原创 | 文 BFT机器人

01 介绍
定义
人工智能(A):一种广泛的学科,其目标是创造智能机器,而不是人类和动物所展示的自然智能。
通用人工智能(AlamosGold):一个术语,用来描述未来机器可以在所有有经济价值的任务中达到甚至超过人类的全部认知能力。
人工智能安全:一个研究和尝试减轻未来人工智能可能对人类造成的灾难性风险的领域。
机器学习(ML):人工智能的一个子集,经常使用统计技术,使机器能够从数据中“学习”,而不需要明确给出如何这样做的指令这个过程被称为“训练”一个“模型”,使用学习“算法,逐步提高模型在特定任务中的性能。
强化学习(RL):机器学习的一个领域,在这个领域中,软件代理通过在一个环境中的试验和错误来学习以目标为导向的行为该环境提供奖励或惩罚以响应他们为实现目标而采取的行动(称为“策略”)。
深度学习(DL):机器学习的一个领域,试图模仿大脑神经元层的活动,以学习如何识别数据中的复杂模式。“深度”指的是当代模型中大量的神经元,有助于学习丰富的数据表示,以获得更好的性能提升。
型号: 一旦ML算法已经在数据上进行了训练,过程的输出就被称为模型。然后,这可以用来作出预测。
计算机视觉(CV):使机器能够分析、理解和处理图像和视频
Transformer 模型体系结构:是大多数最先进(SOTA)ML研究的核心。它由多“关注”层组成,这些层学习输入数据的哪一部分对于给定的任务来说是最重要的。Transformers开始于语言建模,然后扩展到计算机视觉、音频和其他形式。
研究
漫射模型以其令人印象深刻的文本到图像生成能力席卷了计算机视觉世界
人工智能研究更多的科学问题,包括塑料回收、核聚变反应堆控制和天然产物发现。
标度法则重新关注数据:也许模型标度并不是您所需要的全部。朝着用一个模式来统治他们的方向发展社区驱动的大型模型开源以极快的速度发生,使集体能够与大型实验室竞争受到神经科学的启发,人工智能研究在方法上开始看起来像认知科学。
行业
新贵Al半导体初创公司与NVIDIA相比有没有取得进展?铝的使用统计数据显示,NVIDIA领先20-100倍。大型科技公司扩展他们的人工智能云,并与A(G)L初创公司建立大规模合作伙伴关系招聘冻结和人工智能实验室的解散加速了包括DeepMind和OpenAl在内的许多巨头初创公司的形成。
MaiorAl药物研发公司拥有18项临床资产,首个CE标志被授予自主医学成像诊断人工智能领域最新的代码研究成果被大型科技公司和初创公司迅速转化为商业开发工具。
政策
学术界和工业界在大规模人工智能工作方面的鸿沟可能无法弥补:学术界几乎没有完成任何工作学术界正在把接力棒传给由非传统来源供资的分散的研究集体。
美国半导体能力的伟大复兴是认真的开始。
-人工智能继续被注入更多的国防产品类别,国防人工智能初创企业获得更多的资金安全
-人工智能安全研究的意识、人才和资金都有所提高,但仍远远落后于能力研究。
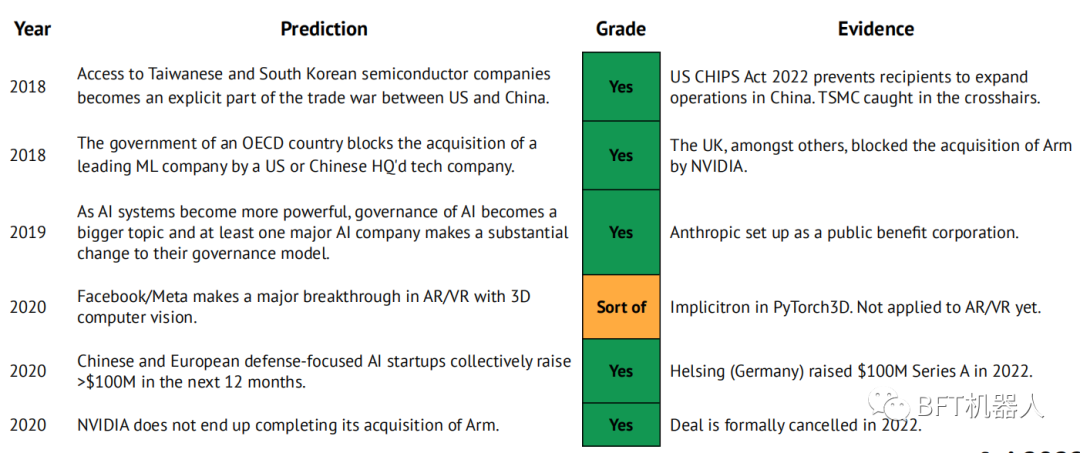
我们的2021年预测
-
变形金刚取代RNN来学习世界模型,在大型和丰富的游戏中,RL代理超过了人类的性能。
-
ASML的市值达到500亿美元。
-
Anthropic在GPT、DotaAlphaGo的水平上发表文章,使自己成为AlamosGold研究的第三极。
-
随着Graphcore、Cerebras、SambaNova、Groq或Mythic中的至少一家被大型技术公司或主要半导体公司收购,铝半导体行业出现了一波整合浪潮。
-
小型变压器+CNN混合型号与lmageNet上的当前SOTA相匹配(CoAtNet-7,90.88%,244B参数),参数少10倍
-
DeepMind显示了物理科学的重大突破
-
根据PapersWithCode的测量,JAX框架每月创建的回购量从1%增长到5%。
-
一个新的以AlamosGold为重点的研究公司成立,该公司拥有重要的支持和路线图,该路线图侧重于一个垂直部门(如开发人员工具、生命科学)。

