一、简介
Network in Network,描述了一种新型卷积神经网络结构。 LeNet,AlexNet,VGG都秉承一种设计思路:先用卷积层构成的模块提取空间特征,再用全连接层模块来输出分类结果。这里NIN提出了一种全新的思路:由多个由卷积层+全连接层构成的微型网络(mlpconv)来提取特征,用全局平均池化层来输出分类。这种思想影响了后面一系列卷积神经网络的设计。

论文链接:[1312.4400] Network In Network (arxiv.org)
该网络的亮点在于:
NIN由三个mplconv层 + 一个GAP全局平均池化层组成
微型网络mplconv,内部由多层感知机实现(其中包含1个可调整大小的conv层+2个1×1的卷积层),mpl中感知机层数是可以调整的,也可以被用在卷积层之间,个数随需调整。
NIN网络用微型网络mlpconv层代替了传统的卷积层;用GAP代替了传统CNN模型中末尾的全连接层。
二、详解
1 . MLP由来
传统卷积层和MLP比较
以往CNN中的卷积滤波器是一种通用线性模型(generalized linear model ,即GLM),抽象的能力较低,用更有效的非线性函数逼近器代替GLM可以增强局部模型的抽象能力。这里的抽象能力高,是指当输入有局部变化时,输出特征保持不变。
在NiN中,GLM被一种“微型网络”结构替代,这种微型网络是一种通用非线性函数逼近器。论文中的微型网络用多层感知机实现,故这种微型神经网络也被称为mplconv layer,其不仅是一个通用的函数逼近器,还可以通过反向传播进行计算。函数逼近器的概念即利用函数去逼近和拟合一组数据的分布,譬如一组数据大致呈现直线状分布,y = kx + b即可作为一个函数逼近器,一组数据呈现抛物线状,可用y = kx^2 + b作为逼近器,其与线性卷积层的对比如图b所示
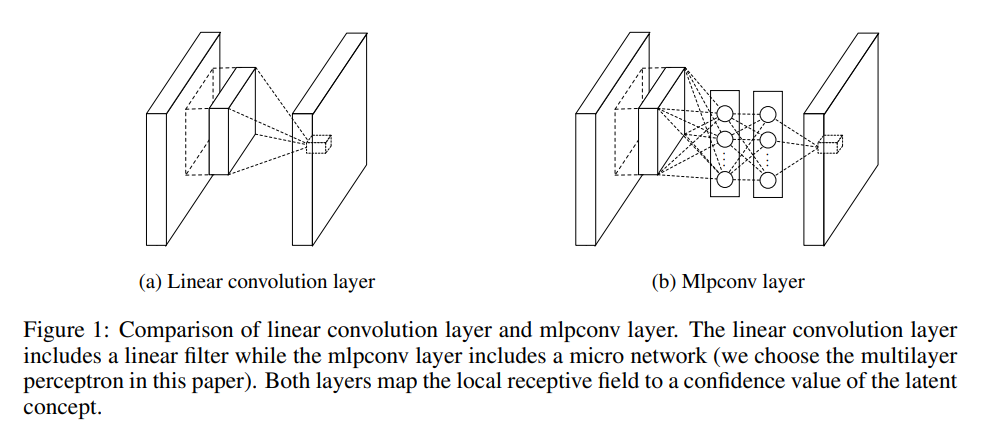
注:图b中类似全连接的部分其实就是大小为1x1的卷积层。
为什么使用MLP卷积层 ?
