目录
自编码器原理及使用Pytorch框架实现(AutoEncoder)
1.Denoising Auto-Encoder
一般而言,自编码器网络的训练较为稳定,从之前的自编码器的训练效果来也确实是这样的,但是由于损失函数是直接度量重建样本与真实样本的底层特征之间的距离,上面给出的自编码器的度量方式计算采用欧氏距离进行度量。然而并不是评价重建样本的逼真度和多样性等抽象指标,所以在某些任务上的效果一般,如图像重建,容易出现重建图像边缘模糊,逼真度相对真实图片仍有不小差距。
为了让编码器尝试学习到数据的真实分布,产生了一系列的自编码器变种网络。

Github代码实现: https://github.com/KeepTryingTo/Pytorch-GAN
2.Dropout Auto-Encoder
自编码器网络同样面临过拟合的风险,所以也需要在网络中进行正则化,Dropout Auto-Encoder通过随机断开网络的连接来减少网络的表达能力,防止过拟合。
Dropout Auto-Encoder通过直接在网络中添加Dropout层即可。
Github代码实现: https://github.com/KeepTryingTo/Pytorch-GAN
3.Adversarial Auto-Encoder
提示:建议读者在看这部分理论时,建议先看完生成对抗网络的基本部分。
(1)原理图
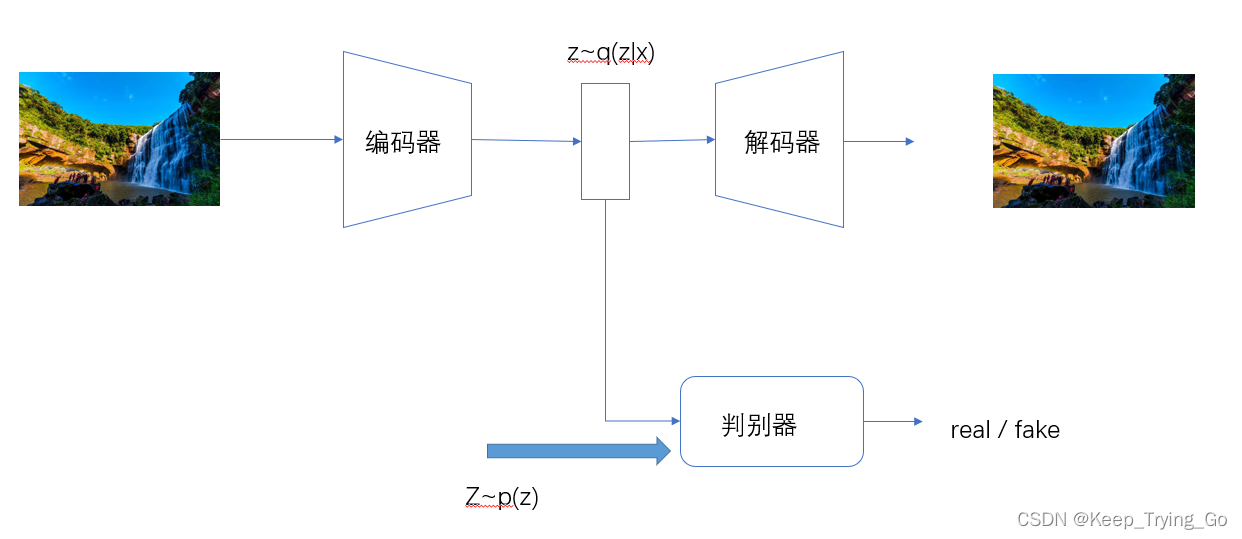
(2)解释说明
从某个已知的先验分布中p(z)采样隐藏向量z,方便利用p(z)来重建输入,对抗自编码器利用额外的判别器网络(Discriminator)来判定降维的隐藏向量z是否采样自先验分布p(z)。如上图所示,判别器网络的输入为一个属于[0,1]区间的变量,表示隐藏向量是否采样自先验分布p(z);所有采样自先验分布p(z)的z标注为真,采样自编码器的条件概率q(z|x)的z标注为假。
通过上面的训练方式,除了可以重建样本,还可以约束条件概率分布q(z|x)逼近先验分布p(z)。(对抗自编码器是生成对抗网络的算法衍生而来的)。
Github代码实现: https://github.com/KeepTryingTo/Pytorch-GAN
核心部分
#train encoder and decoder
z_en = encoder(imgs)
z_fake = decoder(z_en)
loss_ae = loss_AE(z_fake,imgs)
opt_AE.zero_grad()
loss_ae.backward()
opt_AE.step()
step_loss_AE += loss_ae.item()
# ----------------------------------------------------------------
# ----------------------------------------------------------------
#train discriminator
z_size = np.shape(imgs)[0]
z_real = torch.randn(size=(z_size,128)).to(config.DEVICE)
z_en_fake = encoder(imgs).detach()
discInput = torch.cat((z_real,z_en_fake),dim = 0)
discLabel = torch.cat((torch.ones(z_size,1),torch.zeros(z_size,1)),dim = 0).to(config.DEVICE)
discOutput = disc(discInput)
loss_disc_out = loss_disc(discOutput,discLabel)
opt_disc.zero_grad()
loss_disc_out.backward()
opt_disc.step()
step_loss_disc += loss_disc_out.item()
# ----------------------------------------------------------------
# ----------------------------------------------------------------
#train encoder
z_en = encoder(imgs).detach()
enOutput = disc(z_en)
loss_en_out = loss_en(enOutput,torch.ones(z_size,1).to(config.DEVICE))
opt_en.zero_grad()
loss_en_out.backward()
opt_en.step()
step_loss_en += loss_en_out.item()
# ----------------------------------------------------------------