博主github:https://github.com/MichaelBeechan
博主CSDN:https://blog.csdn.net/u011344545
============================================
概念篇:https://blog.csdn.net/u011344545/article/details/89525801
技术篇:https://blog.csdn.net/u011344545/article/details/89526149
人才篇:https://blog.csdn.net/u011344545/article/details/89556941
应用篇:https://blog.csdn.net/u011344545/article/details/89574915
============================================
清华AMiner团队 AMiner.org
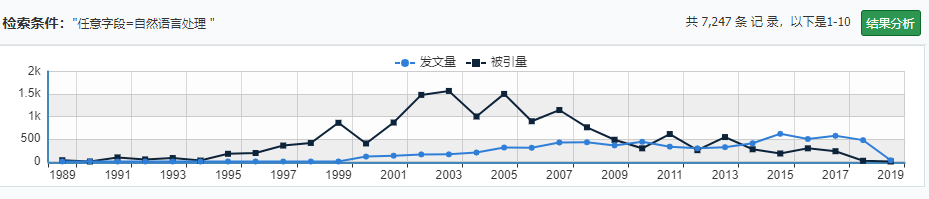
自然语言处理论文发表情况(来自维普智立方)
1、国外实验室及人才介绍
AMiner 基于发表于国际期刊会议的学术论文,对自然语言处理领域全球 h-index 排序top1000 的学者进行计算分析,绘制了该领域顶尖学者全球分布地图。
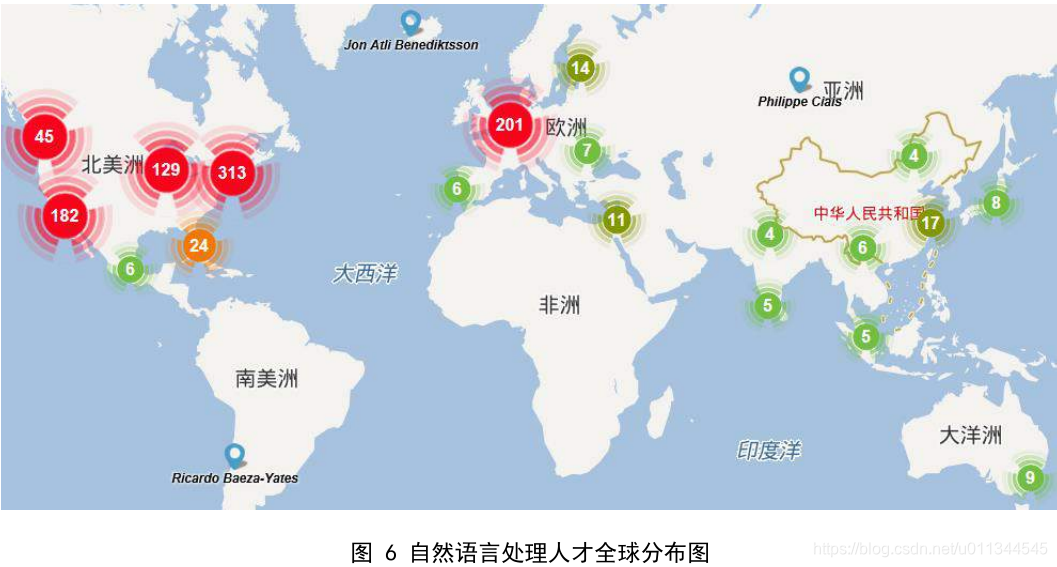
根据上图,我们可以得出以下结论——从国家来看,美国是自然语言处理研究学者聚集最多的国家,英国、德国、加拿大和意大利紧随其后;从地区来看,美国东部是自然语言处理人才的集中地,而西欧、美国西部等其他先进地区也吸引了大量自然语言处理的研究者。
全球自然语言处理顶尖学者的 h-index 平均数为 59,h-index 指数大于 60 的学者最多占41%,h-index 指数在 40 到 60 之间的学者次之,占比 40%。
自然语言处理领域顶尖学者男性占比 91%,女性占比 9%,男女比例不均衡。
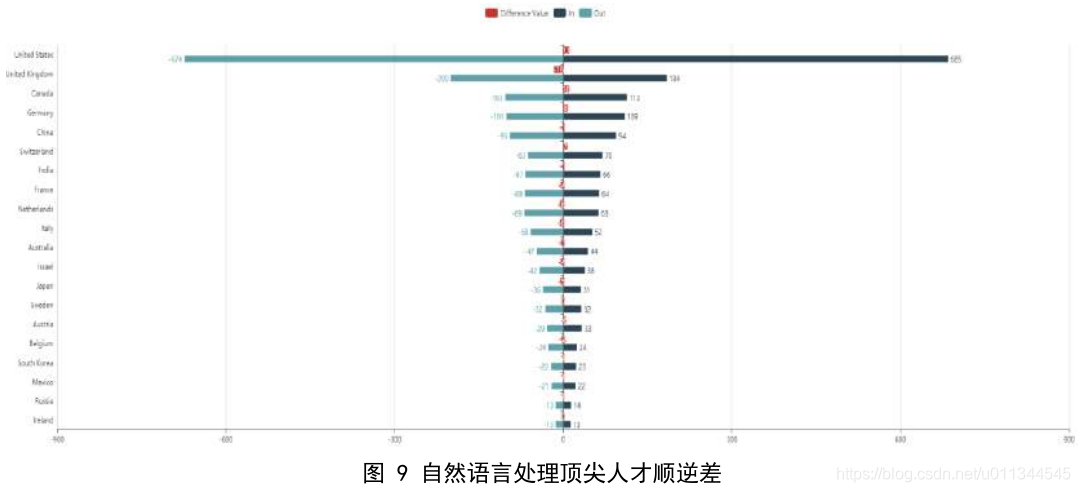
AMiner 对顶尖人才的迁徙路径做了分析。由上图可以看出,各国自然语言处理顶尖人才的流失和引进是相对比较均衡的,其中美国是自然语言处理领域人才流动大国,人才输入和输出幅度都大幅度领先,且从数据来看人才流入略大于流出。英国、德国、加拿大和中国等国落后于美国,其中英国和加拿大有轻微的顶尖人才流失现象。
以下选取在 ACL、EMNLP、NAACL、COLING 等 4 个会议在近 5 年累计发表 10 次以上论文的国外学者及其所在实验室做简要介绍。
Chris Dyer