02 调查研究
2021预测: DeepMind在物理科学上的突破 (1/3)
2021年,我们预测:“DeepMind发布了物理科学的重大研究突破。这此后,公司在数学和材料科学方面取得了重大进展。
数学中的决定性时刻之一是对感兴趣的变量之间的关系提出一个猜想或假设。这通常是通过观察这些变量值的大量实例来实现的,并且可能使用数据驱动的猜想生成方法。但它们仅限于低维、线性和一般简单的数学对象。
在《自然》杂志的一篇文章中DeepMind的研究人员提出了一个选代的工作流程,涉及数学家和监督ML模型(典型的是NN)。数学家假设一个函数涉及两个变量(输入X()和输出Y())。一台计算机生成大量的变量的实例和神经网络拟合的数据。梯度显著性方法用于确定X》中最相关的输入。数学家可以转而完善他们的假设和/或生成更多的数据,直到猜想在大量数据上成立。

2021 预测: DeepMind在物理科学上的突破 (2/3)
2021年,据预测:“DeepMind发布了物理科学的重大研究突破。”这此后,公司在数学和材料科学方面取得了重大进展。
DeepMind的研究人员与悉尼大学和牛津大学的数学教授合作,使用他们的框架(i)提出一个算法,可以解决表征理论中长达40年的猜想。
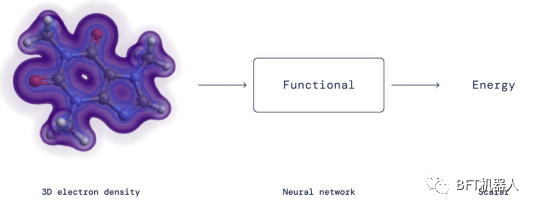
DeepMind在材料科学方面也做出了重要贡献。结果表明,密度泛函理论中的精确泛函是计算电子能量的重要工具,可以用神经网络对其进行有效的逼近。值得注意的是,研究人员没有约束神经网络来验证dft函数的数学约束,而只是将它们合并到适合神经网络的训练数据中。

