下标,然后进行链表查找
实现:
//查找
public Node get(int key) {
//通过哈希函数得到下标
int index = hashFunc(key);
//遍历cur这个链表找key
for (Node cur = this.array[index]; cur != null; cur = cur.next) {
if(cur.key == key) {
return cur;
}
}
return null;
}
删除:
- 根据哈希函数得到下标,然后进行链表的删除操作
实现:
//删除
public void remove(int key) {
//通过哈希函数得到下标
int index = hashFunc(key);
//如果头结点为空
if(this.array[index] == null) {
return;
}
//如果头结点就是key
if(this.array[index].key == key) {
this.array[index] = this.array[index].next;
this.size--;
return;
}
//进行链表删除
Node parent = this.array[index];
Node find = parent.next;
while (find != null) {
if(find.key == key) {
parent.next = find.next;
this.size--;
return;
}
parent = find;
find = find.next;
}
}
性能分析:
- 虽然哈希表一直在和冲突做斗争,但在实际使用过程中,我们认为哈希表的冲突率是不高的,冲突个数是可控的,也就是每个桶中的链表的长度是一个常数,所以,通常意义下,我们认为哈希表的插入/删除/查找时间复杂度是O(1) 。
和java类集的关系
- HashMap 和 HashSet 即 java 中利用哈希表实现的 Map 和 Set
- java 中使用的是哈希桶方式解决冲突的
- java 会在冲突链表长度大于一定阈值后,将链表转变为搜索树(红黑树)
- java 中计算哈希值实际上是调用的类的 hashCode 方法,进行 key 的相等性比较是调用 key 的 equals 方法。所以如果要用自定义类作为 HashMap 的 key 或者 HashSet 的值,必须覆写 hashCode 和 equals 方 法,而且要做到 equals 相等的对象,hashCode 一定是一致的。