消息队列交流学习
一、概述
消息队列是分布式系统中重要的中间件,在高性能、高可用、低耦合等系统架构中扮演着重要作用。分布式系统可以借助消息队列的能力,轻松实现以下功能:
- 解耦,将一个流程的上游和下游拆开,上游专注生产消息,下游专注处理消息。
- 广播,一个上游生产的消息轻松被多个下游服务处理。
- 缓冲,应对流量突然上涨,消息队列可以扮演一个缓冲器的作用,保护下游服务使其可以根据实际的消费能力处理消息。
- 异步,上游发送消息后可以马上返回,下游可以异步处理消息。
- 冗余,保留历史消息,处理失败或当出现异常时可以进行重试或者回溯防止丢失。
下图便是消息队列的基本模型,向消息队列中存放数据的叫做生产者,从消息队列中获取数据的叫做消费者。
上图为整体架构,会涉及三类角色:
1)Producer 消息生产者:负责产生和发送消息到 Broker;
2)Broker 消息处理中心:负责消息存储、确认、重试等,一般其中会包含多个 queue;
3)Consumer 消息消费者:负责从 Broker 中获取消息,并进行相应处理;
二、产品介绍与安装
| RabbitMQ | ActiveMQ | RocketMQ | Kafka | |
| 公司/社区 | Rabbit | Apache | 阿里 | Apache |
| 开发语言 | Erlang | Java | Java | scala&Java |
| 协议支持 | AMQP,XMPP,SMTP,STOMP | OpenWire,STOMP,REST,XMPP,AMQP | 自定义协议 | 自定义协议 |
| 可用性 | 高 | 一般 | 高 | 高 |
| 单机吞吐量 | 一般 | 差 | 高 | 非常高 |
| 消息延迟 | 微秒级 | 毫秒级 | 毫秒级 | 毫秒以内 |
| 消息可靠性 | 高 | 一般 | 高 | 一般 |
1. rabbitMQ
RabbitMQ是使用Erlang语言开发的开源消息队列系统,基于AMQP协议来实现。AMQP的主要特征是面向消息、队列、路由(包括点对点和发布/订阅)、可靠性、 安全。AMQP协议更多用在企业系统内,对数据一致性、稳定性和可靠性要求很高的场景,对性能和吞吐量的要求还在其次。
1.1 安装
rabbitmq在Windows下docker安装:
docker run -d --hostname my-rabbit --name my-rabbit -e RABBITMQ_DEFAULT_USER=admin -e RABBITMQ_DEFAULT_PASS=123456 -p 5672:5672 -p 15672:15672 rabbitmq:3-management
rabbitMQ参数说明:
- hostname:配置主机名,集群的时候用到,单机版不配置也可
- RABBITMQ_DEFAULT_USER:创建用户
- RABBITMQ_DEFAULT_PASS:创建用户密码
docker参数说明:
- d:后台运行
- name:镜像生成的容器名
- p:映射宿主机端口
访问地址


1.2 功能
rabbitMQ中的几个概念:
- channel:操作MQ的工具
- exchange:路由消息到队列中
- queue:缓存消息
- virtual host:虚拟主机,是对queue、exchange等资源的逻辑分组
常见的消息模型:
一、不使用exchange(一条消息只能被一个消费者消费)
-
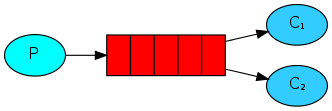
基本消息队列(BasicQueue)

-
工作消息队列(WorkQueue)
二、使用exchange
-
发布订阅(Publish\Subscribe),又根据交换机类型不同分为三种:
-
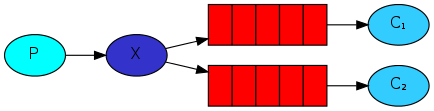
Fanout Exchange:广播
-
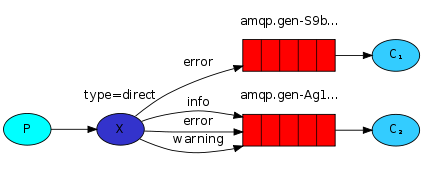
Direct Exchange:路由
-
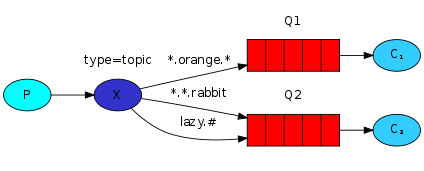
Topic Exchange:主题
-
1.3 常见问题
- 消息可靠性(如何确保发送的消息至少被消费一次)
- 延迟消息问题(如何实现消息的延迟传递)
- 消息堆积问题(如何解决数百万消息堆积,无法及时消费的问题)
- 高可用问题(如何避免单点的MQ故障而导致的不可用的问题)
1.3.1 消息可靠性
消息从生产者发送到exchange,再到queue,再到消费者,导致消息丢失的可能性:
- 发送时丢失:
- 生产者发送的消息未送达exchange
- 消息到达exchange后未到达queue
- MQ宕机,queue将消息丢失
- consumer接收到消息后未消费就宕机
解决方案:
- 生产者确认机制
rabbitMQ提供了publisher confirm机制来避免消息发送到MQ过程中丢失。消息发送到MQ以后,会返回一个结果给发送者,表示消息是否处理成功。结果有两种请求:
- publisher-confirm,发送者确认
- 消息成功投递到交换机,返回ack(acknowledge)
- 消息未投递到交换机,返回nack
- publisher-return,发送者回执
- 消息投递到交换机了,但是没有路由到队列,返回ack,及路由失败原因
确认机制发送消息时,需要给每个消息设置一个全局唯一id,以区分不同消息,避免ack冲突
2)消息持久化