2021 预测: DeepMind在物理科学上的突破 (3/3)
2021年,我们预测:“DeepMind发布了物理科学的重大研究突破。”这此后,公司在数学和材料科学方面取得了重大进展
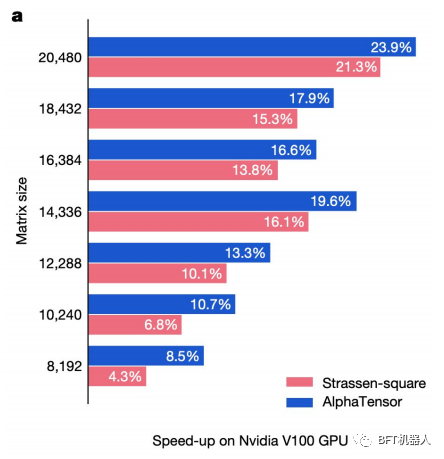
DeepMind改变了AlphaZero的用途 (他们的RL模型训练来击败国际象棋、围棋和将棋中最好的人类棋手)做矩阵乘法。这个AlphaTensor模型能够找到新的确定性算法来乘以两个矩阵。为了使用AlphaZero,研究人员将矩阵乘法问题重新定义为一个单人游戏,其中每一步都对应一个算法指令,目标是将一个张量归零,以测量预测算法的正确性。
寻找更快的矩阵乘法算法,一个看似简单且得到充分研究的问题,几十年来一直是陈腐的。DeepMind的方法不仅有助于加速该领域的研究,还促进了基于矩阵乘法的技术,即人工智能、成像,以及手机上发生的一切。
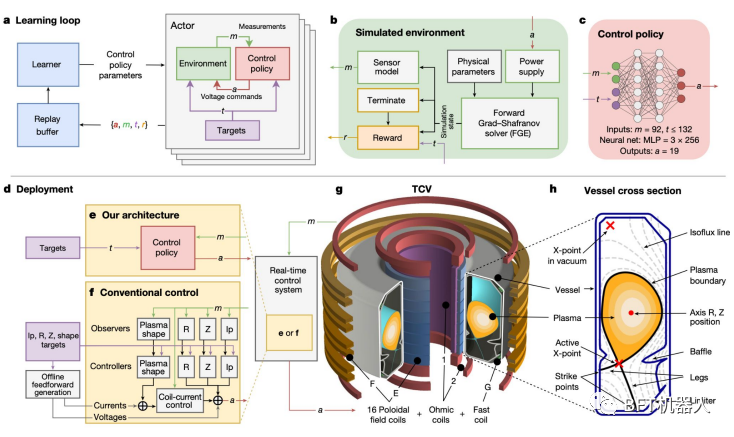
强化学习可能成为下一个核聚变突破的核心组成部分
DeepMind训练了一个强化学习系统来调整洛桑TCV(可变配置托卡马克)的磁线圈。该系统的灵活性意味着它也可以用于ITER,法国正在建造的下一代托卡马克装置。
实现核聚变的一个流行途径是使用托卡马克装置将极热的等离子体限制在足够长的时间内。
一个主要的障碍是等离子体是不稳定的,当它接触到托卡马克的墙壁时会损失热量和降解材料。稳定它需要调整磁线圈每秒数千次。
DeepMind的深度RL系统就做到了这一点:首先在模拟环境中,然后部署在洛桑的TCV中。该系统还能够以新的方式塑造等离子体,包括使其与ITER的设计兼容。
预测整个已知蛋白质组的结构:下一步会开启什么?
自开源以来,DeepMind的AlphaFold2已经在数百篇研究论文中使用。该公司目前已经部署了该系统来预测来自植物、细菌、动物和其他生物体的2亿种已知蛋白质的三维结构。这一技术所带来的下游突破--从药物发现到基础科学一一需要几年时间才能实现。
今天,蛋白质数据库中有19万个由经验确定的3D结构。这些都是通过X射线晶体学和低温电子显微镜得出的。
·AlphaFoldDB于20221年7月首次发布1M预测蛋白质结构。
这个新版本的数据库大小是200x。来自190个国家的500,000多名研究人员使用了该数据库。
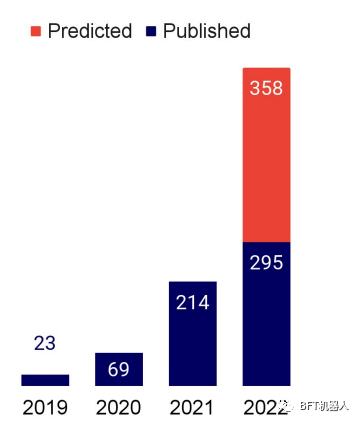
·AlphaFold在人工智能研究文献中被提及的次数正在大幅增长,预计每年将增长三倍(右图)。
蛋白质的语言模型:一个熟悉的开源和缩放模型的故事
研究人员独立地将语言模型应用于蛋白质的生成和结构预测问题,同时对模型参数进行定标。他们都报告说,从扩展他们的模型中获得了巨大的好处。
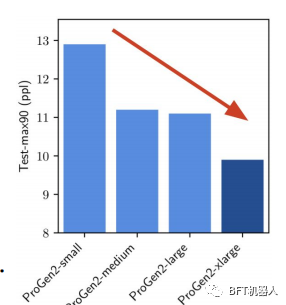
Salesforce研究人员发现,扩展LM可以让他们更好地捕获蛋白质序列的训练分布使用6B参数ProGen2,他们产生的蛋白质具有类似的折叠天然蛋白质,但具有显示不同的序列身份。但是,为了释放规模的全部潜力,作者们坚持认为应该把更多的重点放在数据分布上。
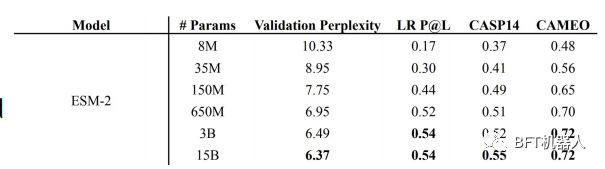
超能力者等。介绍了蛋白质LM的ESM家族,其大小范围从8M到15B (称为ESM-2)参数。使用ESM-2,他们构建ESMFold来预测蛋白质结构他们表明,ESMFold产生类似的预测ALphaFold2和RoseTTAFold,但快了一个数量级。
这是因为ESMFold不依赖于使用多序列比对(MSA)和模板,如AlphaFold2和RoseTTAFold,而是只使用蛋白质序列。
OpenCell:在机器学习的帮助下理解蛋白质定位
研究人员利用基于CRISPR的内源性标记修饰基因,通过阐明蛋白质功能的特定方面,来确定蛋白质在细胞中的定位。然后,他们使用聚类算法来识别蛋白质群落,并制定关于未表征蛋白质的机械假设。
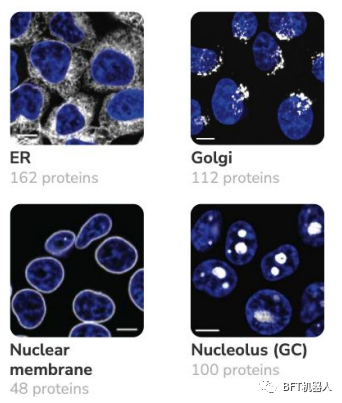
基因组研究的一个重要目标是了解蛋白质的定位以及它们在细胞中如何相互作用以实现特定的功能。OpenCell计划拥有约5900张3D图像中的1310个标记蛋白质的数据集,使研究人员能够绘制蛋白质的空间分布、功能和相互作用之间的重要联系。
马尔可夫聚类的图上的蛋白质相互作用成功地划定功能相关的蛋白质。这将有助于研究人员更好地了解迄今尚未定性的蛋白质。
我们经常期望ML能够提供明确的预测。但这里和数学一样,机器学习首先给出部分答案(这里是聚类),然后人类解释、制定和测试假设,最后给出一个确定的答案。
塑料回收得到急需的ML工程酶
来自UTAustin的研究人员设计了一种能够降解PET的酶,PET是一种占全球固体废物12%的塑料。
PET水解酶,称为快速PETase,比现有的酶对不同的温度和pH值更有活力。
FAST-PETase能够在1周内几乎完全降解51种不同的产品。
他们还表明,他们可以从FAST-PET酶降解回收的单体中重新合成PET,这可能为工业规模的闭环PET回收开辟道路。


