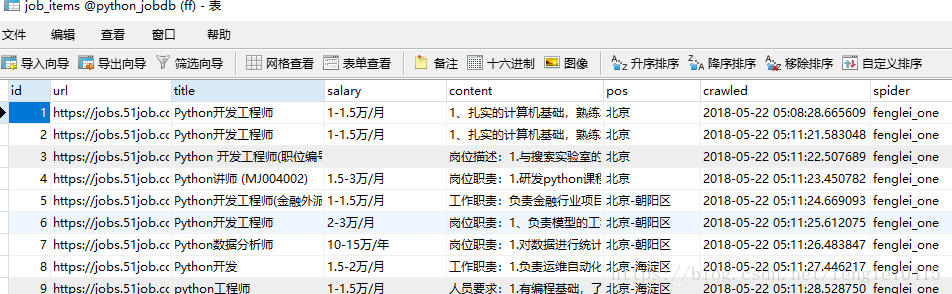
准备要抓取的数据和得到链接的xpath
创建项目
scrapy startproject pythonjob
创建爬虫
scrapy genspider job 51job.com
job.py中代码:
# -*- coding: utf-8 -*-
import scrapy
from scrapy_redis.spiders import RedisSpider
from pythonjob.items import PythonjobItem
class JobSpider(RedisSpider):
name = 'job'
# 存于redis
redis_key = 'jobspider:start_urls'
allowed_domains = ['51job.com']
page = 1
url = "http://search.51job.com/jobsearch/search_result.php?fromJs=1&jobarea=010000%2C00&keyword=python&curr_page="
# start_urls = [url + str(page)]
def parse(self, response):
href_list = response.xpath('//div[@class="el"]/p/span/a/@href').extract()
for href in href_list:
yield scrapy.Request(href, callback=self.detal_page_parse)
def detal_page_parse(self, response):
item = PythonjobItem()
# 职位链接
url = response.url
# 招聘标题
title = response.xpath('//div[@class="cn"]/h1/text()').extract()[0]
# 工资情况
salary = response.xpath('//div[@class="cn"]/strong/text()').extract()
salary = ''.join(salary)
# 招聘内容
content = response.xpath('//div[@class="bmsg job_msg inbox"]/p/text()|//div[@class="bmsg job_msg inbox"]//li/text()|//div[@class="bmsg job_msg inbox"]//text()').extract()
content = ''.join(content).replace('\t','').replace('\r\n','').replace(' ','').replace('\xa0','')
# 招聘职位
pos = response.xpath('//span[@class="lname"]/text()').extract()[0]
# 招聘人数
count = response.xpath('//div[@class="t1"]/span[3]/text()').extract()[0]
print('count=====',count)
if len(content) < 1:
content = title
item['url'] = url
item['title'] = title
item['salary'] = salary
item['content'] = content
item['pos'] = pos
return item
添加运行分布式 test_redis.py 文件:
from scrapy import cmdline
cmdline.execute('scrapy runspider job.py'.split())
pipelines.py 文件(管道文件,用于对数据的处理以及存储):
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
from datetime import datetime
#新添加的
import pymongo
import pymysql
from pythonjob.settings import MONGO_HOST, MONGO_PORT, MONG0_DBNAME, SHEET_NAME
class ExamplePipeline(object):
# 存于redis中增加两个字段
def process_item(self, item, spider):
item["crawled"] = datetime.utcnow()
item["spider"] = 'PC'
return item
class PythonjobPipeline(object):
# 用于存储到本地
def __init__(self):
self.file = open('job.josn','w',encoding='utf-8')
def process_item(self, item, spider):
# josn_str = json.dumps(dict(item),ensure_ascii=False)+'\n'
# self.file.write(josn_str)
return item
def close_file(self, spider):
self.file.close()
class job_mongo(object):
# 用于存储到mongodb数据库
def __init__(self):
mongo_host = MONGO_HOST
mongo_port = MONGO_PORT
sheet_name = SHEET_NAME
db_name = MONG0_DBNAME
print("打印mongo的信息===", mongo_host, mongo_port, db_name, sheet_name)