在rabbitmq客户端创建交换机、队列中如果不设置Durability为Durable的情况都不是持久化,而消息需要设置Delivery mode:persistent,否则也不是持久化,在mq重启之后,交换机、队列、消息都会消失。
3)消费者消息确认
rabbitMQ支持消费者确认机制,即:消费者处理消息后可以向MQ发送ack回执,MQ收到ack回执后才会删除该消息。而SpringAMQP则允许配置三种确认模式:
- manual:手动ack,需要在业务代码结束后,调用api发送ack
- auto:自动ack,由spring监测listener代码是否出现异常,没有异常则返回ack;抛出异常则返回nack
- none:关闭ack,MQ假定消费者获取消息后会成功处理,因此消息传递后立即被删除
4)失败重试机制
当消费者出现异常时,消息会不断requeue(重新入列)到队列,再重新发送给消费者,然后再次异常,再次requeue,无限循环,导致mq的消息处理飙升,带来不必要的压力
1.3.2 死信交换机
当一个队列中的消息满足下列情况之一时,可以成为死信(dead letter):
- 消费者使用basic.reject或basic.nack声明为消费失败,并且消息的requeue参数设置为false
- 消息是一个过期消息,超时无人消费
- 要投递的队列消息堆积满了,最早的消息可能成为死信
如果该队列配置了dead-letter-exchange属性,指定了一个交换机,那么队列中的死信就会投递到这个交换机中,而这个交换机称为死信交换机(Dead Letter Exchange,简称DLX)。
如何给队列绑定死信交换机
- 给队列设置dead-letter-exchange属性,指定一个交换机
- 给队列设置dead-letter-routing-key属性,设置死信交换机与死信队列的routingkey
TTL,也就是Time-To-Live。如果一个队列中的消息TTL结束仍为消费,则会变为死信,ttl超时分为两种情况:
- 消息所在的队列设置了存活时间
- 消息本身设置了存活时间
1.3.3 惰性队列
-
消息堆积问题
当生产者发送消息的速度超过了消费者处理消息的速度,就会导致嘟列中的消息堆积,直到队列存储消息达到上限。最早接收到的消息,可能就会成为死信,会被丢弃,这就是消息堆积问题。
解决消息堆积问题有三种思路:
- 增加更多消费者,提高消费速度
- 在消费者内开启线程池加快消息处理速度
- 扩大队列容积,提高堆积上线
-
惰性队列
从rabbitMQ的3.6.0版本开始,就增加了Lazy Queues的概念,也就是惰性队列。
惰性队列的特征如下:
- 接收到消息后直接存入磁盘而非内存
- 消费者要消费消息时才会从磁盘中读取并加载到内存
- 支持数百万条的消息存储
1.3.4 MQ集群
- **普通集群:**是一种分布式集群,将队列分散到集群的各个节点,从而提高整个集群的并发能力。
- 会在集群的各个节点间共享部分数据,包括:交换机、队列元信息。不包含队列中的消息
- 当访问集群某节点时,如果队列不在该节点,会从数据所在节点传递到当前节点并返回
- 队列所在节点宕机,队列中的消息就会丢失
- **镜像集群:**是一种主从集群,普通集群的基础上,添加了主从备份功能,提高集群的数据可用性。
- 交换机、队列、队列中的消息会在各个mq的镜像节点之间同步备份。
- 创建队列的节点被称为该队列的主节点,备份到的其他节点叫做该队列的镜像节点。
- 一个队列的主节点可能是另一个队列的镜像节点
- 所有的操作都是主节点完成,然后同步给镜像节点
- 主宕机后,镜像节点会替代成新的主
镜像集群虽然支持中从,但主从同步并不是强一致的,某些情况下可能有数据丢失的风险。因此在rabbitMQ的3.8版本以后,退出了新的功能:仲裁队列来代替镜像集群,底层采用Raft协议确保主从的数据一致性。
2.kafka
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源 项目。
2.1 产生背景
kafka的诞生是为了解决linkedin的数据管道问题,起初linkedin采用了ActiveMQ来进行数据交换,大约是在2010年前后,那是的ActiveMQ还远远无法满足linkedin对数据传递系统的要求,经常由于各种缺陷而导致消息阻塞或者服务无法正常访问,为了能够解决这个问题,linkedin决定研发自己的消息传递系统,当时linkedin的首席架构师Jay kreps便开始组织团队进行消息传递系统的研发。
2.2 Kafka的特性
- 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒
- 可扩展性:kafka集群支持热扩展
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
- 高并发:支持数千个客户端同时读写
2.3 Kafka场景应用
- 日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
- 消息系统:解耦和生产者和消费者、缓存消息等。
- 用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
- 运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
- 流式处理:比如spark streaming和storm
- 事件源
2.4 安装
安装zookeeper
docker pull zookeeper
docker run --name zoo -p 2181:2181 -d zookeeper
安装kafka(方法一)
docker pull bitnami/kafka
docker run --name kafka -p 9092:9092 -e KAFKA_ZOOKEEPER_CONNECT=10.30.1.13:2181 -e ALLOW_PLAINTEXT_LISTENER=yes -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 -d bitnami/kafka
docker容器部署必须指定以下环境变量:
- **KAFKA_ZOOKEEPER_CONNECT **指定 zookeeper 的地址:端口。
- ALLOW_PLAINTEXT_LISTENER 允许使用PLAINTEXT侦听器。
- KAFKA_ADVERTISED_LISTENERS 是指向Kafka代理的可用地址列表。 Kafka将在初次连接时将它们发送给客户。格式为PLAINTEXT://host:port,此处已将容器9092端口映射到宿主机9092端口,所以host指定为localhost,便可在宿主机执行测试程序连接 kafka。
- KAFKA_LISTENERS是 Kafka 代理将侦听传入连接的地址列表。格式为PLAINTEXT://host:port, 0.0.0.0代表接受所有地址。设置了上个变量就要设置此变量。
使用docker-compose集群部署(方法二)
docker-compose.yml
version: '2'
services:
zoo1:
image: zookeeper
container_name: zoo
ports:
- 2181:2181
kafka1:
image: 'bitnami/kafka:latest'
ports:
- '9092:9092'
container_name: kafka1
environment:
- KAFKA_ZOOKEEPER_CONNECT=zoo1:2181
- KAFKA_BROKER_ID=1
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT:///127.0.0.1:9092
depends_on:
- zoo1
kafka2:
image: 'bitnami/kafka:latest'
ports:
- '9093:9092'
container_name: kafka2
environment:
- KAFKA_ZOOKEEPER_CONNECT=zoo1:2181
- KAFKA_BROKER_ID=2
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT:///127.0.0.1:9093
depends_on:
- zoo1
kafka3:
image: 'bitnami/kafka:latest'
ports:
- '9094:9092'
container_name: kafka3
environment:
- KAFKA_ZOOKEEPER_CONNECT=zoo1:2181
- KAFKA_BROKER_ID=3
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT:///127.0.0.1:9094
depends_on:
- zoo1
kafka tool安装
安装完成后添加kafka信息,如下图操作界面

添加完成后如下图所示:

2.5 功能

2.5.1 kafka中的几个概念
-
broker
- 一个kafka的集群有多个broker组成,这样才能实现负载均衡以及容错
- broker是无状态的,他们是通过zookeeper来维护集群状态
- 一个kafka的broker每秒可以处理数十万次读写,每个broker都可以处理TB消息而不影响性能。
-
zookeeper
- zookeeper用来管理和协调broker,并且存储了kafka的元数据(例如:有多少topic、partition)
- zookeeper服务主要用于通知生产者和消费者kafka集群中有新的broker加入、或者kafka集群中出现故障的broker
-
producer(生产者)
- 生产者负责将数据推送给broker的topic
-
consumer(消费者)
- 消费者负责从broker的topic中拉取数据,并自己进行处理
-
consumer group (消费者组)

- consumer group 是kafka提供的可扩展且具有容错性的消费者机制
- 一个消费者组可以包含多个消费者
- 一个消费者组有一个唯一的ID(group Id)
- 组内的消费者一起消费主题的所有分区数据
个人理解总结:
通常来讲,消息模型可以分为两种, 队列和发布-订阅式。 队列的处理方式是 一组消费者从服务器读取消息,一条消息只有其中的一个消费者来处理。在发布-订阅模型中,消息被广播给所有的消费者,接收到消息的消费者都可以处理此消息。Kafka为这两种模型提供了单一的消费者抽象模型: 消费者组 (consumer group)。 消费者用一个消费者组名标记自己。 一个发布在Topic上消息被分发给此消费者组中的一个消费者。 假如所有的消费者都在一个组中,那么这就变成了queue模型。 假如所有的消费者都在不同的组中,那么就完全变成了发布-订阅模型。
- 分区(Partitions)

一个分区只能同时被一个消费者消费
-
replication(副本)
- 副本可以确保某个服务出现故障时,确保数据依然可用
-
topic(主题)
- 主题是一个逻辑概念,用于生产者发布数据,消费者拉取数据
- kafka中的主题必须要有标识符,而且是唯一的,kafka中可以有任意数量的主题,没有数量上的限制
- 在主题中的消息是有结构的,一般一个主题包含 某一类消息
- 一旦生产者发送消息到主题中,这些消息就不能被更新(更改)
-
offset(偏移量)
- offset记录着下一条将要发送个consumer的消息的序号
- 默认kafka将offset存储在zookeeper中
- 在一个分区中,消息是有顺序的方式存储者着,每个分区的消费都是一个递增的id,这个就是偏移量offset
- 偏移量在分区中才是有意义的,在分区之间是没有任何意义的
2.5.2 Kafka四个核心API
- Producer API(生产者API)允许应用程序发布记录流至一个或多个kafka的topics(主题)。
- Consumer API(消费者API)允许应用程序订阅一个或多个topics(主题),并处理所产生的对他们记录的数据流。
- **Streams API(流API)**允许应用程序充当流处理器,从一个或多个topics(主题)消耗的输入流,并产生一个输出流至一个或多个输出的topics(主题),有效地变换所述输入流,以输出流。
- Connector API(连接器API)允许构建和运行kafka topics(主题)连接到现有的应用程序或数据系统中重用生产者或消费者。例如,关系数据库的连接器可能捕获对表的每个更改。
2.5.3 kafka生产者幂等性
- 幂等性
- 拿http举例来说,一次或多次请求,得到的响应是一致的,换句话来说,就是执行多次操作与执行一次操作的影响是一样的
- kafka生产者幂等性
- 在生产者生产消息时,如果出现retry时,有可能会一条消息被发送了多次,如果kafka不具备幂等性的,就有可能会在分区中多保存一条一模一样的消息
为了实现生产者的幂等性,kafka一如了Producer ID(PID)和Sequence Number的概念。
- PID:每个Producer在初始化时,都会分配一个唯一的PId,这个PID对用户来说是透明的
- Sequence Number:针对每个生产者(对应PID)发送到指定主题分区的消息都应对应一个从0开始递增的Sequence Number
当kafka的生产者生产消息时,会增加一个pid和sequence number,发送消息会将pid和sn一块发送,kafka接收到消息会将消息和pid、sn一并保存下来,如果ack响应失败,生产者重试,再次发送消息时,kafka会根据pid/sn是否需要在保存一条消息(判断条件:生产者发送过来的sn是否小于等于partition中消息对应的sn)
2.5.4 生产者分区写入策略
生产者写入消息到topic,kafka依据每个不同的策略将数据分配到不同的分区
- 轮询分区策略
- 默认的策略,也是使用最多的策略,可以最大限度保证所有消息平均分配到一个分区
- 如果在生产消息时,key为null,则使用轮询算法均衡地分配分区
- 随机分区策略
- 每次都随机的将消息分配到每个分区,在较早的版本,默认的分区策略时随机策略,也是为了将消息均衡的写入到每个分区,但后续轮询策略表现更佳,所以基本上很少使用随机策略
- 按key分区分配策略
- 按key分配策略有可能会出现数据倾斜,例如:某个key包含了大量的数据,因为key值一样,所以所有的数据都将分配到一个分区中,造成该分区的消息数量远大于其他的分区
- 自定义分区策略
乱序问题
轮询策略,随机策略都会导致一个问题,生产到kafka中的数据都是乱序存储的,而按key分区可以 一定程度上实现数据有序存储也就是局部有序,但这又可能会导致数据倾斜,所以在实际生产环境中要结合实际情况来做取舍。
2.5.5 消费者rebalance机制
kafka中的rebalance称之为再均衡,是kafka中确保consumer group下所有的consumer如何达成一致,分配订阅的topic的每个分区的机制。
rebalance触发的时机有:
- 消费者组中consumer的个数发生变化。例如:有新的的consumer加入到消费者组,或是某个 consumer停止了。
rebalance的不良影响:
- 发生rebalance时,consumer group下的所有consumer都会协调在一起共同参与,kafka使用分配策略尽可能达到最公平的分配
- rebalance过程会对consumer group产生非常严重的影响,rebalance的过程中所有的消费者即将停止工作,直到rebalance完成
2.5.6 消费者的分区分配策略
- range范围分配策略
- range范围分配策略时kafka默认的分配策略,它可以确保每个消费者消费的分区数量时均衡的,注意:range范围分配策略是针对每个topic的。(分配规则:分区数/消费者数量,除不尽加入5/3则分配的是前两个消费者消费两个消息(即1.2消息被1消费者消费,3.4消息被2消费者消费),第三个消费者只消费一条消息)
- RoundRobin轮询策略
- 轮询策略是将消费组内所有消费者以及消费者所订阅的所有partition按照字典排序(topic和分区的hashcode进行排序),然后通过轮询方式逐个将分区以此分配给每个消费者
- sticky粘性分配策略
- 分区分配尽可能均匀
- 在发生rebalance的时候,分区的分配尽可能与上一次分配保持相同,在没有发生rebalance时,sticky粘性分配策略和roundRobin分配策略类似
三、使用
1. rabbitMQ
1.1 基本消息队列
1.1.1 官方api使用
public class Recv {
private final static String QUEUE_NAME = "hello";
public static void main(String[] argv) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
// 建立连接 对应图中的Connetcions模块
Connection connection = factory.newConnection();
// 创建通道 对应图中的Channels
Channel channel = connection.createChannel();
// 创建队列名 对应图中的Queues
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
System.out.println(" [*] Waiting for messages. To exit press CTRL+C");
}
}
1.1.2 SpringAMQP使用
-
AMQP
是用于在应用程序或之间传递业务消息的标准。该协议与语言和平台无关,更符合微服务中独立性的要求。
-
Spring AMQP
基于AMQP协议定义的一套API规范,提供了模板来发送和接收消息。包含两部分,其中spring-amqp是基础抽象,spring-rabbit是底层的默认实现。
使用maven导入相关依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
配置文件编写rabbitMQ连接信息:
spring:
rabbitmq:
host: 127.0.0.1 # 主机
port: 5672 # 端口
virtual-host: / # 虚拟空间
username: admin # 用户名
password: 123456 # 密码
发送消息到队列中:
@Service
public class RabbitMQServiceImpl implements IrabbitMQService {
@Autowired
private RabbitTemplate rabbitTemplate;
@Override
public void sendMsg(String msg) {
rabbitTemplate.convertAndSend("testQueue",msg);
}
}
1.2 工作消息队列
作用:提高消息处理速度,避免消息堆积。(一个消息对应多个消费者,谁的能力强谁把消息消费掉)
生产者:
@Override
public void sengMsg2WorkQueue(String msg) {
for (int i = 0; i < 10 ; i++) {
System.out.println("工作消息队列,生产者发送消息:"+msg+i);
rabbitTemplate.convertAndSend("workQueue",msg+i);
}
}
消费者:
/**
* 模拟两个消费者去消费工作队列中的数据
* @param msg
*/
@RabbitListener(queues = "workQueue")
public void listenWorkQueue(String msg) throws InterruptedException {
System.out.println("工作消息队列,消费者1接收消息:"+msg);
Thread.sleep(200);
}
@RabbitListener(queues = "workQueue")
public void listenWorkQueue2(String msg) throws InterruptedException {
System.out.println("工作消息队列,消费者2接收消息:"+msg);
Thread.sleep(20);
}
结论:
消息平均分配到每一个消费者,在特定的环境下是不满足生产需求,理应谁的消费能力强谁消费更多的消息。
推进:
在配置文件里加入如下配置信息方可解决以上问题
listener:
simple:
prefetch: 1 # 表示每次只能占用消费一条消息
1.3 Fanout
-
声明fanoutExchange和队列并绑定要广播的队列交给spring容器
package com.gdc.springboottest.config; import org.springframework.amqp.core.Binding; import org.springframework.amqp.core.BindingBuilder; import org.springframework.amqp.core.FanoutExchange; import org.springframework.amqp.core.Queue; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class FanoutConfig { // 1.声明交换机 @Bean public FanoutExchange fanoutExchange () { return new FanoutExchange("fanoutExchange"); } // 2.声明队列 @Bean public Queue queue1 () { return new Queue("fanoutQueue1"); } // 3.绑定 @Bean public Binding binding1 (FanoutExchange fanoutExchange,Queue queue1) { return BindingBuilder.bind(queue1).to(fanoutExchange); } // 2.声明队列2 @Bean public Queue queue2 () { return new Queue("fanoutQueue2"); } // 3.绑定 @Bean public Binding binding2 (FanoutExchange fanoutExchange,Queue queue2) { return BindingBuilder.bind(queue2).to(fanoutExchange); } } -
发布消息(生产者)
@Override public void sengMsg2FanoutExchange(String msg) { rabbitTemplate.convertAndSend("fanoutExchange","",msg); } -
订阅消息(消费者)
/** * 监听fanoutExchange * @param msg */ @RabbitListener(queues = "fanoutQueue1") public void listenFanoutQueue1(String msg) { System.out.println("fanoutQueue1消息队列,消费者接收消息:"+msg); } @RabbitListener(queues = "fanoutQueue2") public void listenFanoutQueue2(String msg) { System.out.println("fanoutQueue2消息队列,消费者接收消息:"+msg); }
1.4 Direct
-
发布消息(生产者)
@Override public void sengMsg2DirectExchange(String msg, String routingKey) { rabbitTemplate.convertAndSend("directExchange",routingKey,msg); } -
订阅消息(消费者)
/** * 监听directExchange * @param msg */ @RabbitListener(bindings = @QueueBinding( value = @Queue(name = "directQueue1"), exchange = @Exchange(name = "directExchange",type = "direct"), key = { "red","orange"} )) public void listenDirectQueue1(String msg) { System.out.println("directQueue1消息队列,消费者接收消息:"+msg); } @RabbitListener(bindings = @QueueBinding( value = @Queue(name = "directQueue2"), exchange = @Exchange(name = "directExchange",type = "direct"), key = { "red","yellow"} )) public void listenDirectQueue2(String msg) { System.out.println("directQueue2消息队列,消费者接收消息:"+msg); }
1.5 Topic
TopicExchange与DirectExchange类似,区别在于routingKey必须是多个单词的列表,并且以.分割。
Queue与Exchange指定Bindingkey时可以使用通配符:
#:代指0个或多个单词
*:代指一个单词
-
发布消息(生产者)
@Override public void sengMsg2TopicExchange(String msg, String routingKey) { rabbitTemplate.convertAndSend("topicExchange",routingKey,msg); } -
订阅消息(消费者)
/** * topic * @param msg */ @RabbitListener(bindings = @QueueBinding( value = @Queue(name = "topicQueue1"), exchange = @Exchange(name = "topicExchange",type = ExchangeTypes.TOPIC), key = "shanghai.#" )) public void listenTopictQueue1(String msg) { System.out.println("topicQueue1消息队列,消费者接收消息:"+msg); } @RabbitListener(bindings = @QueueBinding( value = @Queue(name = "topicQueue2"), exchange = @Exchange(name = "topicExchange",type = ExchangeTypes.TOPIC), key = "#.songjiang" )) public void listenTopictQueue2(String msg) { System.out.println("topicQueue2消息队列,消费者接收消息:"+msg); }
1.6 常见问题解决
1.6.1 消息可靠性
-
1.SpringAMQP实现生产者确认
- 在application.yml中添加配置
spring: rabbitmq: publisher-confirm-type: correlated publisher-returns: true template: mandatory: true配置说明:
publish-confirm-type:开启publisher-confirm,这里支持两种类型:
1)simple:同步等待confirm结果,直到超时
2)correlated:异步回调,定义ConfirmCallback,MQ返回结果时会回调这个ConfirmCallback
publish-returns:开启publish-return功能,同样是基于callback机制,不过是定义ReturnCallback
template.mandatory:定义消息路由失败时的策略。true,则调用ReturnCallback,false:则直接丢弃消息。
- 每个RabbitTemplate只能配置一个ReturnCallback,因此需要在项目启动过程中配置:
@Configuration public class CommonConfig implements ApplicationContextAware { @Override public void setApplicationContext(ApplicationContext applicationContext) throws BeansException { // 从容器中获取rabbitTemplate RabbitTemplate rabbitTemplate = applicationContext.getBean(RabbitTemplate.class); /*rabbitTemplate.setReturnCallback(new RabbitTemplate.ReturnCallback() { @Override public void returnedMessage(Message message, int i, String s, String s1, String s2) { } });*/ // 设置ReturCallback rabbitTemplate.setReturnCallback((message, replyCode, replyText, exchange, routingKey) -> { System.out.println(message.toString()); System.out.println(replyCode); System.out.println(replyText); System.out.println(exchange); System.out.println(routingKey); }); } }- 生产者代码
// 消息id,唯一 CorrelationData correlationData = new CorrelationData(UUID.randomUUID().toString()); // 添加callback correlationData.getFuture().addCallback(new SuccessCallback<CorrelationData.Confirm>() { @Override public void onSuccess(CorrelationData.Confirm confirm) { if (confirm.isAck()) { System.out.println("生产者发送消息成功"); }else { System.out.println("nack"); System.out.println("消息发送失败"); System.out.println("原因:"+confirm.getReason()); } } }, new FailureCallback() { @Override public void onFailure(Throwable throwable) { System.out.println("消息发送异常"+throwable.getMessage()); } }); rabbitTemplate.convertAndSend(DIRECT_EXCHANGE,"red","hello red",correlationData);- 消费者
@RabbitListener(bindings = @QueueBinding( value = @Queue(name = "directQueue1"), exchange = @Exchange(name = "directExchange",type = ExchangeTypes.DIRECT), key = { "red","orange"} )) public void directMsg1(String msg) { System.out.println("消费者接收消息:"+msg); } @RabbitListener(bindings = @QueueBinding( value = @Queue(name = "directQueue2"), exchange = @Exchange(name = "directExchange",type = ExchangeTypes.DIRECT), key = { "red","yellow"} )) public void directMsg2(String msg) { System.out.println("消费者接收消息:"+msg); } -