当心复杂的错误。
随着ML在定量科学中的使用越来越多,ML中的方法学错误可能会泄露给这些学科。普林斯顿大学的研究人员警告说,基于机器学习的科学的可重复性危机日益严重,部分原因是一个这样的方法论错误:数据泄漏。
数据泄漏是一个总括术语,涵盖了所有不应该对模型可用的数据实际上是可用的情况。最常见的例子是测试数据包含在训练集中。但是,当模型使用的特征是结果变量的代理时,或者当测试数据来自与科学主张不同的分布时,泄漏可能会更加有害。
作者认为,基干机器学习的科学的可重复性失败是系统性的:他们研究了17个科学领域的20篇综述,检查了基干机器学习的科学中的错误,发现在329篇综述中的每一篇都发生了数据泄漏错误。受ML中日益流行的模型卡的启发,作者建议研究人员使用旨在防止数据泄漏问题的模型信息表。

OpenAl使用Minecraft作为计算机使用代理的测试平台
OpenAl训练了一个模型(Video PreTraining,VPT),使用少量标记的鼠标和键盘交互从视频玩Minecraft。VPT是第一个学习制作钻石的机器学习模型,“一项任务通常需要熟练的人类超过20分钟(24000次操作)。
OpenAl收集了2000小时的标记有鼠标和键盘动作的视频并训练了一个逆动力学模型(IDM)来预测过去和未来的动作一一这是预训练部分。
然后,他们使用IDM标记70小时的视频,在此基础上,他们训练了一个模型,仅根据过去的视频来预测动作。
结果表明,该模型可以通过仿真学习和强化学习(RL)对(a)模型进行微调,以获得难以从零开始使用RL的性能。

企业人工智能实验室争相进入人工智能进行代码研究
驱动GitHub Copilot的OpenAl的Codex以其多行代码或直接从自然语言指令完成代码的能力给计算机科学界留下了深刻的印象。这一成功刺激了这一领域的更多研究,包括Salesforce、Gogle和DeepMind。
·借助对话式CodeGen,Salesforce研究人员可以利用LLM的语言理解能力来指定多回合语言交互中的编码要求。它是唯一一个与Codex竞争的开源模式。
·谷歌的LLMPaLM取得了更令人印象深刻的成就,它实现了与Codex类似的性能,但其训练数据中的代码少了50倍(PaLM是在更大的非代码数据集上训练的)。当对Python代码进行微调时,PaLM的表现优于SOTA(82%vs717%) Depfix上的同行,一个代码修复任务。
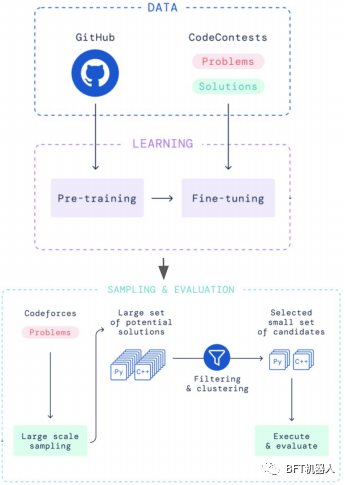
DeepMind的AlphaCode解决了一个不同的问题:在竞争性编程任务中生成整个程序。它在Codeforces一个编码竞赛平台上排名前半。它是预先训练的对GitHub数据和Codeforces问题和解决方案进行微调。然后对数百万个可能的解决方案进行采样、过滤和聚类,以获得10个最终候选方案。
Transformer五年后,一定会有一些高效的替代品。
变压器模型核心的注意层因其输入的二次依赖而闻名。大量的论文承诺解决这个问题,但没有采用任何方法。
SOTALLM有不同的风格(自编码,自回归,编码器-解码器),但都依赖于相同的注意力机制。
在过去的几年里,一群古戈尔的变压器已经被训练好了,花费了数百万数十亿?)到世界各地的实验室和公司。但是所谓的“高效变形金刚”EfficientTransformers)在大规模的LM研究中是找不到的(它们会带来最大的不同!)GPT-3PaLMLaMDA,地鼠,OPT,布卢姆,GPT-Neo巨电子-图灵NLG,GLM-130B等都在他们的变形金刚中使用了原始的注意层。
有几个原因可以解释这种缺乏采用: (一)潜在的线性加速只适用于大的输入序列,(ii)新的方法引入额外的约束,使架构不那么普遍, (ii) 报告的效率措施不转化为实际的计算成本和时间节省。

语言模型的数学能力大大超过预期
基于谷歌的540B参数LM PaLM,谷歌的Minerva在数学基准测试中获得了503%的分数(比之前的SOTA高出43.4%),超过了预测者预期的2022年的最佳得分(13%)。同时,OpenAl训练了一个网络来解决两个数学奥林匹克问题(IMO)。
Google使用LaTeX和MathJax,使用来自arXiv和网页的额外118GB科学论文数据集来训练其(预训练的)LLM PaLM。通过使用思维链提示(包括提示中的中间推理步骤,而不仅仅是最终答案)和多数投票等其他技术,Minerva将大多数数据集上的SOTA提高了至少两位数的百分比。
Minerva只使用语言模型,并没有明确地对形式数学进行编码。它更灵活,但只能自动评估其最终答案,而不是它的整个推理,这可能证明一些分数膨胀。相比之下,OpenAl在精益正式环境中构建了一个(基于转换器的)定理证明器。他们的模型的不同版本能够解决AMC12(26)、AIME(6)和IMO(2)中的一些问题(难度递增的顺序)。

更多精彩内容请关注公众号:BFT机器人
本文为原创文章,版权归BFT机器人所有,如需转载请与我们联系。若您对该文章内容有任何疑问,请与我们联系,将及时回应。