Chris Dyer,卡内基梅隆大学助理教授,2010 年在马里兰大学获语言学博士学位。主要兴趣领域是机器学习、自然语言处理和语言学的交叉研究。比较感兴趣的一些课题有:机器翻译、用于语言处理的神经网络模型、语言建模、特征归纳和表示学习、大数据算法、音乐概率模型等。

卡内基梅隆大学语言技术研究所主要研究内容包括自然语言处理、计算语言学、信息提取、信息检索、文本挖掘分析、知识表示、机器学习、机器翻译、多通道计算和交互、语音处理、语音界面和对话处理等。
Christopher D. Manning

Christopher D. Manning,斯坦福大学计算机科学与语言学习的教授,1994 年在斯坦福大学获得博士学位。他致力于研究能够智能处理、理解和生成人类语言材料的计算机。Manning 在自然语言处理的深度学习领域有着深入研究,包括递归神经网络、情感分析、神经网络依赖分析等。
Manning 曾获 ACL、CILING、EMNLP 的最佳论文奖。

斯坦福大学自然语言处理小组包括了语言学和计算机科学系的成员,是斯坦福人工智能实验室的一部分。主要研究计算机处理和理解人类语言的算法,工作范围从计算语言学的基本研究到语言处理的关键应用技术均有涉猎,涵盖句子理解、自动问答、机器翻译、语法解析和标签、情绪分析和模型的文本和视觉场景等。该小组的一个显著特征是将复杂和深入的语言建模和数据分析与 NLP 的创新概率、机器学习和深度学习方法有效地结合在一起。
Dan Klein


Dan Klein,伯克利大学自然语言处理小组负责人。2004 年在斯坦福大学取得计算机科学的博士学位。主要研究重点是自然语言信息的自组织,兴趣领域包括无监督的语言学习、机器翻译、NLP 的高效算法、信息提取、语言丰富的语言模型、NLP 的符号和统计方法的集成以及历史语言学等。多次在国际顶级会议上发表论文并获奖,如在 2012 年 EMNLP 上获得 Distinguished Paper “Training Factored PCFGs with Expectation Propagation”
2017 年 Dan Klein 在 ACL、EMNLP、NAACL、COLING 等会议发表的论文有:
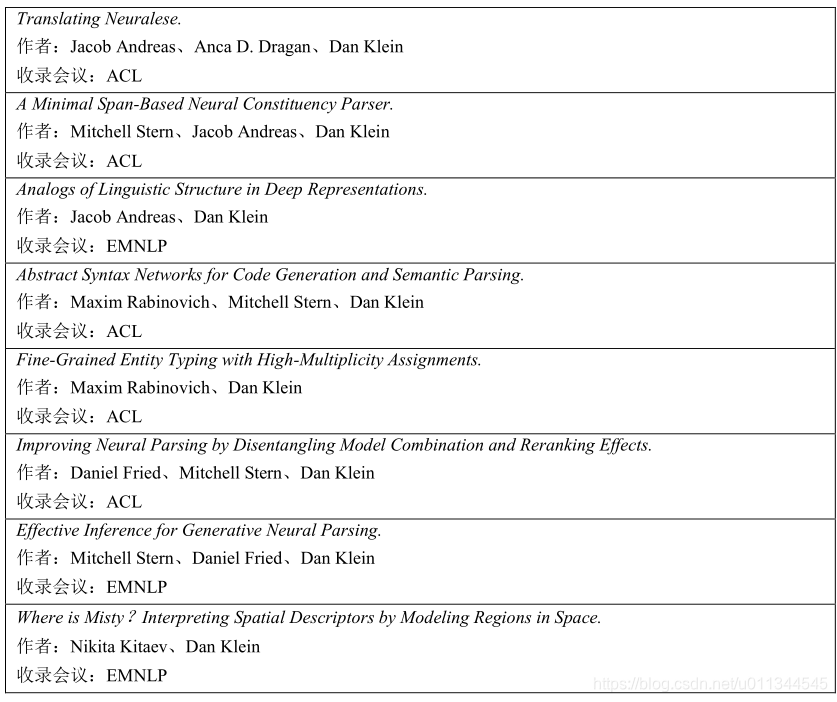
伯克利大学自然语言处理小组分属于加州大学伯克利分校计算机科学部。主要从事以下几方面的研究工作,语言分析、机器翻译、计算机语言学、基于语义的方法、无监督学习等,多次在顶级国际会议(ACL、EMNLP、AAAI、IJCAI、COLING 等)上发表多篇论文,下表是 2018 年最新被选用的论文:

Natural Language Processing Group at University of Notre Dame
圣母大学自然语言处理小组主要关注机器翻译领域,并有多个项目的研究,如由 DARPALORELEI 和 Google 赞助的无监督多语言学习模型和算法研究;由亚马逊学术研究奖和谷歌教师研究奖赞助的研究,主要研究课题方向包括基于神经网络的机器翻译模型,以及使用神经网络进行翻译和语言建模的算法等。多次在国际顶级期刊和会议上发表论文。目前该小组主要负责人是 David Chiang
David Chiang,美国圣母大学教授,在宾夕法尼亚大学计算机与信息科学获得博士学位。主要研究领域是自然语言处理,同时在语言翻译、句法分析等方面也有研究。David Chiang在 2005 年提出的基于短语的翻译模型,对机器翻译来说是一个巨大的进步,他把机器翻译从平面结构建模引向了层次结构建模。
The Harvard Natural Language Processing Group
哈佛自然语言处理小组主要通过机器学习的方法处理人类语言,主要兴趣集中在数列生成的数学模型,以人类语言为基础的人工智能挑战以及用统计工具对语言结构进行探索等方面。该小组的研究出版物和开源项目集中在文本总结、神经机器翻译、反复神经网络的可视化、收缩神经网络的算法、文档中实体跟踪的模型、多模态文本生成、语法错误修正和文本生成的新方法等方面。Stuart Shieber 是该小组的主要负责人。
Stuart Shieber
James O. Welch, Jr. and Virginia B. Welch Professor of Computer Science
Faculty Director, Harvard Office for Scholarly Communication
Harvard University

Stuart Shieber,美国计算机协会(Association for Computing Machinery)Fellow 和美国人工智能协会(American Association for Artificial Intelligence)Fellow。他综合语言学、理论计算机科学、计算机系统以及人工智能等领域的知识,研究计算机语言学,从计算机科学的角度研究自然语言,在该领域的研究以科学和工程目标,以基础形式和数学工具为基础。具体研究领域包括计算语言学、数学语言学、基于语法的形式、自然语言生成、计算语义、机器翻译以及人机交互等。
Natural Language Processing group of Columbia University
哥伦比亚大学自然语言处理研究室是在计算机科学系、计算学习系统中心和生物医学信息系的支持下进行的,将语言洞察力与严谨前沿的机器学习方法和其他计算方法结合起来进行研究。在语言资源创造如语料库、词典等,阿拉伯语 NLP,语言和社交网络,机器翻译,信息提取,数据挖掘,词汇语义、词义消除歧义等方面有着比较深入的研究。现在该实验室计算机方面的主要负责人为 Michael Collins。
Michael Collins

Michael Collins,哥伦比亚大学计算机科学系教授,谷歌 NYC 研究科学家。1998 年在宾夕法尼亚大学获得计算机科学博士学位。主要研究兴趣是自然语言处理和机器翻译。多次在国际顶级会议上发表文章,例如在 EMNLP 2010,CoNLL 2008,UAL 2055 等会议上都获得最佳论文奖,同时还是 ACL 的研究员,获 NSF 生涯奖。
2、国内实验室及人才介绍
AMiner 基于论文数据整理了自然语言处理华人专家库,其中包括了来自 NUS、HKUS、THU、PKU、FDU 等知名高校以及百度、科大讯飞、微软等公司的 367 位专家学者。下面基于自然语言处理华人库中的数据对其进行分析。
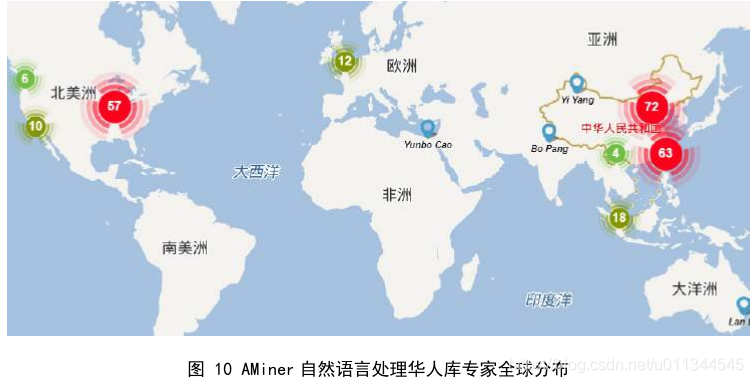
自然语言处理领域中华人专家在中国最多,美国次之。从地区来看,中国大陆是自然语言处理华人人才的最主要聚集地,尤其是北京、哈尔滨及东南沿海地区等具有自然语言处理学术基础的地区。美国东部和西部等其他地区排在其后。由图 11 可以看出,华人专家在中国流出量大于流入量,美国则正好相反,这也说明就自然领域而言,中国对人才的吸引力要小于美国。
AMiner 自然语言处理华人库中专家 h-index 指数的平均数为 14,这一数值是远远低于自然语言处理全球 top1000 学者 h-index 指数平均数的。而且,在华人库中,h-index 指数<10的专家人数最多,占比 60%;10-19 次之,占比 17%;>60 的专家占比仅占 9%。这也说明,自然语言处理的华人专家整体水平低于自然语言处理领域全球 top1000 的学者,尤其是在 h-index 指数>60 的学者方面有所欠缺。
AMiner 自然语言处理华人库 367 位专家中,男性专家占 98%,女性专家仅占 2%,二者比例约为 49:1。
以下选取在 ACL、EMNLP、NAACL、COLING 等 4 个会议在近 5 年累计发表 10 次以上论文的国内学者包括刘群、刘挺、周明、常宝宝、黄萱菁、刘洋、孙茂松、李素建、万小军、邱锡鹏、穗志方等。以下按照发表论文的多少为序,对这些学者及其所在实验室做简要介绍。
刘群
(来自百度百科)
中科院计算所自然语言处理研究组
刘群,中国科学院自然语言处理研究组组长,都柏林大学自然语言处理组组长、项目负责人。主要研究方向是中文自然语言处理,具体包括汉语词法分析、汉语句法分析、语义处理、统计语言模型、辞典和语料库、机器翻译、信息提取、中文信息处理和智能交互中的大规模资源建设、中文信息处理以及智能交互中的评测技术等。曾负责 863 重点项目“机器翻译新方法的研究”和“面向跨语言搜索的机器翻译关键技术研究”等。
自然语言处理研究组隶属于中国科学院计算技术研究所智能信息处理重点实验室。研究组教师有刘群、冯洋等人。研究组主要从事自然语言处理和机器翻译相关的研究工作,研究方向包括机器翻译、人机对话、多语言词法分析、句法分析和网络信息挖掘等。研究组已完成和正在承担的国家自然科学基金、863 计划、科技支撑计划、国际合作等课题 40 余项,在自然语言处理和机器翻译领域取得了多项创新性研究成果。研究组自 2004 年重点开展统计机器翻译方面的研究并取得重大突破,并于 2015 年起转向神经机器翻译并取得很大进展。2018 年 7 月,正式加入华为诺亚方舟实验室,任语音语义首席科学家,主导语音和自然语言处理领域的前沿研究和技术创新。
在自然语言处理的顶级国际刊物 CL、AI 和顶级国际学术会议 ACL、IJCAI、AAAI、EMNLP、COLING 上发表高水平论文 70 余篇,取得发明专利 10 余项。研究组已经成功将自主开发的统计机器翻译和神经机器翻译技术推广到汉语、维吾尔语、藏语、蒙古语、英语、韩语、泰语、日语、阿拉伯语等多种语言。部分语种的翻译系统已经在相关领域得到了实际应用,获得用户的好评。
刘挺
 (来自雷锋网)
(来自雷锋网)
刘挺,哈尔滨工业大学教授,国家“万人计划”科技创新领军人才。多次担任国家 863重点项目总体组专家、基金委会评专家。中国计算机学会理事,中国中文信息学会常务理事/社会媒体处理专委会(SMP)主任,曾任国际顶级会议 ACL、EMNLP 领域主席。主要研究方向为人工智能、自然语言处理和社会计算,是国家 973 课题、国家自然科学基金重点项目负责人。2012-2017 年在自然语言处理领域顶级会议发表的论文数量列世界第8 位(据剑桥大学统计),主持研制“语言技术平台 LTP”、“大词林”等科研成果被业界广泛使用。曾获国家科技进步二等奖、省科技进步一等奖、钱伟长中文信息处理科学技术一等奖等。
刘挺领导的 哈工大社会计算与信息检索研究中心:http://ir.hit.edu.cn/
https://github.com/HIT-SCIR/ltp
哈工大社会计算与信息检索研究中心(HIT-SCIR)成立于 2000 年 9 月,隶属于计算机科学与技术学院。研究中心成员有主任刘挺教授,副主任秦兵教授,教师包括张宇、车万翔、陈毅恒、张伟男等。研究方向包括语言分析、信息抽取、情感分析、问答系统、社会媒体处理和用户画像 6 个方面。已完成或正在承担的国家 973 课题、国家自然科学基金重点项目、国家 863 重点项目、国际合作、企业合作等课题 60 余项。在这些项目的支持下打造出“语言技术平台 LTP”,提供给百度、腾讯、华为、金山等企业使用,获 2010 年钱伟长中文信息处理科学技术一等奖。
研究中心近年来发表论文 100 余篇,其中在 ACL、SIGIR、IJCAI、EMNLP 等顶级国际学术会议上发表 20 余篇论文,参加国内外技术评测,并在国际 CoNLL’2009 七国语言句法语义分析评测总成绩第一名。研究中心通过与企业合作,已将多项技术嵌入企业产品中,为社会服务。双语例句检索等一批技术嵌入金山词霸产品中,并因此获得 2012 年黑龙江省技术发明二等奖。
周明