消息持久化
- 在spring—amqp默认交换机、消息队列、消息都是持久化的
-
消费者消息确认
- 在配置文件中加入(auto、none、manual)
listener: simple: acknowledge-mode: auto -
消费失败重试机制
- 配置文件
listener: simple: prefetch: 1 acknowledge-mode: auto retry: enabled: true # 开启消费者失败重试 initial-interval: 1000 # 初始的失败等待时长为1秒 multiplier: 1 # 下次失败的等待时长倍数,下次等待时长=multipler * last-interval max-attempts: 3 #最大重试次数 stateless: true #true无状态,false有状态。如果业务中包含事务,这里改为false-
在开启重试模式后,重试次数耗尽,如果消息依然失败,则需要有MessageRecoverer接口来处理,它包含三种不同的实现:
-
RejectAndDontRequeueRecoverer:重试耗尽后,直接reject,丢弃消息。默认就是这种方式
-
ImmediateRequeueMessageRecoverer:重试耗尽后,返回nack,消息重入队列
-
RepublishMessageRecoverer:重试耗尽后,将失败消息投递到指定的交换机
- 代码实现如下:
@Component public class RabbitConfig { /** * 定义错误信息交换机 * @return */ @Bean public DirectExchange errMsgExchange() { return new DirectExchange("errorExchange"); } /** * 定义错误信息队列 * @return */ @Bean public Queue errQueue() { return new Queue("errQueue"); } /** * 将队列与交换机相互绑定 * @return */ @Bean public Binding errorBind() { return BindingBuilder.bind(errQueue()).to(errMsgExchange()).with("error"); } /** * 定义republishMessageRecoverer * */ @Bean public MessageRecoverer republishMessageRecoverer (RabbitTemplate rabbitTemplate) { return new RepublishMessageRecoverer(rabbitTemplate,"errorExchange","error"); } }
-
2. kafka
导入kafka依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
配置文件
spring:
kafka:
bootstrap-servers: 127.0.0.1:9092 # kafka集群信息
producer: # 生产者配置
retries: 3 # 设置大于0的值,则客户端会将发送失败的记录重新发送
batch-size: 16384 #16K
buffer-memory: 33554432 #32M
acks: 1
# 指定消息key和消息体的编解码方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
group-id: testGroup # 消费者组
enable-auto-commit: true # 自动提交
auto-offset-reset: earliest # 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
生产者
kafkaTemplate.send("testTopic", "key", msg);
消费者
package com.gdc.springboottest.config;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
@Component
public class KafkaListeners {
//kafka的监听器,topic为"testTopic",消费者组为"testGroup"
@KafkaListener(topics = "testTopic", groupId = "testGroup")
public void listenKafkaMsg(ConsumerRecord<String, String> record) {
String value = record.value();
System.out.println(value);
System.out.println(record);
}
}