



由于
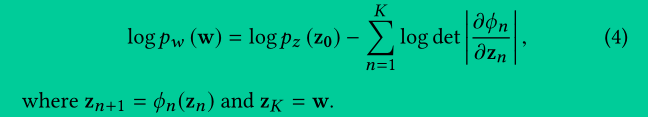

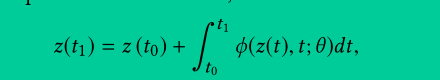
这个公式的含义是:变量 z 在时间 t1 的值,等于变量 z 在时间 t0 的值,加上从时间 t0 到时间 t1 之间变量 z 的变化量的积分。变量 z 的变化量由函数 ϕ 决定,函数 ϕ 取决于变量 z 、时间 t 和神经网络的参数 θ 。这个公式可以用来求解常微分方程 dz dt = ϕ(z(t),t;θ) ,也就是 CNFs 的变换函数。

变量 z 在时间 t1 的概率密度的对数,等于变量 z 在时间 t0 的概率密度的对数,减去从时间 t0 到时间 t1 之间,函数 ϕ 对变量 z 的偏导数矩阵的迹的积分。函数 ϕ 对变量 z 的偏导数矩阵是雅克比矩阵,其迹是对角线元素之和(这个公式可以用来计算 CNFs 的变换后的概率密度和对数似然)
其中Tr(***/***)所代表的含义:
函数 ϕ 对变量 z 的偏导数矩阵的迹,即矩阵的对角线元素之和。函数 ϕ 对变量 z 的偏导数矩阵是雅克比矩阵,雅克比矩阵的迹表示变量 z 的总变化率。
训练目标:![]()
论文中的属性转换模型的训练目标是最大化给定一组属性a_t时数据w的似然,即数据w在属性a_t下的概率¹。最大化似然的目的是让模型能够更好地拟合目标分布,即能够生成具有目标属性a_t的高质量图像¹。论文中使用了正则化流模型来实现这个目标,即通过一个可逆的变换函数,将StyleGAN的潜在空间W+映射到一个简单的高斯分布,并且可以计算样本的对数密度²。论文中使用了Hutchinson's trace estimator来估计对数密度,因为直接计算对数密度在高维空间中是不可行的¹。论文中发现,属性转换模型的对数密度随着训练轮数(epoch)的增加而增加,说明模型在不断地学习目标分布¹。
训练算法:
log N(z0 ; 0, I ): z0在分布N(0, I)下的对数似然度。(对数似然度用于度量输入数据在某个模型对应的条件分布下的实际可能性。)