周明,微软亚洲研究院自然语言计算组的首席研究员,机器翻译和自然语言处理领域的专家。他的研究兴趣包括搜索引擎、统计和神经机器翻译、问答、聊天机器人、计算机诗歌和文本挖掘等。
1989 年,他设计了“CEMT-I 机器翻译系统”,这是汉英机器翻译的第一个实验,获得了中国大陆政府的科学技术进步奖。1998 年,他设计了著名的中日文机器翻译软件产品 J-Beijing,并获得了日本机械翻译协会 2008 年颁发的机器翻译产品的最高荣誉称号。
周明团队也为 Bing 搜索引擎提供了重要的技术支持,包括单词 breaker、情感分析、speller、解析器和 QnA 等 NLP 技术。他的团队创建了汉英、粤语的机器翻译引擎,为译者和 Skype 翻译。最近,周明团队与微软产品团队紧密合作,在中国(小冰)、日本(Rinna)和美国(Tay)创建了知名的 chat-bot 产品,拥有 4000 万用户。他在顶级会议(包括 45+ACL论文)和 NLP 期刊上发表并发表了 100 多篇论文,获得了 38 项国际专利。
周明所属实验室为**微软亚洲研究院自然语言计算组**
黄萱菁
黄萱菁,复旦大学计算机科学技术学院教授、博士生导师。在 SIGIR、ACL、ICML、IJCAI、AAAI、NIPS、CIKM、ISWC、EMNLP、WSDM 和 COLING 等多个国际学术会议上发表论文数十篇。
曾任 2014 年 CIKM 会议竞赛主席,2015 年 WSDM 会议组织者,2015 年全国社会媒体处理大会程序委员会主席,2016 年全国计算语言学会议程序委员会副主席,2017 年自然语言处理与中文计算国际会议程序委员会主席。
多次在人工智能、自然语言处理和信息检索的国际学术会议IJCAI、ACL、SIGIR、WWW、EMNLP、COLING、CIKM、WSDM 担任程序委员会委员和资深委员。兼任中国中文信息学会常务理事,社会媒体专委会副主任,中国计算机学会中文信息处理专委会委员,中国人工智能学会自然语言理解专委会委员,ACM 和 ACL 会员,《中文信息学报》编委,国家自然科学基金、教育部高校博士点基金和 863 计划同行评议专家。
黄萱菁领导的**复旦大学自然语言处理研究组**
复旦大学自然语言与信息检索实验室,致力于社会媒体海量多媒体信息处理的前沿技术研究。主要研究方向包括:自然语言处理、非规范化文本分析、语义计算、信息抽取、倾向性分析、文本挖掘等方面。实验室开发了 NLP 工具包 FudanNLP,FudanNLP 提供了一系列新技术,包括中文分词、词性标注、依赖解析、时间表达式识别和规范化等。实验室先后承担和参与了国家科技重大专项、国家 973 计划、863 计划、国家自然科学基金课题、上海市科技攻关计划等,并与国内外多所重点大学、公司保持着良好的合作关系。研究成果持续发表在国际权威期刊和一流国际会议(TPAMI、TKDE、ICML、ACL、AAAI、IJCAI、SIGIR、CIKM、EMNLP、COLING 等)。
孙茂松

孙茂松,清华大学计算机科学与技术系教授。2007-2010 年任该系系主任,主要研究领域为自然语言处理、互联网智能、机器学习、社会计算和计算教育学。国家重点基础研究发展计划(973 计划)项目首席科学家,国家社会科学基金重大项目首席专家。在国际刊物、国际会议、国内核心刊物上发表论文 160 余篇,主持完成文本信息处理领域 ISO 国际标准 2 项。2007 年获全国语言文字先进工作者,2016 年获全国优秀科技工作者以及首都市民学习之星。多次担任相关领域国际会议和全国性学术会议大会主席或程序委员会主席。
孙茂松领导的**清华大学自然语言处理与社会人文计算实验室**
清华大学计算机系自然语言处理课题组在 20 世纪 70 年代末,就在黄昌宁教授的带领下从事这方面的研究工作,是国内开展相关研究最早、深具影响力的科研单位,同时也是中国中文信息学会计算语言学专业委员会的挂靠单位。现任学科带头人孙茂松教授任该专业委员会的主任(同时任中国中文信息学会副理事长),其余教师还有刘洋、刘知远等人。目前该课题组对以中文为核心的自然语言处理中的若干前沿课题,进行系统、深入的研究,研究领域的涵盖面正逐步从计算语言学的核心问题扩展到社会计算和人文计算。该课题组多篇论文被 ACL 2018、IJCAI-ECAI 2018、WWW 2018 录用,内容涉及问答系统、信息检索、机器翻译、诗歌生成、查询推荐等多个领域。
万小军
万小军,北京大学计算机科学技术研究所教授,博士生导师,语言计算与互联网挖掘实验室负责人。研究方向为自然语言处理与文本挖掘,兴趣领域包括自动文摘与文本生成、情感分析与观点挖掘、语义计算与信息推荐等,在国际重要学术会议与期刊上发表高水平学术论文上百篇。担任计算语言学顶级国际期刊 Computational Linguistics 编委,TACL 常务评审委员(Standing Reviewing Committee),多次担任自然语言处理领域重要国际会议领域主席或SPC(包括 ACL、NAACL、IJCAI、IJCNLP 等),以及相关领域多个国际顶级学术会议(ACL、SIGIR、CIKM、EMNLP、NAACL、WWW、AAAI 等)程序委员会委员。研制了自动文摘开源平台 PKUSUMSUM,与今日头条合作推出 AI 写稿机器人小明(Xiaomingbot),与南方都市报合作推出写稿机器人小南等应用系统。
万小军所属实验室为**北京大学语言计算与互联网挖掘研究组**
语言计算与互联网挖掘研究室从属于北京大学计算机科学技术研究所,成立于 2008 年7 月,负责人为万小军老师。研究室以自然语言处理技术、数据挖掘技术与机器学习技术为基础,对互联网上多源异质的文本大数据进行智能分析与深度挖掘,为互联网搜索、舆情与情报分析、写稿与对话机器人等系统提供关键技术支撑,并从事计算机科学与人文社会科学的交叉科学研究。
研究室当前研究内容包括:1)语义理解:研制全新的语义分析系统实现对人类语言(尤其是汉语)的深层语义理解;2)机器写作:综合利用自动文摘与自然语言生成等技术让机器写出高质量的各类稿件;3)情感计算:针对多语言互联网文本实现高精度情感、立场与幽默分析;4)其他:包括特定情境下的人机对话技术等。
穗志方


穗志方,北京大学信息科学技术学院计算语言学实验室主任,教授、博士生导师。2011年度国家科技进步二等奖、“综合型语言知识库”项目第二完成人。长期从事自然语言处理方面的研究。在计算语言学国际顶级会议 ACL 2000、COLING 2008、CONLL 2008、ACL 2009、EMNLP2009、AIRS 2008 上发表多篇学术论文。作为课题负责人主持的科研项目有:国家自然科学基金项目“汉语动词子语类框架自动获取技术研究”、“基于结构化学习的语义角色标注研究”、“基于 Web 的概念实例及其属性值提取方法研究”,国家社科基金项目“面向文本内容提取的生成性组件库研究及建设”等。
穗志方所属实验室为**北京大学计算语言学教育部重点实验室**
计算语言学教育部重点实验室依托北京大学建设。实验室研究人员由北京大学信息科学技术学院计算语言学研究所、中文系、软件与微电子学院语言信息工程系、计算机技术研究所、心理系和外语学院的相关研究人员构成。主要研究方向包括:中文计算的基础理论与模型;大规模多层次语言知识库构建的方法;国家语言资源整理与语音数据库建设;海量文本内容分析与动态监控;多语言信息处理和机器翻译。
宗成庆

宗成庆,模式识别国家重点实验室研究员、博士生导师。主要从事自然语言处理、机器翻译和文本数据挖掘等相关领域的研究。主持国家自然科学基金项目、863 计划项目和重点研发计划重点专项等 10 余项,发表论文 150 余篇,出版专著和译著各一部。2013 年当选国际计算语言学委员会(ICCL)委员。目前担任亚洲自然语言处理学会(AFNLP)候任主席、中国中文信息学会副理事长、学术期刊 ACM TALLIP 副主编(AssociateEditor)、《自动化学报》副主编、IEEE Intelligent Systems 编委、MachineTranslation 编委和JCST 编委。2013 年获国务院颁发的政府特殊津贴,2014 年获“钱伟长中文信息处理科学技
术奖”一等奖,2015 年获国家科技进步奖二等奖,2017 年获北京市优秀教师荣誉称号。
赵军

赵军,中科院研究员,博士生导师。1998 年在清华大学计算机科学与技术系获得博士学位。1998 年-2002 年在香港科技大学计算机科学系做博士后、访问学者。2002 年 5 月至今在中科院自动化所模式识别国家重点实验室工作。主持国家自然科学基金重点项目、973 计划等国家级项目。研究方向为信息提取和问答系统等。在 IEEE TKDE、JMLR 等顶级国际期刊和 ACL、SIGIR、EMNLP、COLING 等顶级国际会议上发表论文六十余篇,获 COLING-2014 最佳论文奖,获 KDD-CUP2011 亚军(2/1297)。研发了汉语文本分析、信息抽取和知识工程、百科问答等软件工具和平台,在中国大百科全书出版社、华为公司、讯飞公司等得到应用。
宗成庆和赵军所属实验室为中科院模式识别国家重点实验室
中科院模式识别国家重点实验室自然语言处理组主要成员有宗成庆、赵军、周玉、刘康、张家俊、汪昆、陆征等。该小组主要从事自然语言处理基础、机器翻译、信息抽取和问答系统等相关研究工作,力图在自然语言处理的理论模型和应用系统开发方面做出创新成果。目前研究组的主要方向包括:自然语言处理基础技术(汉语词语切分、句法分析、语义分析和篇章分析等)、多语言机器翻译、信息抽取(实体识别、实体关系抽取、观点挖掘等)和智能问答系统(基于知识库的问答系统、知识推理、社区问答等)。
近年来,研究组注重于自然语言处理基础理论和应用基础的相关研究,承担了一系列包括国家自然科学基金项目、973 计划课题、863 计划项目和支撑计划项目等在内的基础研究和应用基础研究类项目,以及一批企业应用合作项目。在自然语言处理及相关领域顶级国际期刊(CL、TASLP、TKDE、JMLR、TACL、Information Sciences、Intelligent Systems 等)和学术会议(AAAI、IJCAI、ACL、SIGIR、WWW 等)上发表了一系列论文。2009 年获得第 23 届亚太语言、信息与计算国际会议(PACLIC)最佳论文奖,2012 年获得第一届自然语言处理与中文计算会议(NLPCC)最佳论文奖,2014 年获得第 25 届国际计算语言学大会(COLING)最佳论文奖。获得了 10 余项国家发明专利。
国内学者在国际会议获得 Best paper 的有以下两个:
Pengcheng Yang 、 Xu Sun 、 Wei Li 、 Shuming Ma 、 Wei Wu 、 Houfeng Wang 的 SGM:
Sequence Generation Model for Multi-label Classification 在 2018 COLING 会议中被评为 Best
error analysis 和 Best evaluation。
王厚峰

王厚峰,北京大学信息科学技术学院教授,北京大学计算语言学研究所所长。主要研究兴趣包括情感分析、问答与会话、自然语言语言语篇分析等,曾作为首席专家主持过国家 863项目、国家社科基金重大项目,负责国家自然科学基金重大研究计划等。在 ACL、EMNLP、COLING、AAAI、IJCAI、ICML 等会议以及 Computational Linguistics 等期刊发表论文 70 余篇。
Fan Bu、Xiaoyan Zhu、Ming Li 等的 Measuring the Non-compositionality of MultiwordExpressions 在 2010 年 COLING 会议上被评为 best paper。

朱小燕
朱小燕,清华计算机系教授,博士生导师,智能技术与系统国家重点实验室主要负责人。
主要研究领域为智能信息处理,其中包括:模式识别、神经元网络、机器学习、自然语言处理、信息提取和智能问答系统等。近年研究工作主要集中于生物领域文本信息处理和新一代智能信息获取的研究。作为项目负责人先后承担国家 863,973 项目,自然科学基金项目、国际合作项目多项。
1997 年获国家教委科技进步二等奖,2003 年获北京市科技进步二等奖。获得国家发明专利3项。在各种国际刊物和会议上发表论文近100篇。其中包括国际刊物Genome Biology,Bioinformatics、BMC Bioinformatics、Medical informatics、IEEE Transactions.on SMC、IEEElectronics Letters、Neural Parallel & Science Computations、Document Analysis and Recognition,以及国际会议 SIG KDD、ACL、COLING、CIKM 等。
朱小燕所属实验室为 清华大学智能技术与系统国家重点实验室
智能技术与系统国家重点实验室依托在清华大学,1987 年 7 月开始筹建。1990 年 2 月通过国家验收,并正式对外开放运行。从 1990 年至 2003 年这十三年间,实验室顺利通过国家自然科学基金委受科技部委托组织的全部三次专家组评估,并被评估为 A(优秀实验室)。1994 年 10 月在庆祝国家重点实验室建设十周年表彰大会上,智能技术与系统国家重点实验室获集体“金牛奖”。1997 年被科技部列为试点实验室。2004 年庆祝国家重点实验室建设二十周年表彰大会上,本实验室再次荣获集体“金牛奖”。从 2004 年开始,实验室参与筹建清华信息科学与技术国家实验室。实验室学术委员会由 17 名国内外著名专家组成。实验室学术委员会名誉主任为中科院院士张钹教授,主任为应明生教授、副主任为邓志东教授。
除此之外,活跃在自然语言领域的中国学者还有:
周国栋
周国栋,苏州大学计算机科学与技术学院教授,苏州大学 NLP 实验室负责人。主要研究兴趣是自然语言处理、中文计算、信息抽取和自然语言认知等。自 1999 年起,一直是 ACM、ACL、IEEE computer society 的会员,负责了多项国家 863 项目、国家重点研究项目等。近 5 年来发表国际著名 SCI 期刊论文 20 多篇和国际顶级会议论文 80 多篇,主持 NSFC项目 4 个(包括重点项目 1 个)。曾担任国际自然语言理解领域顶级 SCI 期刊 ComputationalLinguistics 编委,目前担任 ACM TALLIP 副主编、《软件学报》责任编委、CCF 中文信息技术专委会副主任委员、苏州大学校学术委员会委员。
李涓子
李涓子,清华大学教授,博士生导师。中国中文信息学会语言与知识计算专委会主任、中国计算机学会术语委员会执行委员。研究兴趣是语义 Web,新闻挖掘与跨语言知识图谱构建。多篇论文发表在重要国际会议(WWW、IJCAI、SIGIR、SIGKDD)和学术期刊(TKDE、TKDD)。主持多项国家级、部委级和国际合作项目研究,包括国家自然科学项目重点,欧盟第七合作框架、新华社等项目。获得 2013 年人工智能学会科技进步一等奖,2013 年电子学会自然科学二等奖。
张民
张民,苏州大学计算机科学与技术学院副院长。2003 年 12 月,他加入新加坡信息通信研究所并于 2007 年在研究所建立了统计机器翻译团队。2012 年加入苏州大学,并于 2013年在该大学成立智能计算研究所。
目前的研究兴趣包括机器翻译、自然语言处理、信息提取、社交网络计算、互联网智能、智能计算和机器学习。近年来在国际顶级学报和顶级会议发表学术论文 150 余篇,Springer出版英文专著两部,主编 Springer 和 IEEE CPS 出版英文书籍十本。他一直积极地为研究界做贡献,组织多次会议并在许多会议和讲座中进行演讲。
黄河燕
黄河燕,语言智能处理与机器翻译领域专家,北京理工大学计算机学院院长、教授,北京市海量语言信息处理与云计算应用工程技术研究中心主任。长期从事语言智能处理的理论及应用研究,主持多项国家自然科学基金重点项目、国家重点研发计划项目、973 计划课题等重要科研项目,曾获国家科技进步一等奖、二等奖等奖项,被授予“全国优秀科技工作者”称号。
孙乐
孙乐,中国科学院软件研究所,研究员,博士生导师。中国中文信息学会副理事长兼秘书长。《中文信息学报》副主编。2003 至 2005 年,先后在英国 Birmingham 大学、加拿大Montreal 大学做访问学者,从事语料库和信息检索研究。目前主要研究兴趣:基于知识的语言理解、信息抽取、问答系统、信息检索等。在国内外主要刊物和会议上共发表论文 80 多篇。曾任 2008 和 2009 国际测评 NTCIR MOAT 中文
简体任务的组织者、国际计算语言学大会(COLING 2010)组织委员会联席主席、机器翻译峰会(MT Summit 2011)组织委员会联席主席、中文语言评测国际会议(CLP2010、2012、2014)大会主席、国际计算语言学年会(ACL 2015)组织委员会联席主席等。
3、ACL2018奖项介绍
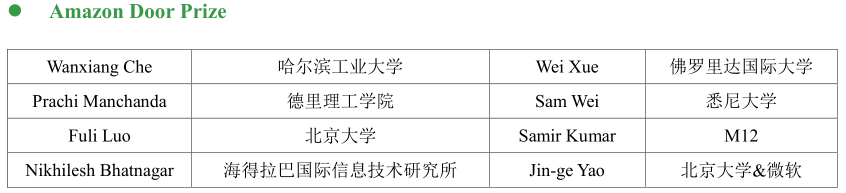
2018 年 7 月 15 在墨尔本开幕的 ACL 公布了其最佳论文名单,包括 3 篇最佳长论文和2 篇最佳短论文以及 1 篇最佳 demo 论文,值得一提的是 Amazon Door Prize 中北京大学和哈尔滨大学上榜,ACL2018 终身成就奖为爱丁堡大学 Mark Steedman 获得。
最佳长论文:
Finding syntax in human encephalography with beam search
用波束搜索在人脑成像中寻找句法
作者:John Hale,Chris Dyer,Adhiguna Kuncoro,Jonathan R.Brennan
论文摘要:循环神经网络文法(RNNGs)是对于树-字符串对的生成式模型,它们依靠神经网络来评价派生的选择。用束搜索对它们进行解析可以得到各种不同复杂度的评价指标,比如单词惊异数(word surprisal count)和解析器动作数(parser action count)。当把它们用作回归因子,解析人类大脑成像图像中对于自然语言文本的电生理学响应时,它们可以带来两个增幅效果:一个早期的峰值以及一个类似 P600 的稍迟的峰值。相比之下,一个不具有句法结构的神经语言模型无法达到任何可靠的增幅效果。通过对不同模型的对比,早期峰值的出现可以归功于 RNNG 中的句法组合。结果中体现出的这种模式表明 RNNG+束搜索的组合可以作为正常人类语言处理中的语法处理的一个不错的机理解释模型。
论文地址:https://arxiv.org/abs/1806.04127
Learning to Ask Good Questions: Ranking Clarification Questions using Neural
Expected Value of Perfect Information
学习如何问好的问题:通过完全信息下的期待值为追问问题排序
作者:Sudha Rao,Hal Daumé III
论文摘要:在沟通中,提问是一大基本要素:如果机器不知道如何问问题,那它们也就无法高效地与人类合作。在这项研究中,作者们构建了一个神经网络用于给追问的问题做排名。作者们模型设计的启发来源于完全信息情况下的期待值:一个可以期待获得有用的答案的问题就是一个好问题。作者们根据 StackExchange 上抓取的数据研究了这个问题;StackExchange 是一个内容丰富的在线咨询平台,其中有人发帖咨询以后,别的用户会在下面追问起到解释澄清作用的问题,以便更好地了解状况、帮助到发帖人。论文作者们创建了一个由这样的追问问题组成的数据集,其中包含了 StackExchange 上 askubuntu、unix、superuser 这三个领域的约 77k 组发帖+追问问题+问题的回答。作者们在其中的 500 组样本上评估了自己的模型,相比其他基准模型有显著的提高;同时他们也与人类专家的判断进行了对比。
论文地址:https://arxiv.org/abs/1805.04655
Let’s do it “again”: A First Computational Approach to Detecting Adverbial
Presupposition Triggers
让我们“再”做一次:首个检测假定状态触发副词的计算性方法
作者:Andre Cianflone,Yulan Feng,Jad Kabbara,Jackie Chi Kit Cheung
论文摘要:这篇论文中,作者们介绍了一种新的研究课题——预测副词词性的假定状态触发语(adverbial presupposition triggers),比如 also 和 again。完成这样的任务需要在对话上下文里寻找重复出现的或者相似的内容;这项任务的研究成果则可以在文本总结或者对话系统这样的自然语言生成任务中起到帮助。作者们为这项任务创造了两个新的数据集,分别由 Penn Treebank 和 AnnotatedEnglish Gigaword 生成,而且也专为这项任务设计了一种新的注意力机制。作者们设计的注意力机制无需额外的可训练网络参数就可以增强基准 RNN 模型的表现,这最小化了这一注意力机制带来的额外计算开销。作者们在文中表明,他们的模型相比多个基准模型都有统计显著的更高表现,其中包括基于 LSTM 的语言模型。
论文地址:https://www.cs.mcgill.ca/~jkabba/acl2018paper.pdf
最佳短论文
Know What You Don’t Know: Unanswerable Questions for SQuAD
知道你不知道的:SQuAD 中无法回答的问题
作者:Pranav Rajpurkar,Robin Jia,Percy Liang
论文摘要:提取式的阅读理解系统一般都能够在给定的文档内容中找到正确的内容来回答问题。不过对于正确答案没有明示在阅读文本中的问题,它们就经常会做出不可靠的猜测。目前现有的阅读理解问答数据集,要么只关注了可回答的问题,要么使用自动生成的无法回答的问题,很容易识别出来。为了改善这些问题,作者们提出了 SQuAD2.0 数据集,这是斯坦福问答数据集 SQuAD 的最新版本。SQuAD2.0 在现有的十万个问题-答案对的基础上增加了超过五万个无法回答的问题,它们由人类众包者对抗性地生成,看起来很像可以回答的问题。一个问答系统如果想要在 SQuAD2.0 上获得好的表现,它不仅需要在问题能够回答时给出正确的答案,还要在给定的阅读材料中不包含答案时做出决定、拒绝回答这个问题。
SQuAD2.0 也设立了新的人类表现基准线,EM86.831,F189.452。对于现有模型来说SQuAD2.0 是一个具有挑战性的自然语言理解任务,一个强有力的基于神经网络的系统可以在 SQuAD1.1 上得到 86%的 F1 分数,但在 SQuAD2.0 上只能得到 66%。
论文地址:https://arxiv.org/abs/1806.03822
‘Lighter’ Can Still Be Dark: Modeling Comparative Color Descriptions
“更浅的颜色”也可能仍然是黑暗的:建模比较性的颜色描述
作者:Olivia Winn,Smaranda Muresan
论文摘要:我们提出了一种在颜色描述领域内建立基准比较性形容词的新范式。给定一个参考 RGB 色和一个比较项(例如更亮、更暗),我们的模型会学习建立比较项的基准,将其作为 RGB 空间中的一个方向,这样颜色就会沿着向量植根于比较色中。我们的模型产生了比较形容词的基本表示形式,在期望的改变方向上,平均精确度为 0.65 余弦相似性。与目标颜色相比,依据向量的颜色描述方法 Delta-E 值小于 7,这表明这种方法与人类感知的差异非常小。这一方法使用了一个新创建的数据集,该数据集来自现有的标记好的颜色数据。
论文地址:http://aclweb.org/anthology/P18-2125
最佳 demo 论文
Out-of-the-box Universal Romanization Tool
开箱即用的通用罗马化工具
作者:Ulf Hermjakob,Jonathan May,Kevin Knight
论文摘要:我们想介绍 uroman,这个工具可以把五花八门的语言和文字(如中文、阿拉伯语、西里尔文)转换为普通拉丁文。该工具基于 Unicode 数据以及其他表,可以处理几乎所有的字符集(包括一些晦涩难懂的语言比如藏文和提非纳文)。uroman 还可以将不同文本中的数字转换为阿拉伯数字。罗马化让比较不同文本的字符串相似性变得更加容易,因为不再需要将两种文字翻译成中间文字再比较。本工具作为一个 Perl 脚本,可以免费提供,可用于数据处理管道和交互式演示网页。
论文地址:http://aclweb.org/anthology/P18-4003
ACL 终身成就奖由 Mark Steedman 获得。
Mark Steedman 出生于 1946 年,1968 年毕业于苏塞克斯大学(University of Sussex),1973 年,获得爱丁堡大学人工智能博士学位(论文:《音乐知觉的形式化描述》)。此后,他曾担任华威大学心理学讲师,爱丁堡大学计算机语言学讲师,宾夕法尼亚大学计算机与信息科学学院副教授,也曾在德克萨斯大学奥斯汀分校,奈梅亨马克斯普朗克心理语言研究所和费城宾夕法尼亚大学担任过访问学者。
目前他任爱丁堡大学信息学院认知科学系主任,主要研究领域有计算语言学、人工智能和认知科学、AI 会话的有意义语调生成、动画对话、手势交流以及组合范畴语法(Combinatorycategorial grammar,CCG)等。此外,他对计算音乐分析和组合逻辑等领域也很感兴趣。