经典的卷积神经网络由交替堆叠的卷积层和空间池化层组成。卷积层通过线性卷积filter生成特征图,然后经过非线性激活函数(整流器、sigmoid、tanh等)处理。经典的卷积过程
这里作者提到(1.Introduction中也提及),当潜在的待分类图像是线性可分时,通常这类卷积计算是没问题的,但当目标抽象度较高,这类线性函数逼近器就无法较好的工作,于是在卷积后通常加上relu等非线性激活单元来提高非线性部分来提高非线性。
当潜在特征的实例是线性可分的时,CNN的线性卷积是可以胜任的。然而,实现良好抽象通常意味着输入数据的高度非线性。在传统的CNN中,可以通过大量使用filter来捕捉特征的不同变体,不过针对单个特征实例使用大量filter会给下一层的计算打来很大开销(因为下一层的特征往往较大,而它需要综合和计算来自上一层特征的所有变化组合)。基于此,作者认为在将每个局部特征组合成更高级特征之前,对其进行更好的抽象将是有益的。于是通过在网络结构中引入微型网络(MLP)来实现这一点,MLP的作用即为局部特征块提取出更抽象的特征,从而在送入下一层之前,增加抽象性。
2 . MLP结构
最初的NiN结构是在AlexNet后不久提出的,结构和训练方式与AlexNet相似。
论文结构如图所示:
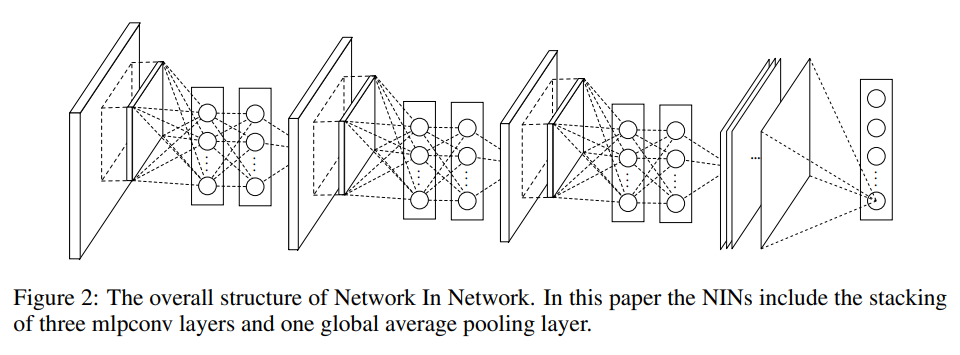
mlpconv的计算过程如下:
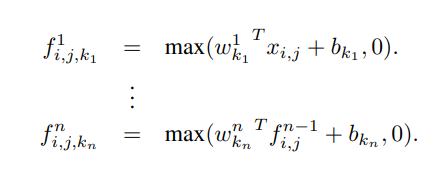
n表示MLP的layer层数,MLP中同样用线性整流单元(relu)做激活函数。
从跨通道池化的角度来看,公式等效于在正常卷积层上进行级联跨通道参数池化。每个池化层在输入的特征图上进行加权线性重组,然后通过relu,特征在一层层的跨通道池化中被交叉重组,使得各channel上的特征可跨通道交互和互相学习。这样的结构等价于1×1卷积(同样可以合并多通道,使得各channel上的参数可交互),故在代码实现中mlpconv中的全连接层,也可以用1×1的conv层来等价代替。
具体实现代码时的结构如图所示:
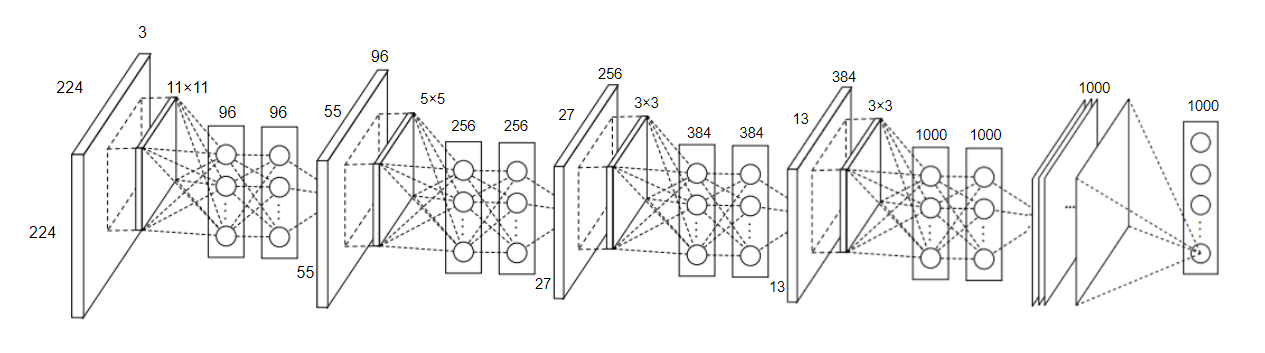
如图,是一个NIN的结构,包括4个mplconv层 + 1个全局平均池化层,一个mplconv中是一个3层的感知机(1卷积层+2个1x1的卷积层) 作者表示,mpl中感知机层数是可以调整的,同样mlpconv层作为一个微型网络结构,也可以被用在卷积层之间,个数随需调整。
NiN 使用卷积窗口形状分别为 11×11 、 5×5 和 3×3 的卷积层,相应的输出通道数也与 AlexNet 中的一致。
每个 NiN 块后接一个步幅为 2 、窗口形状为 3×3 的最大池化层。
NiN 使用了输出通道数等于标签类别数的 NiN 块,然后使用全局平均池化层对每个通道中所有元素求平均并直接用于分类。
3 . 全局平均池化GAP
传统CNN结构中卷积层后跟着的是全连接层然后经softmax层输出分类,最后的全连接层有增加过拟合的风险;这里作者将全连接层替换成了GAP全局平均池化层。 作者在论文中表面,用GAP替换了传统FC层主要有两点优势:
1.增强了特征映射和类别之间的对应关系,更符合卷积的结构,因此特征图就更容易对应上最后要输出分类的类别置信度;
2.没有了全连接层,减少了大量需要学习的参数,也避免了FC层过拟合的发生。
此外,全局平均池化汇总了空间信息,因此对输入特征的空间转换更加加健壮。
三、网络搭建
使用pytorch搭建NIN并训练花分类数据集
以下代码为自己借鉴并拼凑,可以正常运行
1. model.py
这里因为原本的 GlobalAvlPool2d全局平均池化GAP不能正常使用,于是将其替换为自适应平均池化
import torch
from torch import nn
# class GlobalAvlPool2d(nn.Module):
# def __init__(self):
# super().__init__()
# def forward(self, x):
# return nn.functional.avg_pool2d(x, (x.shape[2], x.shape[3]))
class NiN(nn.Module):
def __init__(self,num_classes,init_weights=False):
super(NiN, self).__init__()
self.net = nn.Sequential(
self.NiN_block(3, 96, 11, 4, 2), # input[3, 224, 224] # output[96, 55, 55]
nn.MaxPool2d(kernel_size=3, stride=2),
self.NiN_block(96, 256, 5, 1, 2), # output[256, 27, 27]
nn.MaxPool2d(kernel_size=3, stride=2),
self.NiN_block(256, 384, 3, 1, 1), # output[284, 13, 13]
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Dropout(0.5),
self.NiN_block(384, num_classes, 3, 1, 1),
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten()
)
if init_weights: #初始化权重,当初始化时设置为true,就会使用这个函数
self._initialize_weights()
def NiN_block(self,in_channels, out_channels, kernel_size, stride, padding):
nin = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding),
nn.ReLU(),
nn.Conv2d(in_channels=out_channels, out_channels=out_channels, kernel_size=1, stride=1),
nn.ReLU(),
nn.Conv2d(in_channels=out_channels, out_channels=out_channels, kernel_size=1, stride=1),
nn.ReLU()
)
return nin
def forward(self,x):
return self.net(x)
def _initialize_weights(self):
for m in self.modules(): #遍历self.modules模块,继承自nn.Module,会遍历我们定义的每一个层结构
if isinstance(m, nn.Conv2d): #isinstance函数用来比较得到的层结构是否等于给定的类型,是卷积层时,则使用凯明初始化
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear): #如果传进来的是全连接层
nn.init.normal_(m.weight, 0, 0.01) #通过正态分布对权重赋值,均值为0,方差为0.01
nn.init.constant_(m.bias, 0)
def test_output_shape(self):
test_img = torch.rand(size=(1, 3, 227, 227), dtype=torch.float32)
for layer in self.net:
test_img = layer(test_img)
print(layer.__class__.__name__, 'output shape: \t', test_img.shape)
# net = NiN()
# print(net)其结构如下:
NiN(
(net): Sequential(
(0): Sequential(
(0): Conv2d(1, 96, kernel_size=(11, 11), stride=(4, 4))
(1): ReLU()
(2): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1))
(3): ReLU()
(4): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1))
(5): ReLU()
)
(1): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): Sequential(
(0): Conv2d(96, 256, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): ReLU()
(2): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(3): ReLU()
(4): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(5): ReLU()
)
(3): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Sequential(
(0): Conv2d(256, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(384, 384, kernel_size=(1, 1), stride=(1, 1))
(3): ReLU()
(4): Conv2d(384, 384, kernel_size=(1, 1), stride=(1, 1))
(5): ReLU()
)
(5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Dropout(p=0.5)
(7): Sequential(
(0): Conv2d(384, 10, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(10, 10, kernel_size=(1, 1), stride=(1, 1))
(3): ReLU()
(4): Conv2d(10, 10, kernel_size=(1, 1), stride=(1, 1))
(5): ReLU()
)
(8): GlobalAvlPool2d()
)
)2. train.py
训练代码和之前类似,
import os
import json
import sys
import torch
from torch import nn
from torch import optim
from torch.utils.data import DataLoader
from torchvision import transforms, datasets
from tqdm import tqdm
from model import NiN
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
data_transform = {
'train': transforms.Compose([transforms.RandomResizedCrop(size=224),
transforms.RandomHorizontalFlip(p=0.5),
#transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
'val': transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
data_root = os.path.abspath(os.path.join(os.getcwd(), "../")) # os.getcwd()获取当前文件所在的目录,两个点表示返回上一层目录,os.path.join将后面两个路径连起来
image_path = os.path.join(data_root, "data_set1", "flower_data") # flower data set path
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"), #加载数据集,训练集
transform=data_transform["train"]) #数据预处理
train_num = len(train_dataset) #通过len函数打印训练集有多少张图片
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx #获取每一种类别对应的索引
cla_dict = dict((val, key) for key, val in flower_list.items()) #遍历刚刚获得的字典,将key和val反过来
# write dict into json file
json_str = json.dumps(cla_dict, indent=4) # 将cla_dict编码为json格式
with open('class_indices.json', 'w') as json_file: #方便预测时读取信息
json_file.write(json_str)
batch_size = 4
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset, #加载数据
batch_size=batch_size,
shuffle=True, #随机数据
num_workers=nw) #线程个数,windows为0
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"), #载入测试集
transform=data_transform["val"]) #预处理函数
val_num = len(validate_dataset) #统计测试集的文件个数
validate_loader = torch.utils.data.DataLoader(validate_dataset, #加载数据
batch_size=4, shuffle=False,
num_workers=nw)
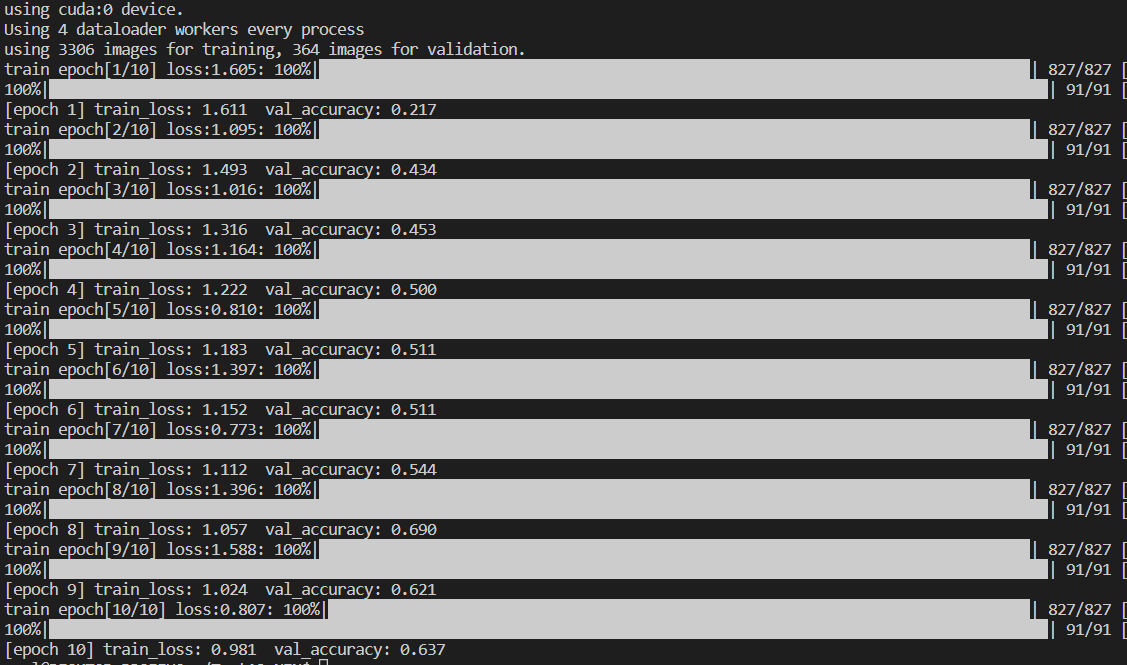
print("using {} images for training, {} images for validation.".format(train_num,
val_num))
net = NiN(num_classes=5, init_weights=True)
net.to(device)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0002)
epochs = 10
save_path = './NIN.pth'
best_acc = 0.0 #最佳准确率
train_steps = len(train_loader)
for epoch in range(epochs):
# train
net.train() #只希望在训练过程中随机失活参数,所以通过net.train()和net.eval()管理dropout方法,这样还可以管理BN层
running_loss = 0.0 #统计训练过程中的平均损失
