目录
一、理论基础
K-means算法是一种动态聚类方法,这种方法先选择若干样本作为聚类的中心,在按某种聚类准则(通常采用最小距离原则)使各种样本向各个中心积聚,从而得到初始的分类,然后,判断分类的合理性,如果不合理,就修改分类,如此反复的修改聚类的迭代运算,直到合理为止。
数据聚类是一种常用的数据分析方法,它通过将具有相似特征的数据点分组,形成簇,来实现对数据的分类和分析。kmeans算法是一种常用的数据聚类算法,它通过最小化簇内点之间的距离,最大化不同簇之间的距离,来实现数据的聚类。
1.1 欧氏距离
在kmeans算法中,常用的距离度量方法为欧氏距离。欧氏距离表示两个点在n维空间中的距离,其公式为:
$$d(x_i,x_j)=\sqrt{\sum_{k=1}^n(x_{ik}-x_{jk})^2}$$
其中,$x_i$和$x_j$为两个数据点,n为数据点的维度。
1.2 簇内平方和误差(SSE)
簇内平方和误差(SSE)是kmeans算法中用来评估聚类效果的指标,它表示所有簇内数据点与该簇质心的距离平方和,其公式为:
$$SSE=\sum_{i=1}^k\sum_{x\in C_i}d(x,c_i)^2$$
其中,k为簇的个数,$C_i$表示第i个簇,$c_i$表示第i个簇的质心。
1.3 kmeans算法
kmeans算法的基本步骤如下:
随机选择k个数据点作为初始质心。
计算每个数据点到k个质心的距离,将每个数据点归到距离最近的质心所在的簇中。
计算每个簇的质心。
重复步骤2和步骤3,直到簇不再改变或达到预设的最大迭代次数。
kmeans算法的数学公式如下:
初始化:
$$C={C_1,C_2,...,C_k},C_i={x_i},i\in[1,k]$$
迭代:
将每个数据点$x_i$归为距离最近的质心所在的簇:
$$C_i={x_i},i\in[1,k]$$
$$for;i=1;to;n;do$$
$$;;;;;;;;;;;;j=\mathop{argmin}_{j\in[1,k]}d(x_i,c_j)$$
$$;;;;;;;;;;;;C_j=C_j\cup{x_i}$$
$$;;;;;;;;;;;;end;for$$
重新计算每个簇的质心:
$$c_j=\frac{1}{|C_j|}\sum_{x_i\in C_j}x_i,j\in[1,k]$$
计算簇内平方和误差(SSE):
$$SSE=\sum_{i=1}^k\sum_{x\in C_i}d(x,c_i)^2$$
如果SSE不再改变或达到最大迭代次数,则停止迭代。否则,返回步骤1。
1.4实现步骤
基于kmeans算法的数据聚类的实现步骤如下:
初始化k个质心。
计算每个数据点到k个质心的距离,将每个数据点归到距离最近的质心所在的簇中。
计算每个簇的质心。
4.重复步骤2和步骤3,直到簇不再改变或达到预设的最大迭代次数。
下面是详细的实现步骤:
Step 1: 初始化k个质心
随机选择k个数据点作为初始质心,可以使用随机数生成器实现。
Step 2: 计算每个数据点到k个质心的距离,将每个数据点归到距离最近的质心所在的簇中
对于每个数据点$x_i$,计算它到k个质心的距离$d(x_i,c_j)$,并将它归为距离最近的质心所在的簇$C_j$中。
Step 3: 计算每个簇的质心
对于每个簇$C_j$,计算该簇所有数据点的平均值,作为该簇的质心$c_j$。
Step 4: 重复步骤2和步骤3,直到簇不再改变或达到预设的最大迭代次数
重复执行步骤2和步骤3,直到簇不再改变或达到预设的最大迭代次数。在每次迭代后,可以计算簇内平方和误差(SSE),以评估聚类效果。
本文详细介绍了基于kmeans算法的数据聚类方法,包括欧氏距离、簇内平方和误差和kmeans算法的数学公式,以及实现步骤。kmeans算法是一种常用的数据聚类算法,具有高效、简单和易于实现的特点,可以在各种数据分析和机器学习任务中广泛应用。
二、核心程序
function [KindData,KindNum]=Clustering(Center,Data)
[DataRow,DataColumn]=size(Data);
[CenterRow,CenterColumn]=size(Center);
KindData=zeros(DataRow,DataColumn,CenterColumn);
KindNum=linspace(0,0,CenterColumn);
for i=1:DataColumn
Distance=linspace(0,0,CenterColumn);
for j=1:CenterColumn
for k=1:DataRow
Distance(j)=Distance(j)+(Data(k,i)-Center(k,j)).^2;
end
end
Distance=sqrt(Distance);
[X,Y]=min(Distance);
KindData(:,KindNum(Y)+1,Y)=Data(:,i);
KindNum(Y)=KindNum(Y)+1;
end
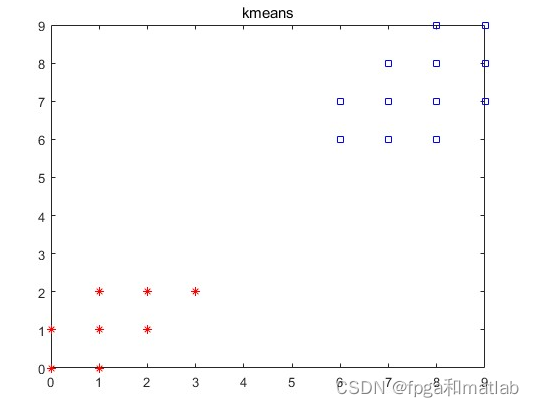
up2145三、仿真结论