client = pymongo.MongoClient(host=mongo_host,port=mongo_port)
db_name = client[db_name]
self.sheet_name = db_name[sheet_name]
def process_item(self, item, spider):
python_dict = dict(item)
self.sheet_name.insert(python_dict)
return item
class job_mysql(object):
# 用于存储到MySQL数据库
def __init__(self):
mysql_port = 3306
mysql_host = '127.0.0.1'
dbname = 'python_jobdb'
user = 'afu'
password = '123456'
sheetname = 'job_items'
print("打印mysql的信息===", mysql_host, mysql_port, dbname, sheetname)
self.con = pymysql.connect(host=mysql_host, user=user, password=password,
database=dbname, port=mysql_port, charset='utf8')
# 创建表
self.cursor = self.con.cursor()
def process_item(self, item, spider):
args = [item["url"], item["title"], item["salary"], item["content"], item["pos"], item["crawled"], item["spider"]]
sql = "INSERT INTO job_items(url,title,salary,content,pos,crawled,spider) VALUES (%s,%s,%s,%s,%s,%s,%s)"
self.cursor.execute(sql, args)
# 事务提交
self.con.commit()
return item
def close_spider(self, spider):
self.cursor.close()
self.con.close()
items中:
import scrapy
class PythonjobItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 职位链接
url = scrapy.Field()
# 招聘标题
title = scrapy.Field()
# 工资情况
salary = scrapy.Field()
# 招聘内容
content = scrapy.Field()
# 招聘职位
pos = scrapy.Field()
# 增加到redis两个字段(记录时间和分机姓名)
crawled = scrapy.Field()
spider = scrapy.Field()settings.py配置中:
BOT_NAME = 'pythonjob' SPIDER_MODULES = ['pythonjob.spiders'] NEWSPIDER_MODULE = 'pythonjob.spiders' # scrapy_redis相关配置 USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36' #使用scrapy-redis自己的组件去重,不使用scrapy默认的去重 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" #使用scrapy-redis自己调度器,不使用scrapy默认的调度器 SCHEDULER = "scrapy_redis.scheduler.Scheduler" #调度状态持久化,不清理redis缓存,允许暂停/启动爬虫 SCHEDULER_PERSIST = True #按照sorted 排序顺序出队列,建议使用某一个,这样才能在redis数据库中看到,其实可以不写不影响结果 SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue" # Crawl responsibly by identifying yourself (and your website) on the user-agent COOKIES_ENABLED = False # Obey robots.txt rules ROBOTSTXT_OBEY = False # 记录日志 LOG_LEVEL = 'DEBUG' # 增加爬出延迟时间,减轻服务器压力 DOWNLOAD_DELAY = 1
ITEM_PIPELINES = {
'pythonjob.pipelines.ExamplePipeline': 290,
'pythonjob.pipelines.PythonjobPipeline': 291,
# 数据存到MySQL,mongodb,redis数据库没有先后顺序,互不干扰
'pythonjob.pipelines.job_mysql': 292,
'pythonjob.pipelines.job_mongo': 293,
# 下面这个管道是必须要启用的--支持数据存储到redis数据库里
'scrapy_redis.pipelines.RedisPipeline': 400,
}
# 变量名可以随意设置 REDIS_HOST = '127.0.0.1' REDIS_PORT = 6379 MONGO_HOST = '127.0.0.1' MONGO_PORT = 27017 MONG0_DBNAME = 'python_job' SHEET_NAME = 'job'
redis存储数据情况:
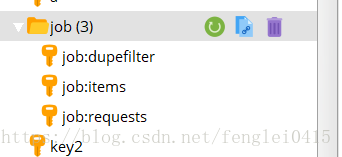
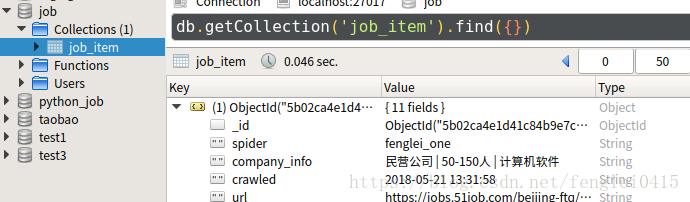
mongdb存储数据情况:
存储MySQL情况: