文章目录
1.Kafka消息数据存储概念
生产者发送消息数据,存储在Kafka消息队列的Topic中,Topic属于逻辑概念,消息数据最终是存储在指定的数据存储路径,因此就有了两种数据消费方式,从偏移量+1处消费数据和从第一条数据开始消费,这两种消费方式其实都读取的硬盘中的数据文件。
在Kafka的数据存储目录中可以看到有很多offsets目录,offsets目录就是指的偏移量,在数据存储目录中,每一个Topic主题都有一个独立的目录存储其中的消息数据。

在Topic的数据目录中,有消息索引文件、消息时间索引文件、消息数据文件,其中00000000000000000000.log这个文件就是存放消息数据的文件。

2.消息的偏移量概念原理
偏移量+1消费数据指的是不消费旧数据,仅对新消息数据进行消费。
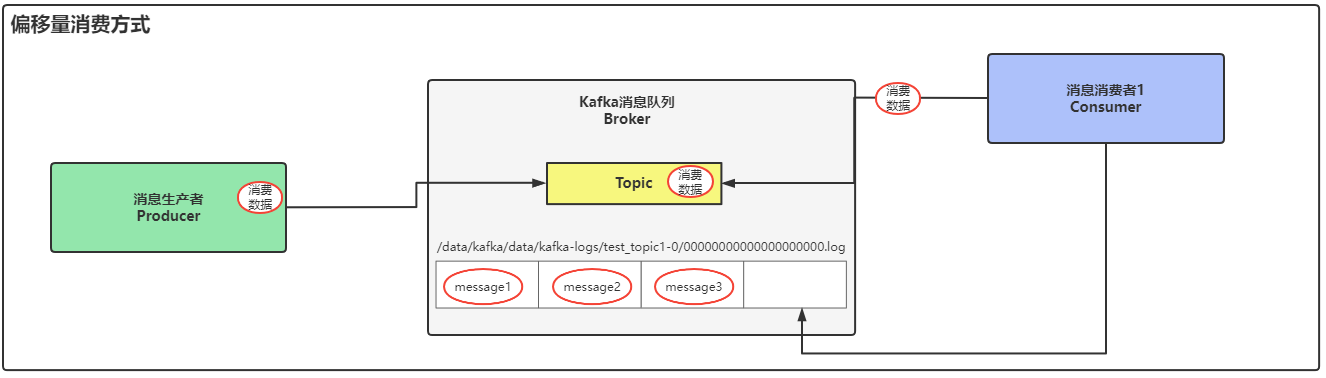
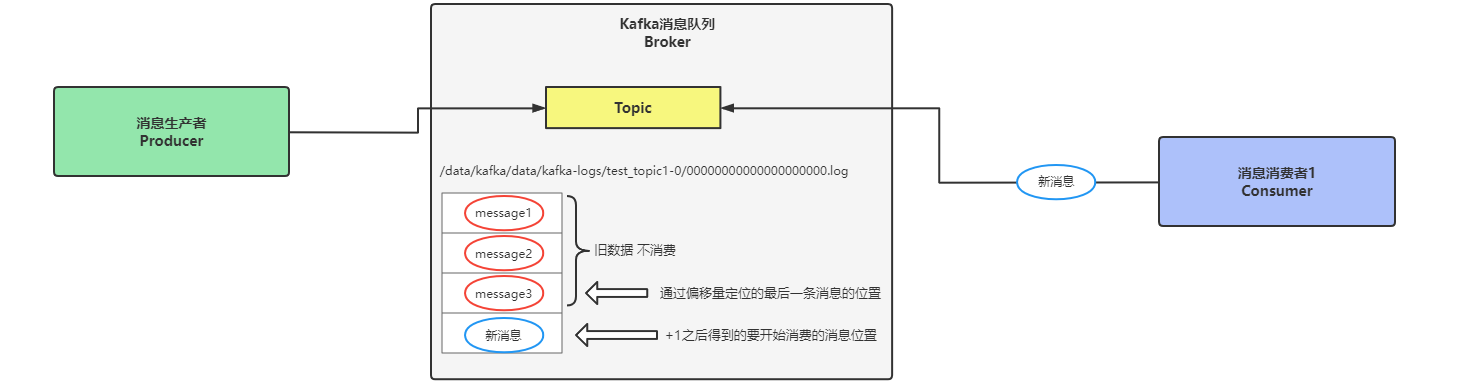
生产者将数据写入到Kafka的Topic中,Topic是逻辑层面的概念,消息数据最终会写入到Topic存储目录的00000000000000000000.log这个数据文件中,消费者在消费数据时,读取的就是这个数据文件,默认的消费方式是从偏移量+1处获取消息然后进行消费,这个偏移量可以理解为是数据文件中的最后一条消息,消费者根据偏移量定位到消息的位置,然后再加一条消息数据的位置,如下图中所示,在表格中已经有3条消息数据,消费者通过偏移量定位到messages3(最后一条数据),但是这只是第一个条件,第二个条件是在偏移量位置处+1条数据,最终消费者要开始消费的数据就是第四条消息内容。
偏移量+1就是从最后一条消息"后"开始消费数据。
通俗一点理解就是旧数据消费者不会去消费,当消费者开启后,只有当新的消息数据写入Topic时,才会被消费者读取到并进行消费。

消费者消费这种偏移量数据时,是通过offset来找到要消费的数据的位置。
 通过下图将会更容易理解偏移量+1处消费数据的原理和概念:
通过下图将会更容易理解偏移量+1处消费数据的原理和概念:
数据文件中message1-3这三条数据都是旧数据,通过偏移量定位到数据文件中的最后一条消息数据message3,然后在+1条消息,定位到数据文件中的第四条消息位置,从这个位置处开始被消费者消费,从第四条开始之后的数据都会被消费者进行消费。
3.消息数据的顺序消费概念原理
顺序消费指的就是从Topic中第一条消息数据开始消费。
在上面说明偏移量消费概念时,我们已经知道在Kafka中,每一条消息数据都会存储在数据文件中,在这个数据文件中每一条消息数据都是有顺序概念的,也就是会按照消息数据的先后写入顺序依次写入到数据文件中,消息是被持久化到数据文件的,因此我们就可以根据消息数据的顺序性,实现通过顺序来消费消息数据。
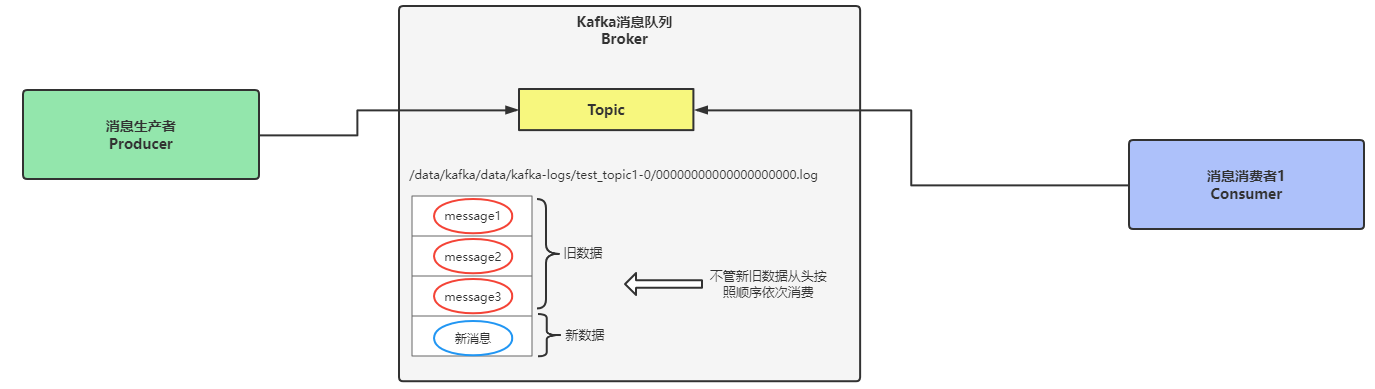
通过顺序来消费消息数据就是从Topic中第一条消息开始消费,不管是不是旧数据,也不管是不是曾经被消费过,忽略这些特点,依旧从第一条消息数据处开始消费。
消息数据写入到数据文件默认都是有序的,都是通过offset偏移量来描述消息的有序性。
如下图所示:消费者消费数据时,会从数据文件00000000000000000000.log中的第一条消息数据开始消费,一条一条按照顺序进行消费。
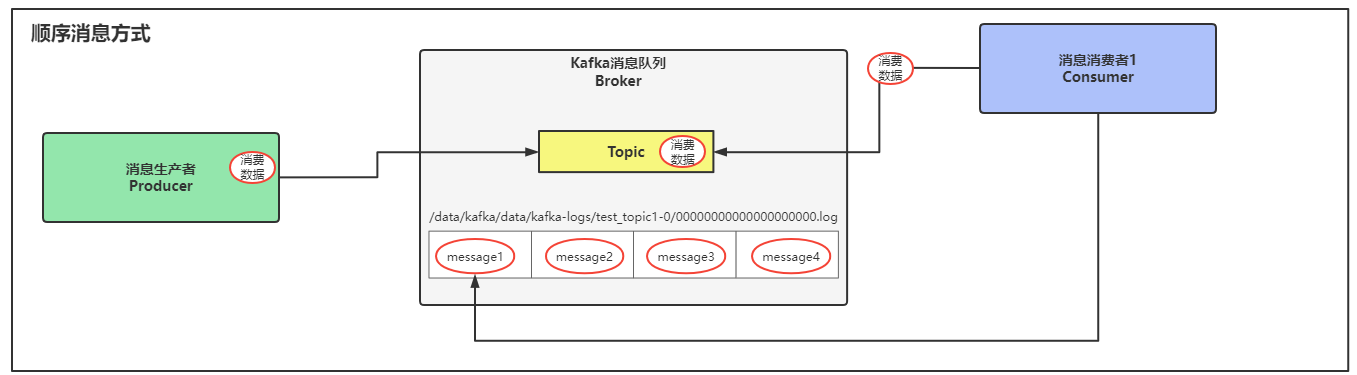 顺序消费最重要的概念就是无论新老数据,都从第一条消息数据处开始消费。
顺序消费最重要的概念就是无论新老数据,都从第一条消息数据处开始消费。
4.消息单播消费概念及实现
4.1.单播消费概念
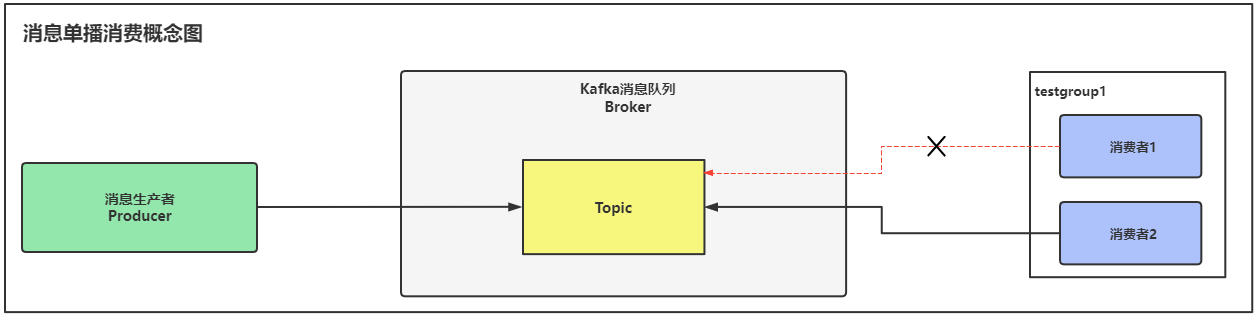
消息数据单播消费指的是:一个消费组中只有一个消费者能对Topic中的消息数据进行消费。
如下图所示生产者将消息数据写入到Topic中,消费者是一个消费者组testgroup1,在这消费者组里,只能有一个消费者去消费Topic中的消息数据,一般来说,会由最新启动的消费者去消费Topic里的数据,但是也存在由之前启动的消费者来消费数据的情况,总而言之不管是哪一个消费者,一个消费者组中只能有一个消费者去消费数据。
4.2.单播消费实现
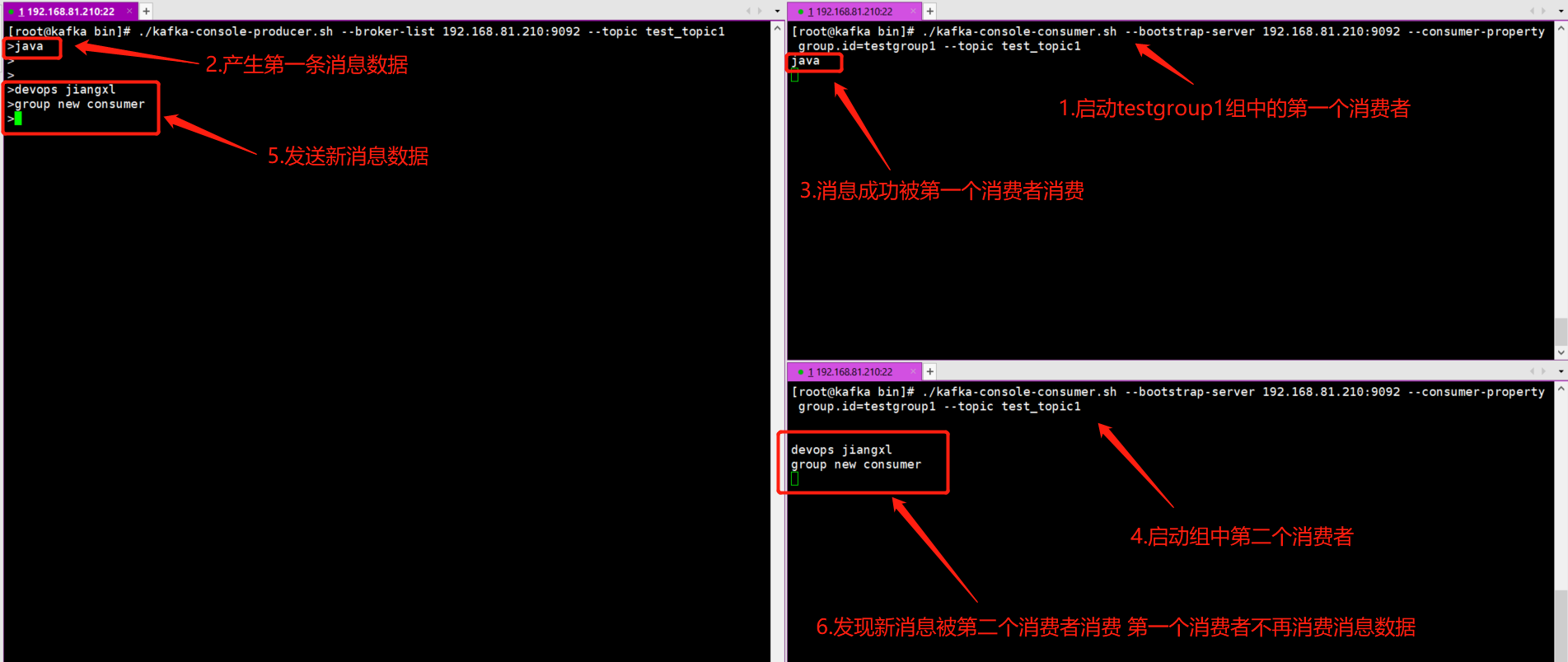
为了验证上述理论,我们可以启动两个同为一组的消费者,观察最终谁会去消费数据,理论上来说只有其中某一个消费者会去消费数据。
1)在testgroup1组中启动第一个消费者客户端
[root@kafka bin]# ./kafka-console-consumer.sh --bootstrap-server 192.168.81.210:9092 --consumer-property group.id=testgroup1 --topic test_topic1
2)启动生产者生产消息数据第一条消息
[root@kafka bin]# ./kafka-console-producer.sh --broker-list 192.168.81.210:9092 --topic test_topic1
>java
3)第一个消费者成功消费数据
[root@kafka bin]# ./kafka-console-consumer.sh --bootstrap-server 192.168.81.210:9092 --consumer-property group.id=testgroup1 --topic test_topic1
java
4)在testgroup1组中启动第二个消费者客户端
[root@kafka bin]# ./kafka-console-consumer.sh --bootstrap-server 192.168.81.210:9092 --consumer-property group.id=testgroup1 --topic test_topic1
5)发送者发送新消息数据
[root@kafka bin]# ./kafka-console-producer.sh --broker-list 192.168.81.210:9092 --topic test_topic1
>java
>
>
>devops jiangxl
>group new consumer
6)观察消费者的接收情况
此时就会发现第一个消费者不会再去消费数据了,而是有第二个消费者去Topic中消费数据,由新启动的消费者消费数据。
[root@kafka bin]# ./kafka-console-consumer.sh --bootstrap-server 192.168.81.210:9092 --consumer-property group.id=testgroup1 --topic test_topic1
devops jiangxl
group new consumer
5.消息多播消费概念以及实现
5.1.多播消费概念
消息数据多播消费指的是:允许多个消费者组同时对一个Topic中的数据进行消费,但是一个消费者组中也是只有1个消费者在消费消息数据。
多播和单播的区别在于,单播是一个消费者组,多播是多个消费者组同时消费数据,一条消息数据会被两个消费者组进行消费。
如下图所示:两组消费者会同时对Topic中的消息数据进行消费,一个消费者组中会由某一个消费者去消费数据
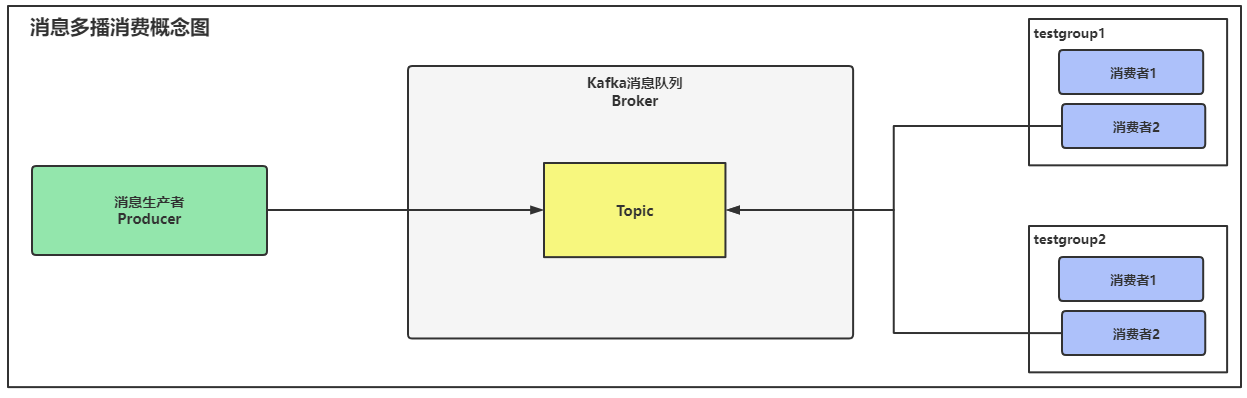
多播消费常应用于需要同时被多个消费者消费的场景。
5.2.多播消费实现
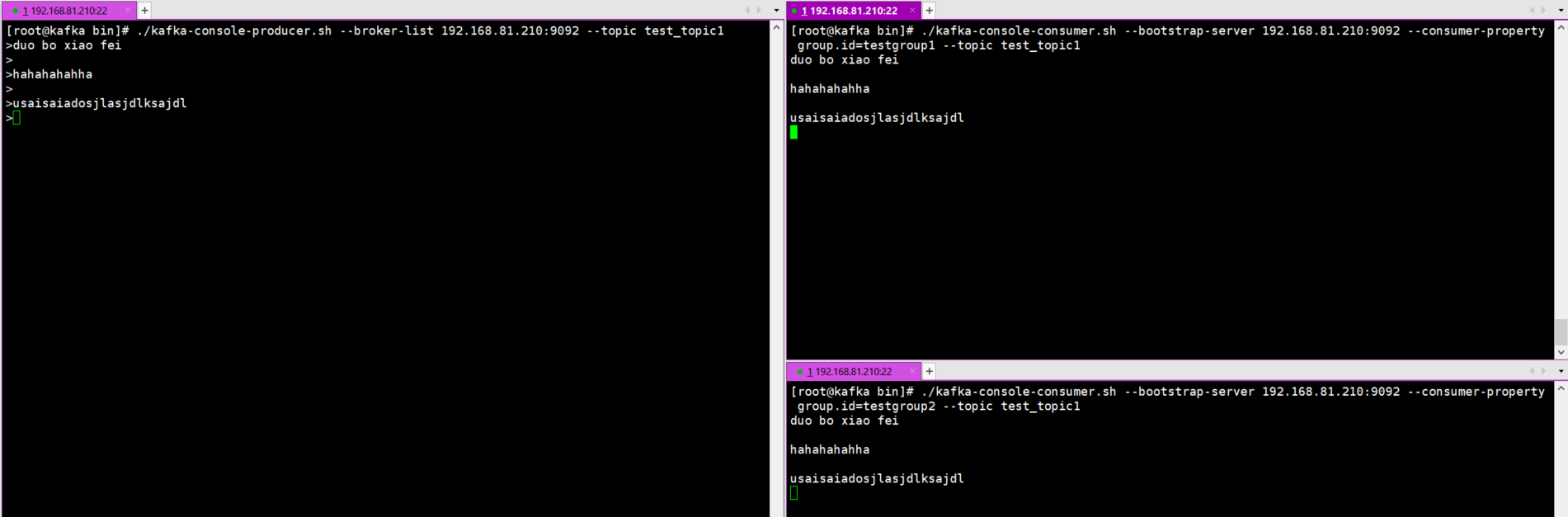
1.先启动两组消费者
[root@kafka bin]# ./kafka-console-consumer.sh --bootstrap-server 192.168.81.210:9092 --consumer-property group.id=testgroup1 --topic test_topic1
[root@kafka bin]# ./kafka-console-consumer.sh --bootstrap-server 192.168.81.210:9092 --consumer-property group.id=testgroup2 --topic test_topic1
2.发送者产生消息数据
[root@kafka bin]# ./kafka-console-producer.sh --broker-list 192.168.81.210:9092 --topic test_topic1
>duo bo xiao fei
>
>hahahahahha
>
>usaisaiadosjlasjdlksajdl
3.观察数据消费情况
如下图所示,消息数据会被两组消费者同时消费。
6.查看消费组以及详细信息
在单播和多播中使用了消费组的概念,我们可以通过命令查询消费者的信息。
1.查看系统中有哪些消费组
[root@kafka bin]# ./kafka-consumer-groups.sh --bootstrap-server 192.168.81.210:9092 --list
testgroup1
testgroup2
2.查看消费组的详细信息
[root@kafka bin]# ./kafka-consumer-groups.sh --bootstrap-server 192.168.81.210:9092 --describe --group testgroup1
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
testgroup1 test_topic1 0 63 79 16 consumer-testgroup1-1-b329b404-a901-4ab9-8485-6f2915719187 /192.168.81.210 consumer-testgroup1-1
#字段说明
GROUP:消费组的名称
TOPIC:当前消费组消费的Topic信息
PARTITION:Topic的分区号
CURRENT-OFFSET:当前消费组消费到的偏移量位置,也就是上次消费者消费的最后一条数据的位置,值为69,也就是上次消费到了第69条数据
LOG-END-OFFSET:Topic中当前分区的结束偏移量位置,可以理解为Topic中最后一条消息数据是第多少条,也可以理解为是Topic中消息的总条数
LAG:当前消费组没有消费的数据条目,也就是LOG-END-OFFSET值减CURRENT-OFFSET值得出的结果
CONSUMER-ID:消费者组的ID号
HOST:kafka节点地址
CLIENT-ID:消费组中的消费者ID号

7.Kafka中Topic主题和分区的概念
7.1.Topic主题概念
Topic主题在Kafka中是一个逻辑的概念,Kafka将不同应用程序的消息进行分类,分别存储在不同的Topic中,不同的Topic会被订阅该Topic的消费者所消费。
视图Topic面临着一个问题,如果这个Topic中写入的消息数据非常多,可能达到几百G甚至几T的空间存储,Topic中的消息数据都是持久化到本地数据文件的,当量级很大时,不管是消费者还是发送者都会遇到性能瓶颈。
为了解决消息量过大导致性能出现影响的问题,Kafka对Topic设计出了分区的概念。
7.2.Topic中Partition分区概念
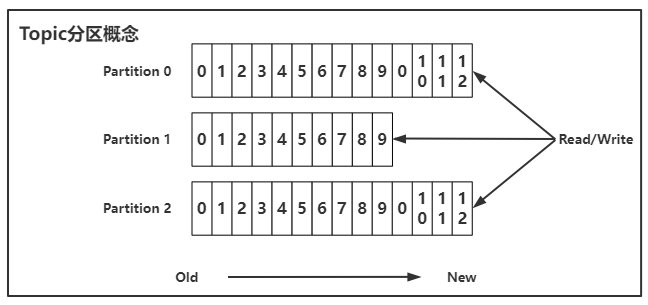
Kafka的Topic可以将消息数据分区进行存储,如下图所示,可以将一个Topic分为三个分区0/1/2,当有多个发送者发送消息数据时,可以同时向三个分区写入消息数据,消费者读取数据时,也可以同时对三个分区进行读取消费。
在没有使用Partition分区之前,100条消息数据会存储在一个Topic中,然后持久化到一个本地数据文件里,当使用了Partition分区之后,100条消息数据会按没分区30条进行分布式存储,持久化到不同的数据文件里。
分区从0开始分配,第一个分区是xxx-0 第二个分区是xxx-1 第三个分区是xxx-2。
Topic将消息数据分区存放的好处:
- 当业务高并发时,可以避免Topic持久化到本地的数据文件过大的问题,Partition分区从逻辑上将Topic进行拆分,把消息数据分别持久化到不同的数据文件中,不管时读还是写都比集中在一起要强。
- 发送者和消费者都可以同时对一个Topic的三个分区或多个进行读写操作,原来情况下发送者和消费者都是一条条数据往Topic中写入和读取,使用Partition分区之后,将Topic进行拆分,分为几个部分,消费者和发送者可以同时对这几个分区来读取和写入数据。
- 原来消息的读取和写入只有一个入口,使用Partition后,相当于将一个入口分出了出多个入口,读取和写入数据都不需要一条条进行,从而提高了发送者和消费者的吞吐量。
7.3.创建多分区的Topic
1.创建多分区类型的Topic
[root@kafka bin]#./kafka-topics.sh --create --zookeeper 192.168.81.210:2181 --replication-factor 1 --partitions 3 --topic test_topic2
Created topic test_topic2.
`--partitions`参数用于指定分区数量
2.查看Topic在数据路径产生的文件
[root@kafka kafka]# ll data/kafka-logs/test_topic2-*
data/kafka-logs/test_topic2-0:
总用量 4
-rw-r--r-- 1 root root 10485760 3月 18 16:06 00000000000000000000.index
-rw-r--r-- 1 root root 0 3月 18 16:06 00000000000000000000.log
-rw-r--r-- 1 root root 10485756 3月 18 16:06 00000000000000000000.timeindex
-rw-r--r-- 1 root root 8 3月 18 16:06 leader-epoch-checkpoint
data/kafka-logs/test_topic2-1:
总用量 4
-rw-r--r-- 1 root root 10485760 3月 18 16:06 00000000000000000000.index
-rw-r--r-- 1 root root 0 3月 18 16:06 00000000000000000000.log
-rw-r--r-- 1 root root 10485756 3月 18 16:06 00000000000000000000.timeindex
-rw-r--r-- 1 root root 8 3月 18 16:06 leader-epoch-checkpoint
data/kafka-logs/test_topic2-2:
总用量 4
-rw-r--r-- 1 root root 10485760 3月 18 16:06 00000000000000000000.index
-rw-r--r-- 1 root root 0 3月 18 16:06 00000000000000000000.log
-rw-r--r-- 1 root root 10485756 3月 18 16:06 00000000000000000000.timeindex
-rw-r--r-- 1 root root 8 3月 18 16:06 leader-epoch-checkpoint
#每一个分区都有独立的数据文件
8.Kafka中消息数据文件存储的内容
8.1.Topic消息数据持久化文件
在Kafka的消息数据持久化目录中有很多文件,如下图所示,每一个Topic主题都有单独的目录存放,命名格式为主题名称-分区名称, 可以看到__consumer_offsets主题有50个分区,每个分区都有独立的目录存储,还有我们自己创建的主题等等。

每一个Topic分区的目录中都包含如下图所示的几个文件,其中有三个文件较为重要。
00000000000000000000.index:记录每条消息数据的一个索引,通过这个索引配合timeindex索引就可以找到消息数据的产生的时间。
00000000000000000000.log:所有的消息数据都会保存在这个文件中。
00000000000000000000.timeindex:记录消息数据的时间索引。

8.2.Kafka内部主题consumer_offsets概念
Consumer_offset主题的作用就是记录消费者消费数据的偏移量位置。
通过下图所示描述consumer_offsets主题的作用。
一个业务Topic中保存了100条消息数据,消费者1从Topic中消费消息数据,同时会定期将消费数据的偏移量写入到kafka内部的Consumer_offset主题上,如果消费者1在消费到第50条消息数据时,异常宕机不可用,此时消费者2启动后,就可以通过消费者1写入到Consumer_offset主题中的消息偏移量,根据偏移量就可以计算出消费者是在那条消息消费时宕机的,紧接着从这条消息处开始消费,从而避免消息长期不被消费的问题。
消费者1从第50条消息处宕机,消费者2启动后从consumer_offsets主题中获取消费者1处理消息的偏移量,得知消费者1上次处理到第50条消息就宕机了,根据偏移量的消费方式在此处加1,最后判断出要从第51条消息处开始消费。
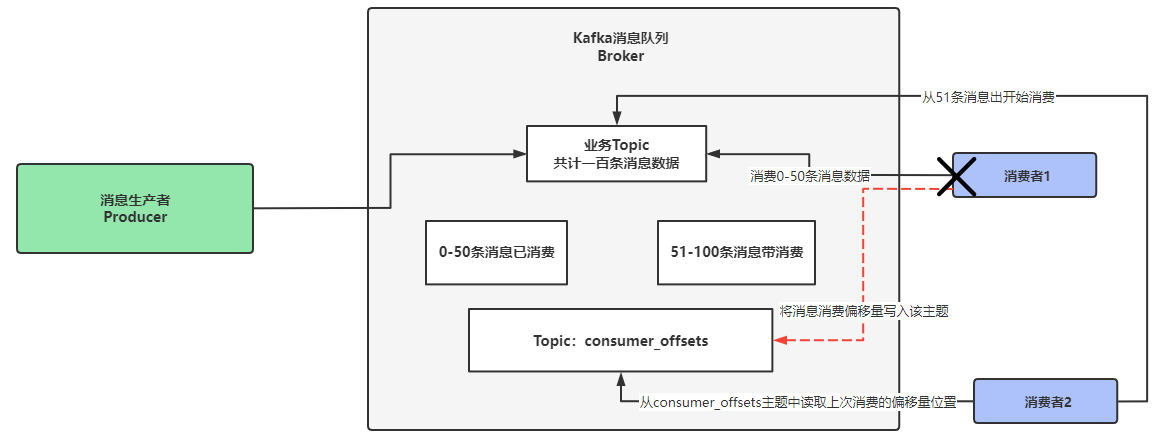
简而言之,Consumer_offset主题就是为了记录消费者消费数据的偏移量值,其他消费者可以根据这个值进一步消费数据。
Kafka内部Consumer_offset主题包含了50个分区,由于每个消费者都会将消费的偏移量上报到该主题中,因此Kafka为了提高这个主题的并发性。故而将其设置了50个分区。
Consumer_offset主题中消息数据默认保留7天。
消费者定期将偏移量写入到Consumer_offset主题的消息数据是key+value的形式,数据内容为:
key:
consumerGroupID+topic+分区号value:当前offset偏移量的值
Consumer_offset主题有50个分区,那么消费者又如何知道要将消息数据写入到那个分区呢?其实是有公式计算的,如下所示。
hash(consumerGroupId)%__consumer_offsets主题的分区数