例子参考:https://www.jiqizhixin.com/articles/2019-05-15-2
数据集:https://www.cs.ccu.edu.tw/~wtchu/projects/MoviePoster/index.html
将获取到原始数据集,其中,有三个文件, Movie Poster Dataset是1980-2015年部分影片海报图片, Movie Poster Metadata是1980-2015年部分影片的数据详情,example:

Readme则是对 Movie Poster Metadata文件里边的字段解释,在训练过程中只用到IMPId和 Genre(影片类型)。

步骤:
- 数据处理
获取到影片的类型对影片类型实现one-hot编码,如果是属于哪个类型,用1表示,其他为0,得到如下文件,

考虑到特征的相关性,删除影片比较少的类型列(将数量小于50的类型列进行删除),最终留下22个电影类型,如下:

将电影类型作为最终的结果值,然后加载图片:
for i in tqdm(range(train.shape[0])):
img = image.load_img('D:/aayu/实例/图像多分类/data/Images/'+train['ID'][i]+'.jpg',target_size=(400,400,3))
img = image.img_to_array(img)
img = img/255
train_image.append(img)
X = np.array(train_image)- 模型构建
模型是由4层卷积和3层全连接层构成,具体参数如下:
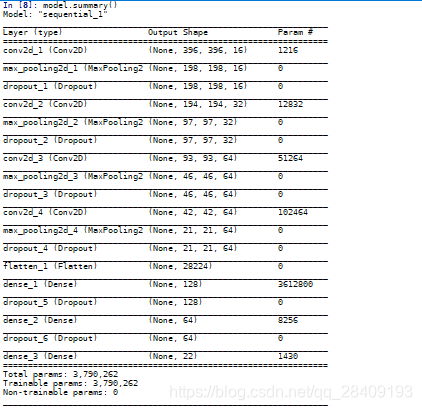
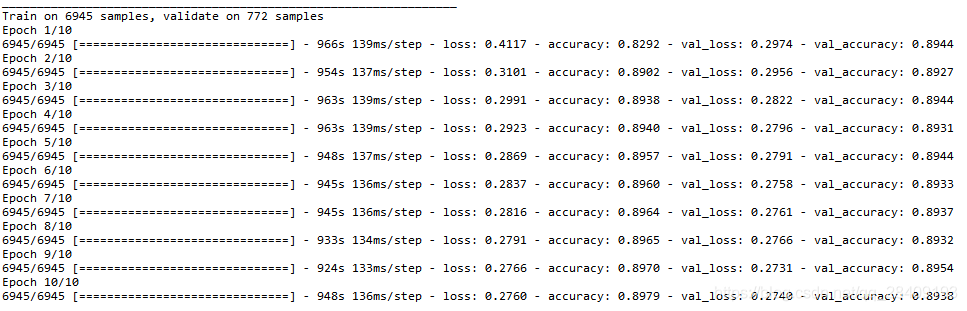
训练结果为:
- 模型预测
新增一个复仇者联盟的海报对数据进行预测(此处可更换为任意海报数据),加载数据:
img = image.load_img('F:/aayu/图像/data/GOT.jpg',target_size=(400,400,3))
img = image.img_to_array(img)
img = img/255 预测结果:

完整代码:
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.utils import to_categorical
from keras.preprocessing import image
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from tqdm import tqdm
#%matplotlib inline
train = pd.read_csv('F:/aayu/图像/data/multi-data.csv')
print(train.head())
train_image = []
for i in tqdm(range(train.shape[0])):
img = image.load_img('F:/aayu/图像/data/Images/'+train['ID'][i]+'.jpg',target_size=(400,400,3))
img = image.img_to_array(img)
img = img/255
train_image.append(img)
X = np.array(train_image)
y = np.array(train.drop(['ID', 'Genre','News','Reality-TV','Italian','Polish','Adult','Talk-Show',
'Spanish','Russian','Cantonese','R','PG','German','English','Japanese',
'Filipino','French','G','Game-Show','Hungarian'],axis=1))
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42, test_size=0.1)
#model
model = Sequential()
model.add(Conv2D(filters=16, kernel_size=(5, 5), activation="relu", input_shape=(400,400,3)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(filters=32, kernel_size=(5, 5), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(filters=64, kernel_size=(5, 5), activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(filters=64, kernel_size=(5, 5), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(22, activation='sigmoid'))
model.summary()
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=10, validation_data=(X_test, y_test), batch_size=64)
#precise
#加入新数据,进行测试
img = image.load_img('F:/aayu/图像/data/GOT.jpg',target_size=(400,400,3))
img = image.img_to_array(img)
img = img/255
classes = np.array(train.columns[:22])
proba = model.predict(img.reshape(1,400,400,3))
top_3 = np.argsort(proba[0])[:-4:-1]
for i in range(3):
print("{}".format(classes[top_3[i]])+" ({:.3})".format(proba[0][top_3[i]]))
plt.imshow(img)总结:与minist数据集相比,该数据集的分类中存在一张图片多个类的情况,而minist数据集当中一张图片代表一个数字,也就是一个分类,所以图像分类和图像多分类在本质上的区别在于数据集,算法实现基本都是一样的。
(数据集正在处理中,github网址为:https://github.com/YUXUEPENG/ImageMulti-Classification.git)