train_bar = tqdm(train_loader, file=sys.stdout)
for step, data in enumerate(train_bar): #遍历数据集
images, labels = data #分为图像和标签
optimizer.zero_grad() #清空之前的梯度信息
outputs = net(images.to(device)) #正向传播,指定设备
loss = loss_function(outputs, labels.to(device)) #计算预测值和真实值的损失
loss.backward() #反向传播到每一个节点中
optimizer.step() #更新每一个节点的参数
# print statistics
running_loss += loss.item() #累加loss
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad(): #禁止pytroch对参数进行跟踪,在验证时不会计算损失梯度
val_bar = tqdm(validate_loader, file=sys.stdout)
for val_data in val_bar: #遍历验证集
val_images, val_labels = val_data
outputs = net(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1] #输出最大值设置为预测值
acc += torch.eq(predict_y, val_labels.to(device)).sum().item() #预测标签和真实标签对比,计算预测正确的个数
val_accurate = acc / val_num #测试集的准确率
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc: #当前的大于历史最优的
best_acc = val_accurate #赋值
torch.save(net.state_dict(), save_path) #保存权重
if __name__ == '__main__':
main()
3. predict.py
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from model import NiN
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# load image
img_path = "../tulip.jpg"
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img) #预处理时自动将channel换到第一个维度
# expand batch dimension
img = torch.unsqueeze(img, dim=0) #添加batch维度
# read class_indict
json_path = './class_indices.json' #读取类别文件
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
with open(json_path, "r") as f:
class_indict = json.load(f) #解码成需要的字典
# create model
model = NiN(num_classes=5).to(device) #初始化
# load model weights
weights_path = "./NIN.pth"
assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)
model.load_state_dict(torch.load(weights_path)) #载入网络模型
model.eval() #进入eval,关闭掉dropout方法
with torch.no_grad(): #让pytroch不去跟踪损失梯度
# predict class
output = torch.squeeze(model(img.to(device))).cpu() #正向传播,通过squeeze将batch维度压缩掉
predict = torch.softmax(output, dim=0) #通过softmax将输出变为概率分布
predict_cla = torch.argmax(predict).numpy() #通过argmax获得概率最大处的索引值
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
plt.title(print_res)
for i in range(len(predict)):
print("class: {:10} prob: {:.3}".format(class_indict[str(i)],
predict[i].numpy()))
plt.show()
if __name__ == '__main__':
main()训练结果:最高达到了0.69
参考: