前言
本文隶属于专栏《大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见大数据技术体系
目录
Spark SQL 工作流程源码解析(一)总览(基于 Spark 3.3.0)
Spark SQL 工作流程源码解析(二)parsing 阶段(基于 Spark 3.3.0)
Spark SQL 工作流程源码解析(三)analysis 阶段(基于 Spark 3.3.0)
Spark SQL 工作流程源码解析(四)optimization 阶段(基于 Spark 3.3.0)
Spark SQL 工作流程源码解析(五)planning 阶段(基于 Spark 3.3.0)
关联
Spark 3.x 版本的 Table Catalog API 是怎样的?
Spark DataSource API v2 版本有哪些改进?v1 版本和 v2 版本有什么区别?
我们要做什么?
通过前面的学习,我们很容易就发现:
parsing 阶段要做的事情就是将SQL语句转化成 AST,它实际上只和 SQL语句 有关,也就是说,相同的SQL语句,最终生成的 AST 应该都是相同的。
而 analysis 阶段要做的就是对生成的 AST 进行进一步的解析,毕竟 之前生成的 AST 只是 SQL 语句转化来的,而在不同的环境下 SQL 语句能达成的效果也是不尽相同的,此时我们要做的就是因地制宜。
怎么因地制宜呢?
首先要明白我们有了哪些东西?我们才能根据我们手头上的东西来通盘考虑。
我们有了什么?
经过 parsing 阶段之后,我们得到了一个 AST:
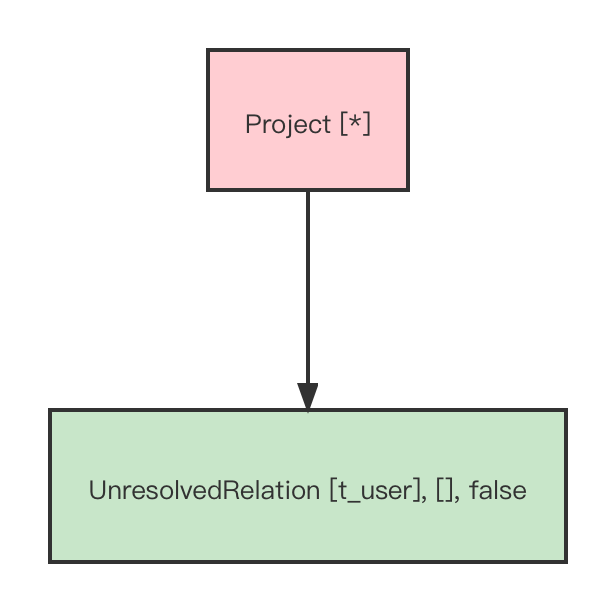
此外,我们之前有了一套配置环境:
val spark = SparkSession.builder.master("local[*]").appName("SparkSQLExample").getOrCreate()
我们还准备了数据源和 schema
数据源来自这里:
val df = spark.read.json(DATA_PATH)
schema 信息来自这里:
df.createTempView("t_user")
我们看看上面的代码能带给我们什么关键信息吧:
- 我们知道了一个临时视图:t_user
- 我们从 JSON 文件中推测到了字段名称和字段类型:
| 字段名称 | 字段类型 |
|---|---|
| name | StringType |
| age | LongType |
| sex | StringType |
| addr | ArrayType |
上面的字段类型都是来自 Apache Spark 的内部类型。
看看源码实现吧
找到入口
def sql(sqlText: String): DataFrame = withActive {
val tracker = new QueryPlanningTracker
val plan = tracker.measurePhase(QueryPlanningTracker.PARSING) {
// parsing 阶段
sessionState.sqlParser.parsePlan(sqlText)
}
Dataset.ofRows(self, plan, tracker)
}
def ofRows(sparkSession: SparkSession, logicalPlan: LogicalPlan, tracker: QueryPlanningTracker)
: DataFrame = sparkSession.withActive {
val qe = new QueryExecution(sparkSession, logicalPlan, tracker)
qe.assertAnalyzed()
new Dataset[Row](qe, RowEncoder(qe.analyzed.schema))
}
// analyzed 延迟初始化
def assertAnalyzed(): Unit = analyzed
lazy val analyzed: LogicalPlan = executePhase(QueryPlanningTracker.ANALYSIS) {
// 这里就是`analysis`阶段的入口啦
sparkSession.sessionState.analyzer.executeAndCheck(logical, tracker)
}
Analyzer.executeAndCheck
def executeAndCheck(plan: LogicalPlan, tracker: QueryPlanningTracker): LogicalPlan = {
// 已解析就直接返回当前逻辑计划
if (plan.analyzed) return plan
// 这里利用了一个 `ThreadLocal[Int]` 类型避免解析器递归调用自己
AnalysisHelper.markInAnalyzer {
// 执行
val analyzed = executeAndTrack(plan, tracker)
try {
// 执行完成后校验解析结果
checkAnalysis(analyzed)
analyzed
} catch {
// 构造解析异常并抛出
case e: AnalysisException =>
val ae = e.copy(plan = Option(analyzed))
ae.setStackTrace(e.getStackTrace)
throw ae
}
}
}
可以看到analysis阶段的核心逻辑就 2 步:
- 执行
- 校验
我们先来看看执行
执行
def executeAndTrack(plan: TreeType, tracker: QueryPlanningTracker): TreeType = {
// 设置一下追踪器,关于查询计划追踪器请参考第一讲
QueryPlanningTracker.withTracker(tracker) {
execute(plan)
}
}
execute 会调用 RuleExecutor 的子类Analyzer 的重写方法。
override def execute(plan: LogicalPlan): LogicalPlan = {
AnalysisContext.withNewAnalysisContext {
executeSameContext(plan)
}
}
private def executeSameContext(plan: LogicalPlan): LogicalPlan = super.execute(plan)
从上面的源码中可以看出来,相比于抽象父类RuleExecutor 的execute来说,只是多了一个闭包执行的过程,analysis阶段会伴随一个新的解析上下文(AnalysisContext)。
/**
* 执行子类定义的规则批。
* 规则批会使用定义好的执行策略串行执行。
* 在每个批中,规则也会连续执行。
*/
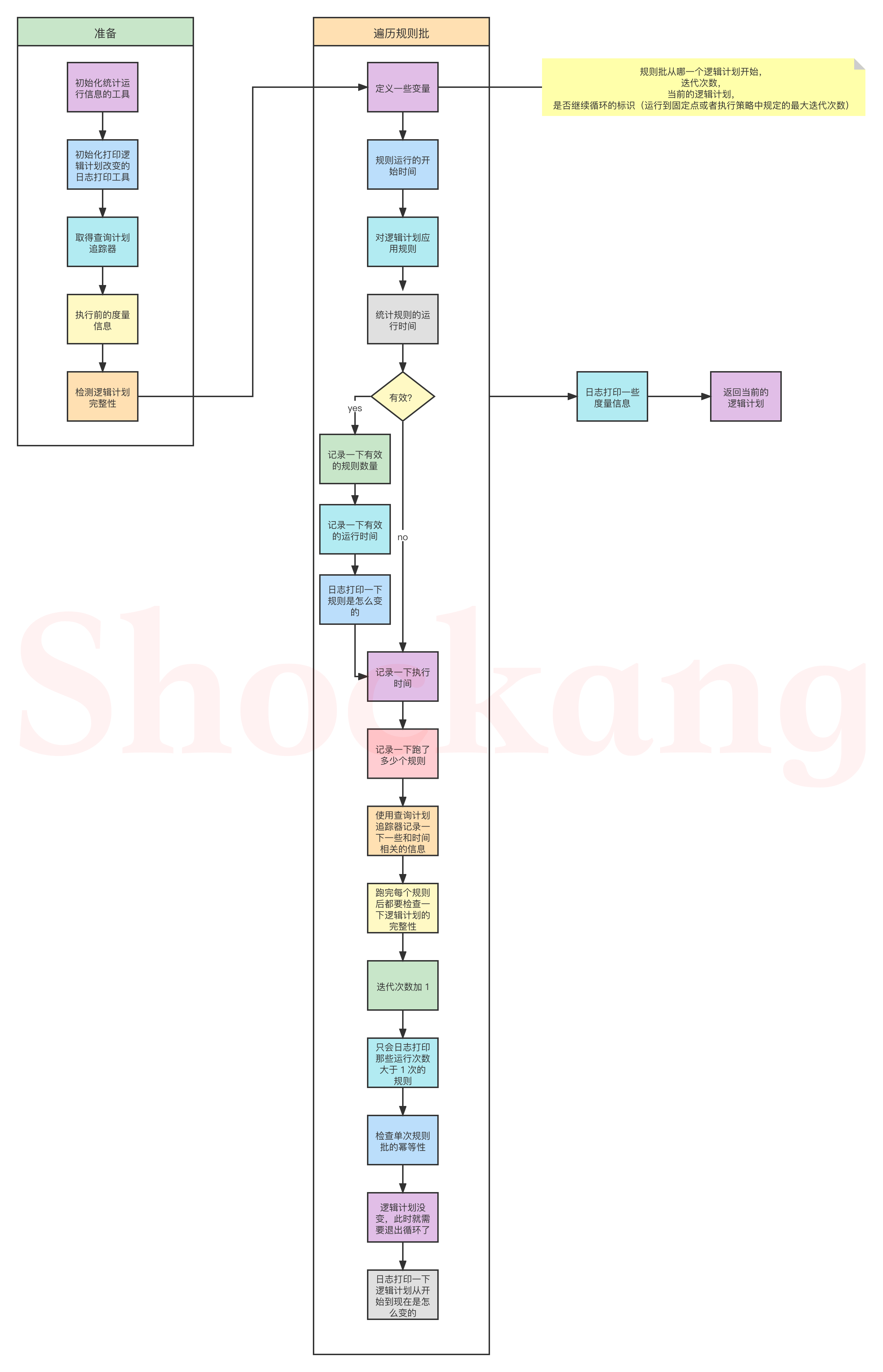
def execute(plan: TreeType): TreeType = {
var curPlan = plan
// 这个是用于统计一些运行信息的,比如花了多少时间,跑了规则批等等
val queryExecutionMetrics = RuleExecutor.queryExecutionMeter
// 当规则或者规则批被应用后,日志记录一下逻辑计划的改变
val planChangeLogger = new PlanChangeLogger[TreeType]()
// 还是那个查询计划追踪器,参见第一讲
val tracker: Option[QueryPlanningTracker] = QueryPlanningTracker.get
// 执行前的度量信息
val beforeMetrics = RuleExecutor.getCurrentMetrics()
// 这个是用来检查逻辑计划的完整性的,主要是通过校验命名表达式(NamedExpression)的 ID (exprId)是否唯一不重复
if (!isPlanIntegral(plan, plan)) {
throw QueryExecutionErrors.structuralIntegrityOfInputPlanIsBrokenInClassError(
this.getClass.getName.stripSuffix("$"))
}
batches.foreach {
batch =>
// 规则批从哪一个逻辑计划开始
val batchStartPlan = curPlan
// 迭代次数
var iteration = 1
// 记录当前的逻辑计划
var lastPlan = curPlan
// 表示是否继续循环的标识
var continue = true
// 运行到固定点(或者执行策略中规定的最大迭代次数)
while (continue) {
curPlan = batch.rules.foldLeft(curPlan) {
case (plan, rule) =>
// 规则运行的开始时间
val startTime = System.nanoTime()
// 对逻辑计划应用规则
val result = rule(plan)
// 规则的运行时间
val runTime = System.nanoTime() - startTime
// 不等说明规则起了作用,是有效的
val effective = !result.fastEquals(plan)
if (effective) {
//记录一下有效的规则数量queryExecutionMetrics.incNumEffectiveExecution(rule.ruleName)
// 记录一下有效的运行时间queryExecutionMetrics.incTimeEffectiveExecutionBy(rule.ruleName, runTime)
// 日志打印一下规则是怎么变的
planChangeLogger.logRule(rule.ruleName, plan, result)
}
// 记录一下执行时间
queryExecutionMetrics.incExecutionTimeBy(rule.ruleName, runTime)
// 记录一下跑了多少个规则
queryExecutionMetrics.incNumExecution(rule.ruleName)
// 使用查询计划追踪器记录一下一些和时间相关的信息
tracker.foreach(_.recordRuleInvocation(rule.ruleName, runTime, effective))
// 跑完每个规则后都要检查一下逻辑计划的完整性
if (effective && !isPlanIntegral(plan, result)) {
throw QueryExecutionErrors.structuralIntegrityIsBrokenAfterApplyingRuleError(
rule.ruleName, batch.name)
}
result
}
// 迭代次数加 1
iteration += 1
if (iteration > batch.strategy.maxIterations) {
// 只会日志打印那些运行次数大于 1 次的规则
if (iteration != 2) {
val endingMsg = if (batch.strategy.maxIterationsSetting == null) {
"."
} else {
s", please set '${
batch.strategy.maxIterationsSetting}' to a larger value."
}
val message = s"Max iterations (${
iteration - 1}) reached for batch ${
batch.name}" +
s"$endingMsg"
if (Utils.isTesting || batch.strategy.errorOnExceed) {
throw new RuntimeException(message)
} else {
logWarning(message)
}
}
// 检查单次规则批的幂等性
if (batch.strategy == Once &&
Utils.isTesting && !excludedOnceBatches.contains(batch.name)) {
checkBatchIdempotence(batch, curPlan)
}
continue = false
}
// 逻辑计划没变,此时就需要退出循环了
if (curPlan.fastEquals(lastPlan)) {
logTrace(
s"Fixed point reached for batch ${
batch.name} after ${
iteration - 1} iterations.")
continue = false
}
lastPlan = curPlan
}
// 日志打印一下逻辑计划从开始到现在是怎么变的
planChangeLogger.logBatch(batch.name, batchStartPlan, curPlan)
}
// 日志打印一些度量信息
planChangeLogger.logMetrics(RuleExecutor.getCurrentMetrics() - beforeMetrics)
curPlan
}
流程图如下所示:
整个流程看起来也比较简单,最核心的逻辑实际上就下面的一行代码:
val result = rule(plan)
这里代表的是对当前的逻辑计划应用特定的规则得到另一个逻辑计划。
看到这里,其实大家都明白了,执行相比来说并不重要,底层起到核心作用的是规则批(Batch)和规则(Rule)。
规则批(Batch)和规则(Rule)到底是什么呢?
规则批(Batch)
源码中的batches代表的就是规则批序列
/**
* 定义要由实现覆盖的规则批处理序列。
*/
protected def batches: Seq[Batch]
规则批(Batch)由规则名称、执行策略和规则列表组成。
protected case class Batch(name: String, strategy: Strategy, rules: Rule[TreeType]*)
执行策略
abstract class Strategy {
/** 执行最大迭代次数 */
def maxIterations: Int
/** 超过最大次数后是否抛出异常 */
def errorOnExceed: Boolean = false
/** SQLConf 中用来配置最大迭代次数的键 */
def maxIterationsSetting: String = null
}
执行策略分为 2 种类型:fixedPoint 和 Once
fixedPoint
// 如果在maxIterations中无法解决该计划,analyzer将抛出异常以通知用户增加SQLConf.ANALYZER_MAX_ITERATIONS 的值。
protected def fixedPoint =
FixedPoint(
conf.analyzerMaxIterations,
errorOnExceed = true,
maxIterationsSetting = SQLConf.ANALYZER_MAX_ITERATIONS.key)
SQLConf.ANALYZER_MAX_ITERATIONS 代表的是配置项spark.sql.analyzer.maxIterations
case class FixedPoint(
override val maxIterations: Int,
override val errorOnExceed: Boolean = false,
override val maxIterationsSetting: String = null) extends Strategy
FixedPoint 代表运行到定点或最大迭代次数的策略,以先到者为准。
FixedPoint(1) 的规则批应该只运行一次。
Once
case object Once extends Strategy {
val maxIterations = 1 }
Once 代表是一种只运行一次且幂等的策略。
规则(Rule)
abstract class Rule[TreeType <: TreeNode[_]] extends SQLConfHelper with Logging {
// 规则的整型 ID,用来修剪不必要的树遍历
protected lazy val ruleId = RuleIdCollection.getRuleId(this.ruleName)
/** 当前规则的名称,根据类名自动推断 */
val ruleName: String = {
val className = getClass.getName
if (className endsWith "$") className.dropRight(1) else className
}
/** 最核心的应用函数 */
def apply(plan: TreeType): TreeType
}
其中 TreeType 代表的是 TreeNode 的任意一个子类,而 TreeNode 则是 Spark SQL 中所有树型结构的父类,像之前源码中的逻辑计划(LogicalPlan)就是它的一个子类。
规则批到底有哪些呢?
我们可以从 Analyzer.scala 文件中找到答案
override def batches: Seq[Batch] = Seq(
Batch("Substitution", fixedPoint,
OptimizeUpdateFields,
CTESubstitution,
WindowsSubstitution,
EliminateUnions,
SubstituteUnresolvedOrdinals),
Batch("Disable Hints", Once,
new ResolveHints.DisableHints),
Batch("Hints", fixedPoint,
ResolveHints.ResolveJoinStrategyHints,
ResolveHints.ResolveCoalesceHints),
Batch("Simple Sanity Check", Once,
LookupFunctions),
Batch("Keep Legacy Outputs", Once,
KeepLegacyOutputs),
Batch("Resolution", fixedPoint,
ResolveTableValuedFunctions(v1SessionCatalog) ::
ResolveNamespace(catalogManager) ::
new ResolveCatalogs(catalogManager) ::
ResolveUserSpecifiedColumns ::
ResolveInsertInto ::
ResolveRelations ::
ResolvePartitionSpec ::
ResolveFieldNameAndPosition ::
AddMetadataColumns ::
DeduplicateRelations ::
ResolveReferences ::
ResolveExpressionsWithNamePlaceholders ::
ResolveDeserializer ::
ResolveNewInstance ::
ResolveUpCast ::
ResolveGroupingAnalytics ::
ResolvePivot ::
ResolveOrdinalInOrderByAndGroupBy ::
ResolveAggAliasInGroupBy ::
ResolveMissingReferences ::
ExtractGenerator ::
ResolveGenerate ::
ResolveFunctions ::
ResolveAliases ::
ResolveSubquery ::
ResolveSubqueryColumnAliases ::
ResolveWindowOrder ::
ResolveWindowFrame ::
ResolveNaturalAndUsingJoin ::
ResolveOutputRelation ::
ExtractWindowExpressions ::
GlobalAggregates ::
ResolveAggregateFunctions ::
TimeWindowing ::
SessionWindowing ::
ResolveInlineTables ::
ResolveLambdaVariables ::
ResolveTimeZone ::
ResolveRandomSeed ::
ResolveBinaryArithmetic ::
ResolveUnion ::
typeCoercionRules ++
Seq(ResolveWithCTE) ++
extendedResolutionRules : _*),
Batch("Remove TempResolvedColumn", Once, RemoveTempResolvedColumn),
Batch("Apply Char Padding", Once,
ApplyCharTypePadding),
Batch("Post-Hoc Resolution", Once,
Seq(ResolveCommandsWithIfExists) ++
postHocResolutionRules: _*),
Batch("Remove Unresolved Hints", Once,
new ResolveHints.RemoveAllHints),
Batch("Nondeterministic", Once,
PullOutNondeterministic),
Batch("UDF", Once,
HandleNullInputsForUDF,
ResolveEncodersInUDF),
Batch("UpdateNullability", Once,
UpdateAttributeNullability),
Batch("Subquery", Once,
UpdateOuterReferences),
Batch("Cleanup", fixedPoint,
CleanupAliases),
Batch("HandleAnalysisOnlyCommand", Once,
HandleAnalysisOnlyCommand)
)
因为底层跑的实际上就是一个个的规则(Rule),我们就以规则(Rule)为粒度,画出了下面的表格。
| 规则 | 所属规则批 | 执行策略 | 解释说明 | 补充说明 |
|---|---|---|---|---|
| OptimizeUpdateFields | Substitution | fixedPoint | 此规则优化了UpdateFields表达式链,因此看起来更像优化规则。然而,当操作深度嵌套的模式时,UpdateFields表达式树可能是非常复杂,无法进行分析。因此,我们需要尽早优化UpdateFields在分析的开始。 |
|
| CTESubstitution | Substitution | fixedPoint | 根据以下条件,使用节点进行分析,并使用CTE引用或CTE定义替换子计划:1。如果处于传统模式,或者如果查询是SQL命令或DML语句,替换为CTE定义,即内联CTE。2.否则,替换为CTE引用CTERelationRef。在查询分析之后,InlineCTE规则将决定是否内联。 对于每个主查询和子查询,此替换后未内联的所有CTE定义都将分组在一个WithCTE节点下。任何不包含CTE或已内联所有CTE的主查询或子查询显然都不会包含任何WithCTE节点。如果有,WithCTE节点将与最外层的With节点所在的位置相同。 WithCTE节点中的CTE定义按解析顺序保存。这意味着,根据CTE定义对任何有效CTE查询的依赖性,可以保证CTE定义按拓扑顺序排列(即,给定CTE定义A和B,B引用A,A保证出现在B之前)。否则,它必须是无效的用户查询,关系解析规则稍后将抛出分析异常。 |
|
| WindowsSubstitution | Substitution | fixedPoint | 用 WindowSpecDefinitions 替代子计划,其中 WindowSpecDefinition 代表的是窗口函数的规范。 |
|
| EliminateUnions | Substitution | fixedPoint | 如果只有一个子项,则从计划中删除 Union 算子 |
|
| SubstituteUnresolvedOrdinals | Substitution | fixedPoint | 将“order by”或“group by”中的序号替换为UnresolvedOrdinal表达式,其中UnresolvedOrdinal表示按order by或group by使用的未解析序号。 例如:select a from table order by 1 和 select a from table group by 1 |
|
| DisableHints | Disable Hints | Once | 当配置项spark.sql.optimizer.disableHints被设置时删除spark时的所有hints。这将在Analyzer的最开始执行,以禁用hints功能。 |
|
| ResolveJoinStrategyHints | Hints | fixedPoint | 允许的join策略hint列表在JoinStrategyHint.strategies中定义。可以使用join策略hint指定一系列关系别名,例如“MERGE(a, c)”、“BROADCAST(a)”。join策略hint计划节点将插入到与指定名称匹配的任何关系(别名不同)、子查询或公共表表达式的顶部。hint解析的工作原理是递归遍历查询计划,找到与指定关系别名之一匹配的关系或子查询。遍历不会超出任何视图引用,包括子句或子查询别名。 此规则必须发生在公共表表达式之前。 |
允许的join策略有:1.BROADCAST(“BROADCAST”,“BROADCASTJOIN”,“MAPJOIN”)2.SHUFFLE_MERGE(“SHUFFLE_MERGE”,“MERGE”,“MERGEJOIN”)3.SHUFFLE_HASH(“SHUFFLE_HASH”)4.SHUFFLE_REPLICATE_NL(“SHUFFLE_REPLICATE_NL”),括号外为所属类别,括号为具体的hint字符串 |
| ResolveCoalesceHints | Hints | fixedPoint | COALESCE Hint允许下面几个名字:“COALESCE”,“REPARTITION”,“REPARTITION_BY_RANGE” |
|
| LookupFunctions | Simple Sanity Check | Once | 检查未解析函数引用的函数标识符是否在函数注册表中定义。请注意,此规则不会尝试解析UnsolvedFunction。它只根据函数标识符执行简单的存在性检查,以快速识别未定义的函数,而不触发关系解析,这在某些情况下可能会导致潜在的昂贵的分区/schema发现过程。为了避免重复的外部函数查找,外部函数标识符将存储在本地哈希集externalFunctionNameSet中。 |
|
| KeepLegacyOutputs | Keep Legacy Outputs | Once | 当spark.sql.legacy.keepCommandOutputSchema设置为true的时候,Spark 会保持诸如SHOW DATABASES之类命令的输出格式不变。 |
SHOW TABLES/SHOW NAMESPACES/DESCRIBE NAMESPACE/SHOW TBLPROPERTIES |
| ResolveTableValuedFunctions | Resolution | fixedPoint | 解析表值函数引用的规则。 | |
| ResolveNamespace | Resolution | fixedPoint | 解析诸如SHOW TABLES、SHOW FUNCTIONS之类的规则。 |
SHOW TABLES/SHOW TABLE EXTENDED/SHOW VIEWS/SHOW FUNCTIONS/ANALYZE TABLES |
| ResolveCatalogs | Resolution | fixedPoint | 从SQL语句中的多部分标识符解析catalog,如果解析的catalog不是session catalog,则将语句转换为相应的v2命令。 |
|
| ResolveUserSpecifiedColumns | Resolution | fixedPoint | 解析用户指定的列。 | |
| ResolveInsertInto | Resolution | fixedPoint | 解析INSERT INTO语句。 |
|
| ResolveRelations | Resolution | fixedPoint | 用catalog中的具体关系替换未解析的关系(表和视图)。 |
像逻辑计划中包含UnresolvedRelation就会用到这个规则,我们的例子中就使用了。 |
| ResolvePartitionSpec | Resolution | fixedPoint | 在分区相关命令中将UnresolvedPartitionSpec解析成ResolvedPartitionSpec。 |
|
| ResolveFieldNameAndPosition | Resolution | fixedPoint | 根据命令的大小写敏感度解析、规范化和重写字段名的规则。 | |
| AddMetadataColumnsResolution | Resolution | fixedPoint | 当节点缺少已解析属性时,将元数据列添加到子关系的输出中。 使用LogicalPlan.metadataOutput中的列解析对元数据列的引用。但在替换关系之前,关系的输出不包括元数据列。除非此规则将元数据添加到关系的输出中,否则analyzer将检测到没有任何内容生成列。 此规则仅在节点已解析但缺少来自其子节点的输入时添加元数据列。这可以确保元数据列不会添加到计划中,除非使用它们。通过只检查已解析的节点,这可以确保已完成 * 扩展,以便 * 不会意外选择元数据列。此规则将运算符解析为向下,以避免过早地投射元数据列。 |
|
| DeduplicateRelations | Resolution | fixedPoint | 删除LogicalPlan的任何重复关系。 | |
| ResolveReferences | Resolution | fixedPoint | 将UnresolvedAttribute替换为逻辑计划节点子节点的具体AttributeReference。 |
|
| ResolveExpressionsWithNamePlaceholders | Resolution | fixedPoint | 解析包含名称占位符的表达式。 | |
| ResolveDeserializer | Resolution | fixedPoint | 将UnsolvedDeserializer替换为已解析为给定输入属性的反序列化表达式。 |
|
| ResolveNewInstance | Resolution | fixedPoint | 如果要构造的对象是内部类,则通过查找外部作用域并向其添加外部作用域来解析NewInstance。 |
|
| ResolveUpCast | Resolution | fixedPoint | 用Cast替换UpCast,如果转换可能会截断,则抛出异常。 |
|
| ResolveGroupingAnalytics | Resolution | fixedPoint | 解析grouping函数。 |
|
| ResolvePivot | Resolution | fixedPoint | 解析pivot(行转列) |
|
| ResolveOrdinalInOrderByAndGroupBy | Resolution | fixedPoint | 在SQL的许多方言中,在order/sort by和group by子句中使用的顺序位置是有效的。此规则用于将序号位置转换为选择列表中的相应表达式。Spark 2.0中引入了这种支持。如果排序引用或分组依据表达式不是整数而是可折叠表达式,请忽略它们。当spark.sql.orderByOrdinal/spark.sql.groupByOrdinal设置为false,也忽略位置号。 |
在Spark 2.0发布之前,order/sort by和group by子句中的字符对结果没有影响。 |
| ResolveAggAliasInGroupBy | Resolution | fixedPoint | 将分组键中未解析的表达式替换为SELECT子句中已解析的表达式。此规则应在ResolveReferences应用之后运行。 |
|
| ResolveMissingReferences | Resolution | fixedPoint | 在SQL的许多方言中,按SELECT子句中不存在的属性进行排序是有效的。此规则检测此类查询,并将所需属性添加到原始投影中,以便在排序过程中可用。添加另一个投影以在排序后删除这些属性。HAVING子句还可以使用SELECT中未显示的分组列。 | |
| ExtractGenerator | Resolution | fixedPoint | 从Project操作符的Project列表中提取Generator,并在Project下创建Generate操作符。 此规则将在以下情况下引发AnalysisException:1.生成器嵌套在表达式中,例如SELECT explode(list) + 1 FROM tbl。2.projectList中有多个生成器,例如SELECT explode(list), explode(list) FROM tbl。3.生成器可在其他非Project或Generate的运算符中找到,例如SELECT * FROM tbl SORT BY explode(list)。 |
|
| ResolveGenerate | Resolution | fixedPoint | 重写表,生成需要以下一个或多个表达式才能解析的表达式: 其输出的具体属性引用。 从SELECT子句(即从Project)重新定位到Generate子句中。 输出Attribute的名称是从封装Generator的Alias或MultiAlias表达式中提取的。 |
|
| ResolveFunctions | Resolution | fixedPoint | 用具体的LogicalPlan替换UnresolvedFunc,用具体的Expression替换UnresolvedFunction。 |
|
| ResolveAliases | Resolution | fixedPoint | 用具体的别名替换UnresolvedAlias。 |
|
| ResolveSubquery | Resolution | fixedPoint | 此规则解析并重写表达式内的子查询。 注:CTE在CTESubstitution中处理。 |
|
| ResolveSubqueryColumnAliases | Resolution | fixedPoint | 用投影替换子查询的未解析列别名。 | |
| ResolveWindowOrder | Resolution | fixedPoint | 检查并添加顺序到 AggregateWindowFunction |
|
| ResolveWindowFrame | Resolution | fixedPoint | 检查并为所有窗口功能添加适当的窗口框架 | |
| ResolveNaturalAndUsingJoin | Resolution | fixedPoint | 通过基于两侧的输出计算输出列来删除natural join或using join,然后在普通join上应用投影以消除natural join或using join。 |
|
| ResolveOutputRelation | Resolution | fixedPoint | 从逻辑计划中的数据解析输出表的列。这条规则将会:1.按名称写入时对列重新排序;2.数据类型不匹配时插入强制转换;3.列名不匹配时插入别名;4.检测与输出表不兼容的计划并引发AnalysisException | |
| ExtractWindowExpressions | Resolution | fixedPoint | 从Project运算符的projectList和聚合运算符的aggregateExpressions中提取WindowExpressions,并为每个不同的WindowsSpecDefinition创建单独的窗口运算符。 这条规则处理三种情况: 1.Project列表中有WindowExpressions的Project; 2.在其aggregateExpressions中包含WindowExpressions的聚合。 3.一个Filter->Aggregate 模式代表HAVING子句表示GROUP BY,Aggregate 在其aggregateExpressions中有WindowExpressions。 | |
| GlobalAggregates | Resolution | fixedPoint | 将包含聚合表达式的投影转换为聚合。 | |
| ResolveAggregateFunctions | Resolution | fixedPoint | 此规则查找不在聚合运算符中的聚合表达式。例如,HAVING子句或ORDER BY子句中的那些。这些表达式被下推到基础聚合运算符,然后在原始运算符之后投影出去。 | |
| TimeWindowing | Resolution | fixedPoint | 使用“Expand”操作符将时间列映射到多个时间窗口。由于计算一个时间列可以映射到多少个窗口是非常重要的,因此我们高估了窗口的数量,并过滤掉时间列不在时间窗口内的行。 | |
| SessionWindowing | Resolution | fixedPoint | 将时间列匹配到会话窗口。 | |
| ResolveInlineTables | Resolution | fixedPoint | 使用LocalRelation替换UnresolvedInlineTable |
|
| ResolveLambdaVariables | Resolution | fixedPoint | 解析高阶函数公开的lambda变量。 此规则分为两个步骤:1.将高阶函数公开的匿名变量绑定到lambda函数的参数;这将创建命名和类型化的lambda变量。在此步骤中,将检查参数名称是否重复,并检查参数的数量。2.解析lambda函数的函数表达式树中使用的lambda变量。请注意,我们允许使用当前lambda之外的变量,这可以是在外部范围中定义的lambda函数,也可以是由计划的子级生成的属性。如果名称重复,则使用最内部作用域中定义的名称。 | |
| ResolveTimeZone | Resolution | fixedPoint | 将不带时区id的TimeZoneAwareExpression替换为会话本地时区的副本。 |
|
| ResolveRandomSeed | Resolution | fixedPoint | 设置随机数生成的种子。 | |
| ResolveBinaryArithmetic | Resolution | fixedPoint | 关于加法:1.如果两边都是间隔,保持不变;2.否则,如果一边是日期,另一边是间隔,则将其转换为DateAddInterval;3.否则,如果一侧为interval,则将其转换为TimeAdd;4.否则,如果一面是date,则将其改为DateAdd;5.其他方面不变。 关于减法:1.如果两边都是间隔,保持不变;2.否则,如果左侧为日期,右侧为间隔,则将其转换为DateAddInterval(l, -r);3.否则,如果右侧是区间,则将其转换为TimeAdd(l, -r);4.否则,如果一面是时间戳,则将其转换为SubtractTimestamps;5.否则,如果右边是date,则将其转换为DateDiff/Subtract Dates;6.否则,如果左侧是date,则将其转换为DateSub;7.否则,它将保持不变。 关于乘法:1。如果一侧为间隔,则将其转换为MultiplyInterval;2.否则,将保持不变。 关于除法:1。如果左侧为interval,则将其转为DivideInterval;2.否则,将保持不变。 |
|
| ResolveUnion | Resolution | fixedPoint | 将union的不同子级解析为一组公共列。 |
|
| typeCoercionRules | Resolution | fixedPoint | 当spark.sql.ansi.enabled设置为 true 的时候,采取 ANSI 的方式进行解析,这代表的是一组解析规则。 |
|
| ResolveWithCTE | Resolution | fixedPoint | 使用相应CTE定义的resolve output属性更新CTE引用。 | |
| extendedResolutionRules | Resolution | fixedPoint | 方便重写来提供额外的规则。 | |
| RemoveTempResolvedColumn | Remove TempResolvedColumn | Once | 删除查询计划中的所有TempResolvedColumn。这是最后一种手段,以防主解析批处理中的某些规则无法删除TempResolvedColumn。我们应该在主解析批处理之后立即运行此规则。 |
|
| ApplyCharTypePadding | Apply Char Padding | Once | 此规则为字符类型比较执行字符串填充。 当比较char类型的列/字段与string literal或char类型的列/字段时,右键将较短的列/字段填充为较长的列/字段。 | |
| ResolveCommandsWithIfExists | Post-Hoc Resolution | Once | 表或临时视图未解析时处理命令的规则。这些命令支持一个标志“ifExists”,以便在关系未解决时不会失败。如果“ifExists”标志设置为true,逻辑计划会被解析成NoopCommand。 |
DROP TABLE/DROP VIEW/UNCACHE TABLE/DROP FUNCTION |
| postHocResolutionRules | Post-Hoc Resolution | Once | 方便重写以提供进行事后解决的规则。请注意,这些规则将在单个批次中执行。该批处理将在正常解析批处理之后运行,并一次性执行其规则。 | |
| RemoveAllHints | Remove Unresolved Hints | Once | 删除所有hints,用于删除用户提供的无效hints。这必须在执行所有其他hints规则之后执行。 |
|
| PullOutNondeterministic | Nondeterministic | Once | 从不是Project或过滤器的LogicalPlan中提取不确定性表达式,将它们放入内部Project,最后将它们投射到外部Project。 | |
| HandleNullInputsForUDF | UDF | Once | 通过添加额外的If表达式来执行null检查,正确处理UDF的null原语输入。当用户使用基元参数定义UDF时,无法判断基元参数是否为null,因此这里我们假设基元输入是null可传播的,如果输入为null,我们应该返回null。 | |
| ResolveEncodersInUDF | UDF | Once | 通过明确给出属性来解析UDF的编码器。我们显式地给出属性,以便处理输入值的数据类型与编码器的内部模式不同的情况,这可能会导致数据丢失。例如,如果实际数据类型为Decimal(30,0),编码器不应将输入值转换为Decimal(38,18)。 然后,解析的编码器将用于将internal row反序列化为Scala值。 |
|
| UpdateAttributeNullability | UpdateNullability | Once | 通过使用其子输出属性的相应属性的可空性,更新已解析LogicalPlan中属性的可空性。之所以需要此步骤,是因为用户可以在Dataset API中使用已解析的AttributeReference,而外部联接可以更改AttributeReference的可空性。如果没有这个规则,可以为NULL的列的NULL字段实际上可以设置为non-NULL,这会导致非法优化(例如NULL传播)和错误答案。有关本案例的具体查询,请参阅SPARK-13484和SPARK-13801。 | |
| UpdateOuterReferences | Subquery | Once | 推送引用外部查询块的子查询中的聚合表达式下到外部查询块进行评估。下面的规则会更新这些外部引用作为AttributeReference引用parentouter查询块中的属性。 | |
| CleanupAliases | Cleanup | fixedPoint | 清除计划中不必要的别名。基本上,我们只需要将Alias作为Project(Project列表)或聚合(聚合表达式)或窗口(窗口表达式)中的顶级表达式。请注意,如果表达式具有不在其子表达式中的其他表达式参数,例如RuntimeReplacable,则此规则中的别名转换无法用于这些参数。 | |
| HandleAnalysisOnlyCommand | Cleanup | fixedPoint | 将命令标记为已分析的规则,以便删除其子命令以避免优化。此规则应在运行所有其他分析规则后运行。 |
建议参考我的这篇博客实现解析规则的自定义扩展——Spark SQL 如何自定义扩展?
解析顺序
上表中的解析是按照顺序来执行的。
解析顺序如下图所示:

typeCoercionRules
上面的规则中有一组规则比较特别,还记得我们在第二讲(Spark SQL 工作流程源码解析(二)parsing 阶段(基于 Spark 3.3.0))提到的 Hive SQL ⇒ Spark SQL ⇒ ANSI SQL 的演变吗? 这组规则就和它有关。
ANSI SQL
当 spark.sql.ansi.enabled 设置为 true 的时候,Spark 就会倾向 ANSI 的方式去处理 SQL。
| 规则 | 说明 |
|---|---|
| InConversion | 处理包括有子查询的 IN 表达式和没有子查询的 IN 表达式的类型强转。1.在第一种情况下,通过将左侧(LHS)表达式类型与从子查询表达式的计划输出派生的相应右侧(RHS)表达式进行比较,找到公共类型。在 IN 表达式的LHS和RHS注入适当的转换。 2.在第二种情况下,通过查看所有参数类型并找到所有参数可以转换到的最接近的类型,将值和 in list expressions 转换为公共算子类型。当找不到公共算子类型时,将返回原始表达式,并在类型检查阶段引发解析异常。 |
| PromoteStringLiterals | 算术、比较和日期时间表达式中出现的字符串文本解析。 |
| DecimalPrecision | 计算并传播固定精度小数的精度。基于标准SQL和MS SQL,Hive对此有许多规则:https://cwiki.apache.org/confluence/download/attachments/27362075/Hive_Decimal_Precision_Scale_Support.pdf https://msdn.microsoft.com/en-us/library/ms190476.aspx |
| FunctionArgumentConversion | 确保不同函数的类型符合预期。 |
| ConcatCoercion | 将Concat属性children的类型强转为预期的类型。 如果spark.sql.function.concatBinaryAsString为false,所有子类型均为 binary,预期类型为 binary。否则,预期的是字符串。 |
| MapZipWithCoercion | 将MapZipWith表达式的两个不同MapType参数的键类型强转为公共类型。 |
| EltCoercion | 将Elt属性children的类型强制为预期的类型。如果spark.sql.function.concatBinaryAsString为false,所有子类型均为 binary,预期类型为 binary。否则,预期的是字符串。 |
| CaseWhenCoercion | 将CASE WHEN语句的不同分支的类型强转为公共类型。 |
| IfCoercion | 将If语句的不同分支的类型强转为公共类型。 |
| StackCoercion | 将Stack表达式中的NullType强制为相应位置的列类型 |
| Division | Hive仅使用DIV运算符执行整数除法。/的参数始终转换为小数类型。 |
| IntegralDivision | DIV运算符始终返回长整型值。该规则将整数输入强制转换为long类型,以避免计算期间溢出。 |
| ImplicitTypeCasts | 根据Expression的预期输入类型强制转换类型。 |
| DateTimeOperations | 处理日期时间的函数datetime_funcs(Spark SQL functions.scala 源码解析(八)DateTime functions (基于 Spark 3.3.0)) |
| WindowFrameCoercion | 将WindowFrame强制转换为其操作的类型。 |
| GetDateFieldOperations | 从时间戳列获取日期字段时,将该列强制转换为日期类型。 这是Spark为简化实现所做的努力。在默认类型强制规则中,隐式强制转换规则完成了这项工作。然而,ANSI隐式转换规则不允许将时间戳类型转换为日期类型,因此我们需要有这个额外的规则来确保从时间戳列提取日期字段的工作正常。 |
HIVE SQL
当 spark.sql.ansi.enabled 设置为 false 的时候,Spark 就会倾向 HIVE 的方式去处理 SQL。
| 规则 | 说明 |
|---|---|
| InConversion | 处理包括有子查询的 IN 表达式和没有子查询的 IN 表达式的类型强转。1.在第一种情况下,通过将左侧(LHS)表达式类型与从子查询表达式的计划输出派生的相应右侧(RHS)表达式进行比较,找到公共类型。在 IN 表达式的LHS和RHS注入适当的转换。 2.在第二种情况下,通过查看所有参数类型并找到所有参数可以转换到的最接近的类型,将值和 in list expressions 转换为公共算子类型。当找不到公共算子类型时,将返回原始表达式,并在类型检查阶段引发解析异常。 |
| PromoteStrings | 算术表达式中出现的字符串文本解析。 |
| DecimalPrecision | 计算并传播固定精度小数的精度。基于标准SQL和MS SQL,Hive对此有许多规则:https://cwiki.apache.org/confluence/download/attachments/27362075/Hive_Decimal_Precision_Scale_Support.pdf https://msdn.microsoft.com/en-us/library/ms190476.aspx |
| BooleanEquality | 将数值类型更改为布尔类型,以便可以计算true=1之类的表达式 |
| FunctionArgumentConversion | 确保不同函数的类型符合预期。 |
| ConcatCoercion | 将Concat属性children的类型强转为预期的类型。 如果spark.sql.function.concatBinaryAsString为false,所有子类型均为 binary,预期类型为 binary。否则,预期的是字符串。 |
| MapZipWithCoercion | 将MapZipWith表达式的两个不同MapType参数的键类型强转为公共类型。 |
| EltCoercion | 将Elt属性children的类型强制为预期的类型。如果spark.sql.function.concatBinaryAsString为false,所有子类型均为 binary,预期类型为 binary。否则,预期的是字符串。 |
| CaseWhenCoercion | 将CASE WHEN语句的不同分支的类型强转为公共类型。 |
| IfCoercion | 将If语句的不同分支的类型强转为公共类型。 |
| StackCoercion | 将Stack表达式中的NullType强制为相应位置的列类型 |
| Division | Hive仅使用DIV运算符执行整数除法。/的参数始终转换为小数类型。 |
| IntegralDivision | DIV运算符始终返回长整型值。该规则将整数输入强制转换为long类型,以避免计算期间溢出。 |
| ImplicitTypeCasts | 根据Expression的预期输入类型强制转换类型。 |
| DateTimeOperations | 处理日期时间的函数datetime_funcs(Spark SQL functions.scala 源码解析(八)DateTime functions (基于 Spark 3.3.0)) |
| WindowFrameCoercion | 将WindowFrame强制转换为其操作的类型。 |
| StringLiteralCoercion | 一个特殊规则,支持字符串文字作为date_add/date_sub函数的第二个参数,以保持向后兼容性作为临时解决方法。 |
校验
执行完解析规则后就是校验了,这里充分利用了 scala 的模式匹配机制,每当我们需要新增一种校验规则后只需要新增一个 case 分支就行。
def checkAnalysis(plan: LogicalPlan): Unit = {
// 我们对规则进行转换和排序,以便抓住第一个可能的失败而不是级联解析失败的结果。
// 后序遍历的方式递归应用校验规则到逻辑计划树
plan.foreachUp {
case p if p.analyzed => // 跳过已经解析的子计划
// 叶子节点的输出不能有 char/varchar 类型
case leaf: LeafNode if leaf.output.map(_.dataType).exists(CharVarcharUtils.hasCharVarchar) =>
throw new IllegalStateException(
"[BUG] logical plan should not have output of char/varchar type: " + leaf)
// namespace 找不到
case u: UnresolvedNamespace =>
u.failAnalysis(s"Namespace not found: ${
u.multipartIdentifier.quoted}")
// 表找不到
case u: UnresolvedTable =>
u.failAnalysis(s"Table not found: ${
u.multipartIdentifier.quoted}")
// v2 版本的 catalog 中没有实现视图的支持
case u @ UnresolvedView(NonSessionCatalogAndIdentifier(catalog, ident), cmd, _, _) =>
u.failAnalysis(
s"Cannot specify catalog `${
catalog.name}` for view ${
ident.quoted} " +
"because view support in v2 catalog has not been implemented yet. " +
s"$cmd expects a view.")
// 视图找不到
case u: UnresolvedView =>
u.failAnalysis(s"View not found: ${
u.multipartIdentifier.quoted}")
// 表或视图找不到
case u: UnresolvedTableOrView =>
val viewStr = if (u.allowTempView) "view" else "permanent view"
u.failAnalysis(
s"Table or $viewStr not found: ${
u.multipartIdentifier.quoted}")
// 数据库关系(表或视图)找不到
case u: UnresolvedRelation =>
u.failAnalysis(s"Table or view not found: ${
u.multipartIdentifier.quoted}")
// 数据库函数找不到
case u: UnresolvedFunc =>
throw QueryCompilationErrors.noSuchFunctionError(
u.multipartIdentifier, u, u.possibleQualifiedName)
// Hint 找不到
case u: UnresolvedHint =>
u.failAnalysis(s"Hint not found: ${
u.name}")
// INSERT INTO 语句中表找不到
case InsertIntoStatement(u: UnresolvedRelation, _, _, _, _, _) =>
u.failAnalysis(s"Table not found: ${
u.multipartIdentifier.quoted}")
// DataSourceV2 写命令中表找不到
case write: V2WriteCommand if write.table.isInstanceOf[UnresolvedRelation] =>
val tblName = write.table.asInstanceOf[UnresolvedRelation].multipartIdentifier
write.table.failAnalysis(s"Table or view not found: ${
tblName.quoted}")
// v2 版本的分区命令中表未分区或者表不支持分区
case command: V2PartitionCommand =>
command.table match {
case r @ ResolvedTable(_, _, table, _) => table match {
case t: SupportsPartitionManagement =>
if (t.partitionSchema.isEmpty) {
failAnalysis(s"Table ${
r.name} is not partitioned.")
}
case _ =>
failAnalysis(s"Table ${
r.name} does not support partition management.")
}
case _ =>
}
// `ShowTableExtended`当表是 v1 版本的时候要转换成 v1 的命令
// v2 版本的表不支持`SHOW TABLE EXTENDED`
case _: ShowTableExtended =>
throw QueryCompilationErrors.commandUnsupportedInV2TableError("SHOW TABLE EXTENDED")
case operator: LogicalPlan =>
// 首先向下检查高阶函数的参数的数据类型。
// 如果高阶函数的参数已解析,但类型检查失败,参数函数不会得到解析,但我们应该报告参数类型检查失败,而不是声称参数函数未解决。
operator transformExpressionsDown {
case hof: HigherOrderFunction
if hof.argumentsResolved && hof.checkArgumentDataTypes().isFailure =>
hof.checkArgumentDataTypes() match {
case TypeCheckResult.TypeCheckFailure(message) =>
hof.failAnalysis(
s"cannot resolve '${
hof.sql}' due to argument data type mismatch: $message")
}
}
// 开始检查表达式
// 首先获取逻辑计划的所有表达式
// 由于 GROUP BY 别名特性的存在,分组表达式会依赖聚合表达式,故我们在碰到聚合算子的情况下要先检查聚合表达式
getAllExpressions(operator).foreach(_.foreachUp {
// 表字段找不到
case a: Attribute if !a.resolved =>
val missingCol = a.sql
val candidates = operator.inputSet.toSeq.map(_.qualifiedName)
val orderedCandidates = StringUtils.orderStringsBySimilarity(missingCol, candidates)
a.failAnalysis(
errorClass = "MISSING_COLUMN",
messageParameters = Array(missingCol, orderedCandidates.mkString(", ")))
// 此处不能出现 *,正常情况下应该都解析成相应的字段了
case s: Star =>
withPosition(s) {
throw QueryCompilationErrors.invalidStarUsageError(operator.nodeName, Seq(s))
}
// 表达式检查输入数据的类型
case e: Expression if e.checkInputDataTypes().isFailure =>
e.checkInputDataTypes() match {
case TypeCheckResult.TypeCheckFailure(message) =>
e.setTagValue(DATA_TYPE_MISMATCH_ERROR, true)
e.failAnalysis(
s"cannot resolve '${
e.sql}' due to data type mismatch: $message" +
extraHintForAnsiTypeCoercionExpression(operator))
}
// 类型强转需要数据类型能够支持强转
case c: Cast if !c.resolved =>
failAnalysis(s"invalid cast from ${
c.child.dataType.catalogString} to " +
c.dataType.catalogString)
// grouping() 必须搭配 GroupingSets/Cube/Rollup 一起使用
case g: Grouping =>
failAnalysis("grouping() can only be used with GroupingSets/Cube/Rollup")
// grouping_id() 必须搭配 GroupingSets/Cube/Rollup 一起使用
case g: GroupingID =>
failAnalysis("grouping_id() can only be used with GroupingSets/Cube/Rollup")
// 窗口函数必须有 OVER 子句
// 有 OVER 的类型会是:Alias(WindowExpression(w: WindowFunction, _), _)
// 无 OVER 的类型会是:Alias(w: WindowFunction, _).
case e: Expression if e.children.exists(_.isInstanceOf[WindowFunction]) &&
!e.isInstanceOf[WindowExpression] =>
val w = e.children.find(_.isInstanceOf[WindowFunction]).get
failAnalysis(s"Window function $w requires an OVER clause.")
// 不支持 Distinct 窗口函数
case w @ WindowExpression(AggregateExpression(_, _, true, _, _), _) =>
failAnalysis(s"Distinct window functions are not supported: $w")
// 窗口函数只能在使用单个偏移量的基于行排序的窗口框架中被计算
case w @ WindowExpression(wf: FrameLessOffsetWindowFunction,
WindowSpecDefinition(_, order, frame: SpecifiedWindowFrame))
if order.isEmpty || !frame.isOffset =>
failAnalysis(s"${
wf.prettyName} function can only be evaluated in an ordered " +
s"row-based window frame with a single offset: $w")
case w: WindowExpression =>
// 此处只允许窗口函数要么有聚合表达式、要么有偏移量窗口函数、要么有 pandas 窗口 UDF
w.windowFunction match {
case _: AggregateExpression | _: FrameLessOffsetWindowFunction |
_: AggregateWindowFunction => // OK
case f: PythonUDF if PythonUDF.isWindowPandasUDF(f) => // OK
case other =>
failAnalysis(s"Expression '$other' not supported within a window function.")
}
// 检查子查询表达式
// 确保相关的标量子查询在每个外部行中包含一行通过强制它们是只包含一个聚合表达式的聚合。
// GROUP BY 字段必须是谓词中列的子集
case s: SubqueryExpression =>
checkSubqueryExpression(operator, s)
case e: ExpressionWithRandomSeed if !e.seedExpression.foldable =>
failAnalysis(
s"Input argument to ${
e.prettyName} must be a constant.")
case _ =>
})
operator match {
// 事件时间必须定义在窗口或者时间戳上
case etw: EventTimeWatermark =>
etw.eventTime.dataType match {
case s: StructType
if s.find(_.name == "end").map(_.dataType) == Some(TimestampType) =>
case _: TimestampType =>
case _ =>
failAnalysis(
s"Event time must be defined on a window or a timestamp, but " +
s"${
etw.eventTime.name} is of type ${
etw.eventTime.dataType.catalogString}")
}
// 过滤表达式的条件得是布尔类型
case f: Filter if f.condition.dataType != BooleanType =>
failAnalysis(
s"filter expression '${
f.condition.sql}' " +
s"of type ${
f.condition.dataType.catalogString} is not a boolean.")
// JOIN 条件得是布尔类型
case j @ Join(_, _, _, Some(condition), _) if condition.dataType != BooleanType =>
failAnalysis(
s"join condition '${
condition.sql}' " +
s"of type ${
condition.dataType.catalogString} is not a boolean.")
// ASOF JOIN 的条件得是布尔类型
case j @ AsOfJoin(_, _, _, Some(condition), _, _, _)
if condition.dataType != BooleanType =>
failAnalysis(
s"join condition '${
condition.sql}' " +
s"of type ${
condition.dataType.catalogString} is not a boolean.")
// ASOF JOIN 容忍度得是常量,非负数
case j @ AsOfJoin(_, _, _, _, _, _, Some(toleranceAssertion)) =>
if (!toleranceAssertion.foldable) {
failAnalysis("Input argument tolerance must be a constant.")
}
if (!toleranceAssertion.eval().asInstanceOf[Boolean]) {
failAnalysis("Input argument tolerance must be non-negative.")
}
// 检查聚合算子
case a @ Aggregate(groupingExprs, aggregateExprs, child) =>
// 判断是不是一个聚合表达式
def isAggregateExpression(expr: Expression): Boolean = {
expr.isInstanceOf[AggregateExpression] || PythonUDF.isGroupedAggPandasUDF(expr)
}
// 检查是不是一个有效的聚合表达式
def checkValidAggregateExpression(expr: Expression): Unit = expr match {
case expr: Expression if isAggregateExpression(expr) =>
val aggFunction = expr match {
case agg: AggregateExpression => agg.aggregateFunction
case udf: PythonUDF => udf
}
// 不允许在另一个聚合函数参数的内部使用聚合函数,要使用子查询内部的聚合函数
aggFunction.children.foreach {
child =>
child.foreach {
case expr: Expression if isAggregateExpression(expr) =>
failAnalysis(
s"It is not allowed to use an aggregate function in the argument of " +
s"another aggregate function. Please use the inner aggregate function " +
s"in a sub-query.")
case other => // OK
}
// 聚合函数参数内部不应该出现不确定性表达式
if (!child.deterministic) {
failAnalysis(
s"nondeterministic expression ${
expr.sql} should not " +
s"appear in the arguments of an aggregate function.")
}
}
case e: Attribute if groupingExprs.isEmpty =>
// 收集所有的聚合表达式
// 分组键表达式序列是空的,当前不是聚合函数
// 如果不关心获取了哪个值,可以使用窗口函数或者 first/first_value 来包装。
val aggExprs = aggregateExprs.filter(_.collect {
case a: AggregateExpression => a
}.nonEmpty)
failAnalysis(
s"grouping expressions sequence is empty, " +
s"and '${
e.sql}' is not an aggregate function. " +
s"Wrap '${
aggExprs.map(_.sql).mkString("(", ", ", ")")}' in windowing " +
s"function(s) or wrap '${
e.sql}' in first() (or first_value) " +
s"if you don't care which value you get."
)
// 表达式要么出现在 group by 中,要么是一个聚合函数
// 如果不关心获取了哪个值,可以添加到 group by 或者使用 first/first_value 来包装
case e: Attribute if !groupingExprs.exists(_.semanticEquals(e)) =>
failAnalysis(
s"expression '${
e.sql}' is neither present in the group by, " +
s"nor is it an aggregate function. " +
"Add to group by or wrap in first() (or first_value) if you don't care " +
"which value you get.")
// 相关的标量子查询要么出现在 group by 中,要么在一个聚合函数内部
// 如果不关心获取了哪个值,可以依次添加到 group by 或者使用 first/first_value 来包装
case s: ScalarSubquery
if s.children.nonEmpty && !groupingExprs.exists(_.semanticEquals(s)) =>
failAnalysis(s"Correlated scalar subquery '${
s.sql}' is neither " +
"present in the group by, nor in an aggregate function. Add it to group by " +
"using ordinal position or wrap it in first() (or first_value) if you don't " +
"care which value you get.")
// 分组键序列中允许存在一个计算结果和当前相等的分组键
case e if groupingExprs.exists(_.semanticEquals(e)) => // OK
// 递归检查子节点
case e => e.children.foreach(checkValidAggregateExpression)
}
// 检查是不是一个有效的分组键序列
def checkValidGroupingExprs(expr: Expression): Unit = {
// GROUP BY 中不能使用聚合函数
if (expr.find(_.isInstanceOf[AggregateExpression]).isDefined) {
failAnalysis(
"aggregate functions are not allowed in GROUP BY, but found " + expr.sql)
}
// 检查表达式的数据类型是不是可排序的
if (!RowOrdering.isOrderable(expr.dataType)) {
failAnalysis(
s"expression ${
expr.sql} cannot be used as a grouping expression " +
s"because its data type ${
expr.dataType.catalogString} is not an orderable " +
s"data type.")
}
// 分布表达式中不能出现不确定性表达式
if (!expr.deterministic) {
// 这里只是一个理智上的检查,解析规则 PullOutNondeterministic 理论上应该已经找出了那些不确定性表达式并且放到了 Project 节点中进行计算
failAnalysis(s"nondeterministic expression ${
expr.sql} should not " +
s"appear in grouping expression.")
}
}
// 检查所有的分组表达式
groupingExprs.foreach(checkValidGroupingExprs)
// 检查所有的聚合表达式
aggregateExprs.foreach(checkValidAggregateExpression)
// 检查度量信息收集
case CollectMetrics(name, metrics, _) =>
if (name == null || name.isEmpty) {
operator.failAnalysis(s"observed metrics should be named: $operator")
}
// 检查表达式是否为有效的度量。度量必须满足以下标准:1. 不是一个窗口函数;2. 不是嵌套的聚合函数;3. 不是一个 DISTINCT 聚合函数;4. 只有嵌套在聚合函数中的非确定性函数;5. 只有嵌套在聚合函数中的属性。
def checkMetric(s: Expression, e: Expression, seenAggregate: Boolean = false): Unit = {
e match {
case _: WindowExpression =>
e.failAnalysis(
"window expressions are not allowed in observed metrics, but found: " + s.sql)
case _ if !e.deterministic && !seenAggregate =>
e.failAnalysis(s"non-deterministic expression ${
s.sql} can only be used " +
"as an argument to an aggregate function.")
case a: AggregateExpression if seenAggregate =>
e.failAnalysis(
"nested aggregates are not allowed in observed metrics, but found: " + s.sql)
case a: AggregateExpression if a.isDistinct =>
e.failAnalysis(
"distinct aggregates are not allowed in observed metrics, but found: " + s.sql)
case a: AggregateExpression if a.filter.isDefined =>
e.failAnalysis("aggregates with filter predicate are not allowed in " +
"observed metrics, but found: " + s.sql)
case _: Attribute if !seenAggregate =>
e.failAnalysis (s"attribute ${
s.sql} can only be used as an argument to an " +
"aggregate function.")
case _: AggregateExpression =>
e.children.foreach(checkMetric (s, _, seenAggregate = true))
case _ =>
e.children.foreach(checkMetric (s, _, seenAggregate))
}
}
metrics.foreach(m => checkMetric(m, m))
// 字段类型不支持排序
case Sort(orders, _, _) =>
orders.foreach {
order =>
if (!RowOrdering.isOrderable(order.dataType)) {
failAnalysis(
s"sorting is not supported for columns of type ${
order.dataType.catalogString}")
}
}
// Limit 表达式得是一个常量、整型值
case GlobalLimit(limitExpr, _) => checkLimitLikeClause("limit", limitExpr)
// Limit 表达式得是一个常量、整型值
case LocalLimit(limitExpr, _) => checkLimitLikeClause("limit", limitExpr)
// Limit 表达式得是一个常量、整型值
case Tail(limitExpr, _) => checkLimitLikeClause("tail", limitExpr)
// 如果是 Union/Except/Intersect
case _: Union | _: SetOperation if operator.children.length > 1 =>
def dataTypes(plan: LogicalPlan): Seq[DataType] = plan.output.map(_.dataType)
def ordinalNumber(i: Int): String = i match {
case 0 => "first"
case 1 => "second"
case 2 => "third"
case i => s"${
i + 1}th"
}
val ref = dataTypes(operator.children.head)
operator.children.tail.zipWithIndex.foreach {
case (child, ti) =>
// 检查字段的数目
if (child.output.length != ref.length) {
failAnalysis(
s"""
|${
operator.nodeName} can only be performed on tables with the same number
|of columns, but the first table has ${
ref.length} columns and
|the ${
ordinalNumber(ti + 1)} table has ${
child.output.length} columns
""".stripMargin.replace("\n", " ").trim())
}
val dataTypesAreCompatibleFn = getDataTypesAreCompatibleFn(operator)
// 检查数据类型是不是匹配
dataTypes(child).zip(ref).zipWithIndex.foreach {
case ((dt1, dt2), ci) =>
// 要关注字段可空性
if (dataTypesAreCompatibleFn(dt1, dt2)) {
val errorMessage =
s"""
|${
operator.nodeName} can only be performed on tables with the compatible
|column types. The ${
ordinalNumber(ci)} column of the
|${
ordinalNumber(ti + 1)} table is ${
dt1.catalogString} type which is not
|compatible with ${
dt2.catalogString} at same column of first table
""".stripMargin.replace("\n", " ").trim()
failAnalysis(errorMessage + extraHintForAnsiTypeCoercionPlan(operator))
}
}
}
// 逻辑计划是用来创建或替代 V2 版本表定义的
case create: V2CreateTablePlan =>
val references = create.partitioning.flatMap(_.references).toSet
val badReferences = references.map(_.fieldNames).flatMap {
column =>
create.tableSchema.findNestedField(column) match {
case Some(_) =>
None
// 字段缺失或在 map/array 中
case _ =>
Some(s"${
column.quoted} is missing or is in a map or array")
}
}
// 无效分区
if (badReferences.nonEmpty) {
failAnalysis(s"Invalid partitioning: ${
badReferences.mkString(", ")}")
}
create.tableSchema.foreach(f => TypeUtils.failWithIntervalType(f.dataType))
// DataSourceV2 的写命令
case write: V2WriteCommand if write.resolved =>
write.query.schema.foreach(f => TypeUtils.failWithIntervalType(f.dataType))
// DataSourceV2 修改表的命令
case alter: AlterTableCommand =>
checkAlterTableCommand(alter)
case _ => // 返回到下面的检查
}
operator match {
case o if o.children.nonEmpty && o.missingInput.nonEmpty =>
val missingAttributes = o.missingInput.mkString(",")
val input = o.inputSet.mkString(",")
// 数据输入中属性缺失
val msgForMissingAttributes = s"Resolved attribute(s) $missingAttributes missing " +
s"from $input in operator ${
operator.simpleString(SQLConf.get.maxToStringFields)}."
val resolver = plan.conf.resolver
val attrsWithSameName = o.missingInput.filter {
missing =>
o.inputSet.exists(input => resolver(missing.name, input.name))
}
val msg = if (attrsWithSameName.nonEmpty) {
val sameNames = attrsWithSameName.map(_.name).mkString(",")
// 出现了相同名称的属性,请检查是否使用了正确的属性。
s"$msgForMissingAttributes Attribute(s) with the same name appear in the " +
s"operation: $sameNames. Please check if the right attribute(s) are used."
} else {
msgForMissingAttributes
}
failAnalysis(msg)
// SELECT 语句只能运行一个表生成函数
case p @ Project(exprs, _) if containsMultipleGenerators(exprs) =>
failAnalysis(
s"""Only a single table generating function is allowed in a SELECT clause, found:
| ${
exprs.map(_.sql).mkString(",")}""".stripMargin)
// Join 中属性冲突
case j: Join if !j.duplicateResolved =>
val conflictingAttributes = j.left.outputSet.intersect(j.right.outputSet)
failAnalysis(
s"""
|Failure when resolving conflicting references in Join:
|$plan
|Conflicting attributes: ${
conflictingAttributes.mkString(",")}
|""".stripMargin)
// Intersect 中属性冲突
case i: Intersect if !i.duplicateResolved =>
val conflictingAttributes = i.left.outputSet.intersect(i.right.outputSet)
failAnalysis(
s"""
|Failure when resolving conflicting references in Intersect:
|$plan
|Conflicting attributes: ${
conflictingAttributes.mkString(",")}
""".stripMargin)
// Except 中属性冲突
case e: Except if !e.duplicateResolved =>
val conflictingAttributes = e.left.outputSet.intersect(e.right.outputSet)
failAnalysis(
s"""
|Failure when resolving conflicting references in Except:
|$plan
|Conflicting attributes: ${
conflictingAttributes.mkString(",")}
""".stripMargin)
// AsOfJoin 中属性冲突
case j: AsOfJoin if !j.duplicateResolved =>
val conflictingAttributes = j.left.outputSet.intersect(j.right.outputSet)
failAnalysis(
s"""
|Failure when resolving conflicting references in AsOfJoin:
|$plan
|Conflicting attributes: ${
conflictingAttributes.mkString(",")}
|""".stripMargin)
// DataFrame 中不能有 Map 类型的调用 set 操作(intersect,except 等)的字段
case o if mapColumnInSetOperation(o).isDefined =>
val mapCol = mapColumnInSetOperation(o).get
failAnalysis("Cannot have map type columns in DataFrame which calls " +
s"set operations(intersect, except, etc.), but the type of column ${
mapCol.name} " +
"is " + mapCol.dataType.catalogString)
case o if o.expressions.exists(!_.deterministic) &&
!o.isInstanceOf[Project] && !o.isInstanceOf[Filter] &&
!o.isInstanceOf[Aggregate] && !o.isInstanceOf[Window] &&
// Lateral join 已经在checkSubqueryExpression 中被检查过
!o.isInstanceOf[LateralJoin] =>
// 上面的规则是用来检查聚合算子的
// 不确定性的表达式只能在 Project/ Filter/Aggregate/Window 中被使用
failAnalysis(
s"""nondeterministic expressions are only allowed in
|Project, Filter, Aggregate or Window, found:
| ${
o.expressions.map(_.sql).mkString(",")}
|in operator ${
operator.simpleString(SQLConf.get.maxToStringFields)}
""".stripMargin)
// 检查是否有未解析的 hint
case _: UnresolvedHint =>
throw QueryExecutionErrors.logicalHintOperatorNotRemovedDuringAnalysisError
// Aggregate/Window/Generate 表达式在查询的 WHERE 子句中是无效的
case f @ Filter(condition, _)
if PlanHelper.specialExpressionsInUnsupportedOperator(f).nonEmpty =>
val invalidExprSqls = PlanHelper.specialExpressionsInUnsupportedOperator(f).map(_.sql)
failAnalysis(
s"""
|Aggregate/Window/Generate expressions are not valid in where clause of the query.
|Expression in where clause: [${
condition.sql}]
|Invalid expressions: [${
invalidExprSqls.mkString(", ")}]""".stripMargin)
// 查询算子包含了一到多个不支持的表达式 类型是Aggregate/Window/Generate
case other if PlanHelper.specialExpressionsInUnsupportedOperator(other).nonEmpty =>
val invalidExprSqls =
PlanHelper.specialExpressionsInUnsupportedOperator(other).map(_.sql)
failAnalysis(
s"""
|The query operator `${
other.nodeName}` contains one or more unsupported
|expression types Aggregate, Window or Generate.
|Invalid expressions: [${
invalidExprSqls.mkString(", ")}]""".stripMargin
)
case _ => // 解析成功 !
}
}
// 检查收集到的度量信息
checkCollectedMetrics(plan)
// 用户自定义的校验规则
extendedCheckRules.foreach(_(plan))
plan.foreachUp {
// 检查是否存在未解析的算子
case o if !o.resolved =>
failAnalysis(s"unresolved operator ${
o.simpleString(SQLConf.get.maxToStringFields)}")
case _ =>
}
// 将查询计划的标识符设置为已解析
plan.setAnalyzed()
}
上面的校验规则实际上划分成了 5 个独立的模块,不同的校验规则之间存在着顺序上面的差异,这是为了避免同时触发多个校验失败而影响判断。
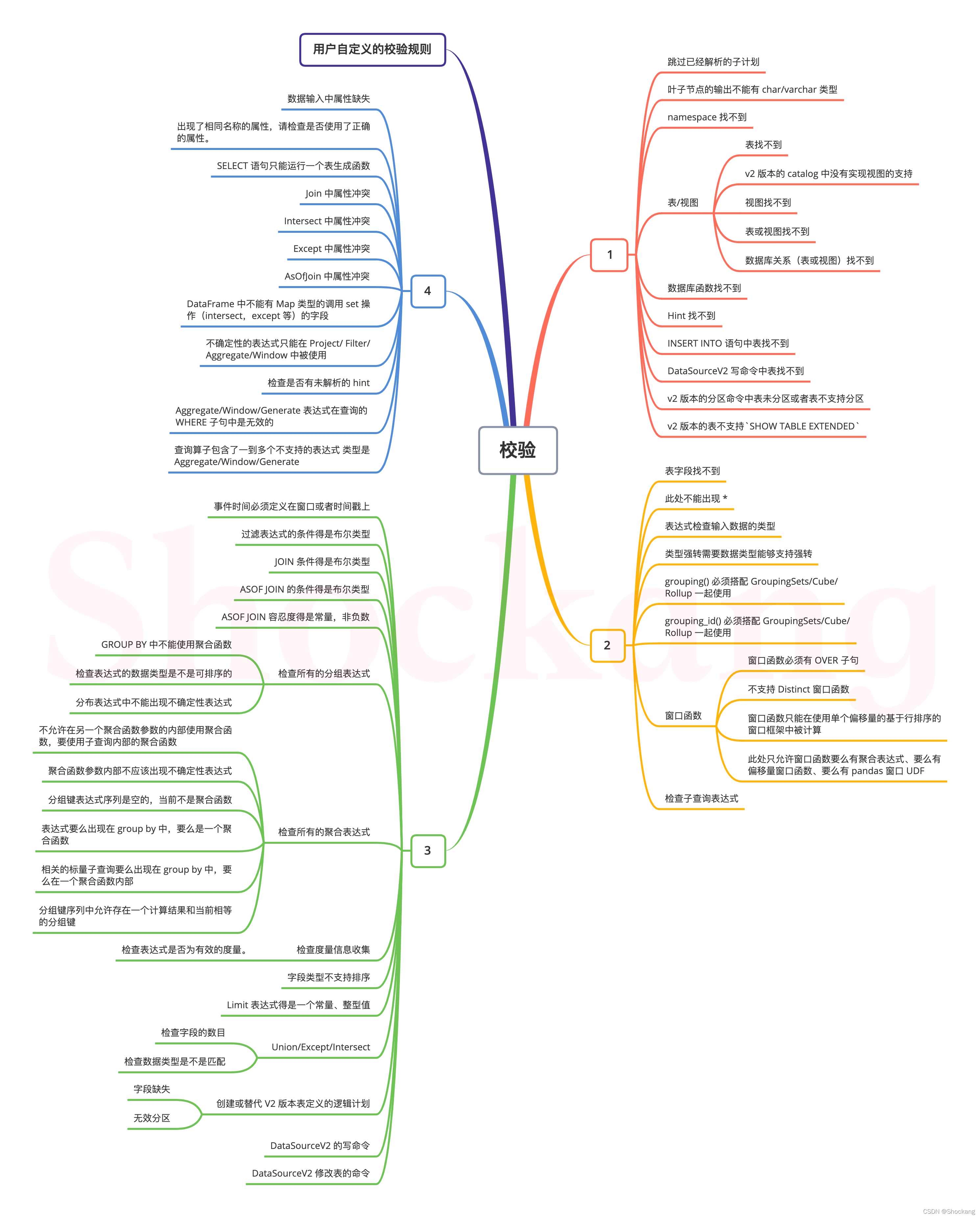
回到最初的例子
由于篇幅的限制,我们不可能做到详解每一种规则具体是怎么实现的。
所以,我们就回到最初的例子,搞懂它的解析相信可以做到触类旁通。
从上面的分析可以看出,解析规则多达 66 个,如何快速判断具体哪些规则对我们的逻辑计划产生了作用呢?
spark.sql.planChangeLog.level
这里面要提到一个配置参数:spark.sql.planChangeLog.level。
在回过头来看看上面执行(execute)过程的源码解析,可以发现,有一个PlanChangeLogger可以帮助我们将逻辑计划的变化过程打印到日志当中,而spark.sql.planChangeLog.level就是用来控制逻辑计划的变化日志打印级别的。
Spark 程序的日志打印级别可以通过修改 Spark 安装目录下的
conf/log4j.properties文件。
故我们稍微修改一下我们的应用程序代码以实现逻辑计划变化日志的打印。
package com.shockang.study.spark.sql.demo
import com.shockang.study.spark.SQL_DATA_DIR
import org.apache.spark.sql.SparkSession
/**
* @author Shockang
*/
object SparkSQLExample {
val DATA_PATH: String = SQL_DATA_DIR + "user.json"
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder
.master("local[*]")
.appName("SparkSQLExample")
.config("spark.sql.planChangeLog.level", "INFO")
.getOrCreate()
val df = spark.read.json(DATA_PATH)
df.createTempView("t_user")
spark.sql("SELECT * FROM t_user").show
spark.stop()
}
}
具体的源码大家可以通过访问下面的链接前往 github 下载:spark-examples
这是我发布的一个开源项目,致力于提供最具实践性的 Apache Spark 代码开发学习指南。
控制台的日志打印结果如下(只截取其中的关键日志):
22/03/29 20:32:01 INFO PlanChangeLogger: Batch Preparations has no effect.
22/03/29 20:32:01 INFO PlanChangeLogger: Batch Substitution has no effect.
22/03/29 20:32:01 INFO PlanChangeLogger: Batch Disable Hints has no effect.
22/03/29 20:32:01 INFO PlanChangeLogger: Batch Hints has no effect.
22/03/29 20:32:01 INFO PlanChangeLogger: Batch Simple Sanity Check has no effect.
22/03/29 20:32:01 INFO PlanChangeLogger: Batch Keep Legacy Outputs has no effect.
22/03/29 20:32:01 INFO PlanChangeLogger:
=== Applying Rule org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveRelations ===
'Project [*] 'Project [*]
!+- 'UnresolvedRelation [t_user], [], false +- SubqueryAlias t_user
! +- View (`t_user`, [addr#8,age#9L,name#10,sex#11])
! +- Relation [addr#8,age#9L,name#10,sex#11] json
22/03/29 20:32:01 INFO PlanChangeLogger:
=== Applying Rule org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveReferences ===
!'Project [*] Project [addr#8, age#9L, name#10, sex#11]
+- SubqueryAlias t_user +- SubqueryAlias t_user
+- View (`t_user`, [addr#8,age#9L,name#10,sex#11]) +- View (`t_user`, [addr#8,age#9L,name#10,sex#11])
+- Relation [addr#8,age#9L,name#10,sex#11] json +- Relation [addr#8,age#9L,name#10,sex#11] json
22/03/29 20:32:01 INFO PlanChangeLogger:
=== Result of Batch Resolution ===
!'Project [*] Project [addr#8, age#9L, name#10, sex#11]
!+- 'UnresolvedRelation [t_user], [], false +- SubqueryAlias t_user
! +- View (`t_user`, [addr#8,age#9L,name#10,sex#11])
! +- Relation [addr#8,age#9L,name#10,sex#11] json
22/03/29 20:32:01 INFO PlanChangeLogger: Batch Remove TempResolvedColumn has no effect.
22/03/29 20:32:01 INFO PlanChangeLogger: Batch Apply Char Padding has no effect.
22/03/29 20:32:01 INFO PlanChangeLogger: Batch Post-Hoc Resolution has no effect.
22/03/29 20:32:01 INFO PlanChangeLogger: Batch Remove Unresolved Hints has no effect.
22/03/29 20:32:01 INFO PlanChangeLogger: Batch Nondeterministic has no effect.
22/03/29 20:32:01 INFO PlanChangeLogger: Batch UDF has no effect.
22/03/29 20:32:01 INFO PlanChangeLogger: Batch UpdateNullability has no effect.
22/03/29 20:32:01 INFO PlanChangeLogger: Batch Subquery has no effect.
22/03/29 20:32:01 INFO PlanChangeLogger: Batch Cleanup has no effect.
22/03/29 20:32:01 INFO PlanChangeLogger: Batch HandleAnalysisOnlyCommand has no effect.
22/03/29 20:32:01 INFO PlanChangeLogger:
=== Metrics of Executed Rules ===
Total number of runs: 126
Total time: 0.032725789 seconds
Total number of effective runs: 2
Total time of effective runs: 0.01908174 seconds
通过控制台的日志打印,我们发现例子中有 2 个规则起到了核心作用:
- ResolveRelations
- ResolveReferences
ResolveRelations
ResolveRelations 规则使用 catalog 中的具体关系替换未解析的关系(这里的关系指的表和视图)。
那么它是怎么实现的呢?
其实就 3 个步骤,具体的流程图如下:
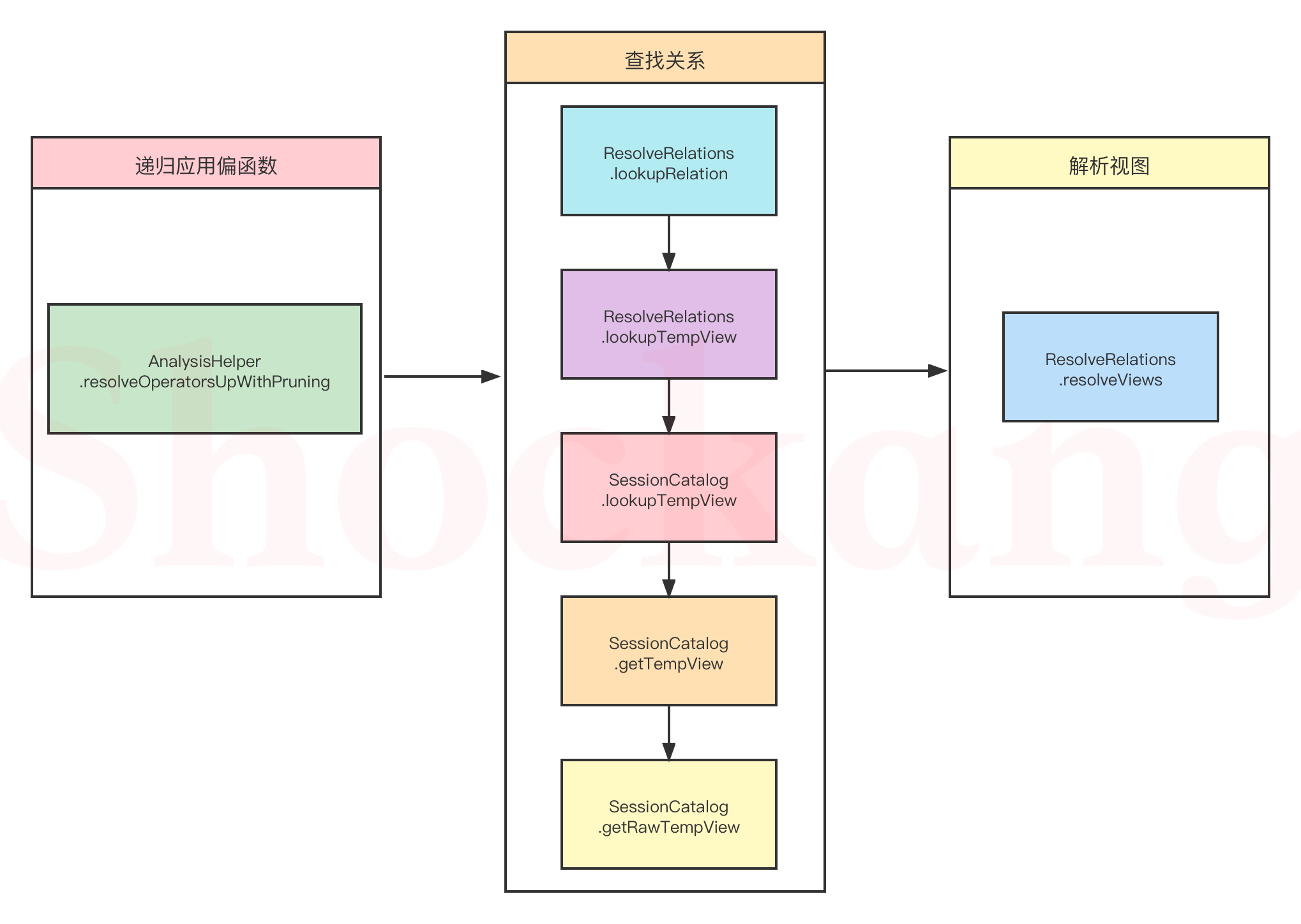
下面,我们跟读源码来理解上面的流程图:
apply
我们看下 apply 函数的实现,前面提到过,这是规则(Rule)中最核心的函数。
def apply(plan: LogicalPlan)
: LogicalPlan = plan.resolveOperatorsUpWithPruning(AlwaysProcess.fn, ruleId) {
先来看看 resolveOperatorsUpWithPruning 是什么?
递归应用偏函数
/**
* 返回此节点的副本,其中规则首先递归应用于其所有子节点,然后递归应用于其自身(后序遍
* 历,自底向上)。当规则不适用于给定节点时,它保持不变。此函数类似于transformUp,
* 但跳过已标记为已分析的子树。
* @param rule–用于将此节点转换为子节点的函数。
* @param cond–修剪树遍历的Lambda表达式。如果`cond.apply`在运算符T上返回
* false,跳过处理T及其子树;否则,递归地处理T及其子树。
* @param ruleId–是规则用于修剪不必要的树遍历的唯一Id。当它是未知规则时,不会进行
* 修剪。否则,如果规则(id为ruleId)已在运算符T上标记为有效,则跳
* 过处理T及其子树。如果规则不是纯功能性的,并且为不同的调用读取不同
* 的初始状态,则不要传递它。
*/
def resolveOperatorsUpWithPruning(cond: TreePatternBits => Boolean,
ruleId: RuleId = UnknownRuleId)(rule: PartialFunction[LogicalPlan, LogicalPlan])
: LogicalPlan = {
// 当前逻辑计划未被解析 并且 可以递归处理其子树 并且 对于id为ruleId的规则,此树节点及其子树没有被标记为无效。
if (!analyzed && cond.apply(self) && !isRuleIneffective(ruleId)) {
// 防止嵌套调用,这里使用了一个 ThreadLocal[Int] 来记录调用的深度
AnalysisHelper.allowInvokingTransformsInAnalyzer {
// 返回当前节点的副本,递归应用于其所有子节点
// 每一个规则的输入都是其子节点应用规则后的输出
val afterRuleOnChildren = mapChildren(_.resolveOperatorsUpWithPruning(cond, ruleId)(rule))
// 如果前后逻辑计划未发生改变
val afterRule = if (self fastEquals afterRuleOnChildren) {
CurrentOrigin.withOrigin(origin) {
// 应用规则到逻辑计划
rule.applyOrElse(self, identity[LogicalPlan])
}
} else {
CurrentOrigin.withOrigin(origin) {
// 应用规则到处理后的逻辑计划
rule.applyOrElse(afterRuleOnChildren, identity[LogicalPlan])
}
}
if (self eq afterRule) {
// 标记规则(带有id ruleId)对此树节点及其子树无效。
self.markRuleAsIneffective(ruleId)
self
} else {
// 复制节点标签
afterRule.copyTagsFrom(self)
afterRule
}
}
} else {
self
}
}
可以看到这部分的核心在于偏函数 rule,我们再来看看它的实现。
由于 parsing 阶段完成后,我们的逻辑计划是这样的:
'Project [*]
+- 'UnresolvedRelation [t_user], [], false
很明显就可以看出来,我们对应偏函数的分支是下面这个:
case u: UnresolvedRelation =>
lookupRelation(u).map(resolveViews).getOrElse(u)
查找关系
我们需要从 Catalog 中查找对应的关系(表和视图)。
/**
* 如果是会话目录中的v1表,则将关系解析为v1关系,或者解析为v2关系。
* 这用于解析DML命令和SELECT查询。
*/
private def lookupRelation(
u: UnresolvedRelation,
timeTravelSpec: Option[TimeTravelSpec] = None): Option[LogicalPlan] = {
// 查找临时视图
lookupTempView(u.multipartIdentifier, u.isStreaming, timeTravelSpec.isDefined).orElse {
// 如果找不到的话,我们将尝试从关系缓存中查找
// 如果我们在视图中解析数据库对象(关系、函数等),我们可能需要当视图被创建后使用当前的 catalog 和 namespace 展开单个或多部分标识符。
expandIdentifier(u.multipartIdentifier) match {
case CatalogAndIdentifier(catalog, ident) =>
val key = catalog.name +: ident.namespace :+ ident.name
// 从关系缓存中查找
AnalysisContext.get.relationCache.get(key).map(_.transform {
case multi: MultiInstanceRelation =>
val newRelation = multi.newInstance()
newRelation.copyTagsFrom(multi)
newRelation
}).orElse {
// 查不到手动加载并创建关系
val table = CatalogV2Util.loadTable(catalog, ident, timeTravelSpec)
val loaded = createRelation(catalog, ident, table, u.options, u.isStreaming)
// 更新缓存
loaded.foreach(AnalysisContext.get.relationCache.update(key, _))
loaded
}
case _ => None
}
}
}
}
怎么查找临时视图的呢?
private def lookupTempView(
identifier: Seq[String],
isStreaming: Boolean = false,
isTimeTravel: Boolean = false): Option[LogicalPlan] = {
// 我们正在解析一个视图并且当视图被创建的时候这个视图名称不是临时视图,我们就在这里早点返回 None
if (isResolvingView && !isReferredTempViewName(identifier)) return None
val tmpView = identifier match {
// 我们的例子中 identifier 就一个:t_user
// 通过 SessionCatalog 来查找临时视图
case Seq(part1) => v1SessionCatalog.lookupTempView(part1)
case Seq(part1, part2) => v1SessionCatalog.lookupGlobalTempView(part1, part2)
case _ => None
}
// 找完了还得校验下
tmpView.foreach {
v =>
if (isStreaming && !v.isStreaming) {
throw QueryCompilationErrors.readNonStreamingTempViewError(identifier.quoted)
}
if (isTimeTravel) {
val target = if (v.isStreaming) "streams" else "views"
throw QueryCompilationErrors.timeTravelUnsupportedError(target)
}
}
tmpView
}
SessionCatalog 中是如何查找到对应临时视图的元数据信息呢?
对 SessionCatalog 困惑的同学先看看这个博客——一篇文章了解 Spark 3.x 的 Catalog 体系
def lookupTempView(table: String): Option[SubqueryAlias] = {
val formattedTable = formatTableName(table)
getTempView(formattedTable).map {
view =>
SubqueryAlias(formattedTable, view)
}
}
先格式化一下表的名称
protected[this] def formatTableName(name: String): String = {
if (conf.caseSensitiveAnalysis) name else name.toLowerCase(Locale.ROOT)
}
获取到对应的元数据信息,在转换成相应的逻辑计划
def getTempView(name: String): Option[View] = synchronized {
getRawTempView(name).map(getTempViewPlan)
}
def getRawTempView(name: String): Option[TemporaryViewRelation] = synchronized {
tempViews.get(formatTableName(name))
}
哦豁~ 可以看出查找临时视图的逻辑就是到 SessionCatalog 的 Map 缓存中取出对应的临时视图,我们看看这个 Map 缓存:
protected val tempViews = new mutable.HashMap[String, TemporaryViewRelation]
我们现在已经很明确,想要找的临时视图的元数据信息就来自这个 HashMap 缓存。
那么,问题是:数据啥时候加进去的?
数据啥时候加进去的?
很明显来自我们例子中下面的代码:
df.createTempView("t_user")
这一步就创建了我们需要的临时视图,我们看下它是怎么实现的~
@throws[AnalysisException]
def createTempView(viewName: String): Unit = withPlan {
createTempViewCommand(viewName, replace = false, global = false)
}
private def createTempViewCommand(
viewName: String,
replace: Boolean,
global: Boolean): CreateViewCommand = {
val viewType = if (global) GlobalTempView else LocalTempView
val tableIdentifier = try {
// 看了第二讲的同学相信对这个不会陌生,和 parsing 阶段的逻辑基本都是类似的
sparkSession.sessionState.sqlParser.parseTableIdentifier(viewName)
} catch {
case _: ParseException => throw QueryCompilationErrors.invalidViewNameError(viewName)
}
// 解析完视图后,构建一个创建视图的命令方便后面来执行
CreateViewCommand(
name = tableIdentifier,
userSpecifiedColumns = Nil,
comment = None,
properties = Map.empty,
originalText = None,
plan = logicalPlan,
allowExisting = false,
replace = replace,
viewType = viewType,
isAnalyzed = true)
}
具体的执行在哪里呢?
@inline private def withPlan(logicalPlan: LogicalPlan): DataFrame = {
Dataset.ofRows(sparkSession, logicalPlan)
}
def ofRows(sparkSession: SparkSession, logicalPlan: LogicalPlan): DataFrame =
sparkSession.withActive {
val qe = sparkSession.sessionState.executePlan(logicalPlan)
qe.assertAnalyzed()
new Dataset[Row](qe, RowEncoder(qe.analyzed.schema))
}
我们看到了啥?这不就是本讲源码解析的开头吗?
我们仿佛又回到了原点。
只不过,我们这次针对的是创建视图的命令,而本讲分析的是那个 SQL 语句。
所以,接下来和上面的逻辑不都差不多嘛,本质上还是应用一个个的规则!
那么核心区别在哪里呢?
我们既然针对的是创建视图的命令,有命令就必然要执行,所以,关键点在
CreateViewCommand 的 run 方法里面:
override def run(sparkSession: SparkSession): Seq[Row] = {
if (!isAnalyzed) {
throw QueryCompilationErrors.logicalPlanForViewNotAnalyzedError()
}
// 这是一个已经完成 analysis 阶段的计划
val analyzedPlan = plan
// 如果用户指定的列不为空并且和 analysis 阶段的输出列不等就抛出异常
if (userSpecifiedColumns.nonEmpty &&
userSpecifiedColumns.length != analyzedPlan.output.length) {
throw QueryCompilationErrors.createViewNumColumnsMismatchUserSpecifiedColumnLengthError(
analyzedPlan.output.length, userSpecifiedColumns.length)
}
// 获取到 SessionCatalog
val catalog = sparkSession.sessionState.catalog
// 当创建一个永久视图时,不允许引用临时的对象
// 这里应当在 qe.assertAnalyzed() 之后被调用,也就是说,子节点都被解析过了
verifyTemporaryObjectsNotExists(isTemporary, name, analyzedPlan, referredTempFunctions)
verifyAutoGeneratedAliasesNotExists(analyzedPlan, isTemporary, name)
// 临时视图,我们的例子就是这个类型
if (viewType == LocalTempView) {
val aliasedPlan = aliasPlan(sparkSession, analyzedPlan)
val tableDefinition = createTemporaryViewRelation(
name,
sparkSession,
replace,
catalog.getRawTempView,
originalText,
analyzedPlan,
aliasedPlan,
referredTempFunctions)
// 调用 SessionCatalog 创建临时视图的方法
catalog.createTempView(name.table, tableDefinition, overrideIfExists = replace)
// 全局临时视图
} else if (viewType == GlobalTempView) {
val db = sparkSession.sessionState.conf.getConf(StaticSQLConf.GLOBAL_TEMP_DATABASE)
val viewIdent = TableIdentifier(name.table, Option(db))
val aliasedPlan = aliasPlan(sparkSession, analyzedPlan)
val tableDefinition = createTemporaryViewRelation(
viewIdent,
sparkSession,
replace,
catalog.getRawGlobalTempView,
originalText,
analyzedPlan,
aliasedPlan,
referredTempFunctions)
catalog.createGlobalTempView(name.table, tableDefinition, overrideIfExists = replace)
// 如果是永久视图的话, SessionCatalog 的缓存中有这个视图名称
} else if (catalog.tableExists(name)) {
val tableMetadata = catalog.getTableMetadata(name)
if (allowExisting) {
// 如果遇到这种类型的 SQL: `CREATE VIEW IF NOT EXISTS v0 AS SELECT ...`. 当目标视图不存在的时候就什么也不做
} else if (tableMetadata.tableType != CatalogTableType.VIEW) {
throw QueryCompilationErrors.tableIsNotViewError(name)
} else if (replace) {
// 检测到循环的视图引用 CREATE OR REPLACE VIEW.
val viewIdent = tableMetadata.identifier
checkCyclicViewReference(analyzedPlan, Seq(viewIdent), viewIdent)
// 在替换掉一个已经存在的视图的时候要把缓存给干掉
logDebug(s"Try to uncache ${
viewIdent.quotedString} before replacing.")
CommandUtils.uncacheTableOrView(sparkSession, viewIdent.quotedString)
// 处理这种类型的 SQL: `CREATE OR REPLACE VIEW v0 AS SELECT ...`
// 老的视图里面的信息我们什么都不管,把它直接干掉再创建一个新的
catalog.dropTable(viewIdent, ignoreIfNotExists = false, purge = false)
catalog.createTable(prepareTable(sparkSession, analyzedPlan), ignoreIfExists = false)
} else {
// 处理这种类型的 SQL: `CREATE VIEW v0 AS SELECT ...`.
// 当目标视图已经存在的时候就抛出异常
QueryCompilationErrors.viewAlreadyExistsError(name)
}
} else {
// 如果不存在就创建视图
catalog.createTable(prepareTable(sparkSession, analyzedPlan), ignoreIfExists = false)
}
Seq.empty[Row]
}
SessionCatalog 里面创建临时视图的方法是怎样的?
def createTempView(
name: String,
viewDefinition: TemporaryViewRelation,
overrideIfExists: Boolean): Unit = synchronized {
val table = formatTableName(name)
if (tempViews.contains(table) && !overrideIfExists) {
throw new TempTableAlreadyExistsException(name)
}
tempViews.put(table, viewDefinition)
}
这里的tempViews 就是我们前面讲到的那个 HashMap,说明数据的来源找到了~
现在又一个问题来啦,数据长啥样子呢?
我们先把这个问题搁置,看看上面 3 步骤中的最后一个步骤:解析视图
解析视图
/**
* 当前 catalog 和 namespace 可能与视图创建时不同,我们必须在这里解析视图的逻辑计
* 划,catalog 和 namespace 存储在视图元数据中。这是通过将 catalog 和
* namespace 保持在“AnalysisContext”中来实现的,当解析单组件名称的关系时
* analyzer将会查看方法`AnalysisContext.catalogAndNamespace`。如
* 果`AnalysisContext.catalogAndNamespace`为非空,analyzer将展开单组件名称
* 并使用它,而不是当前的 catalog 和 namespace。
*/
private def resolveViews(plan: LogicalPlan): LogicalPlan = plan match {
// 视图的子级应该是解析自“desc.viewText”的一个逻辑计划,变量`viewText`应该被定义,否则我们在生成视图算子时会抛出一个错误。
case view @ View(desc, isTempView, child) if !child.resolved =>
// 解析子节点中所有的 UnresolvedRelations 和视图
val newChild = AnalysisContext.withAnalysisContext(desc) {
// 嵌套视图的深度
val nestedViewDepth = AnalysisContext.get.nestedViewDepth
// 最大允许的深度
val maxNestedViewDepth = AnalysisContext.get.maxNestedViewDepth
if (nestedViewDepth > maxNestedViewDepth) {
throw QueryCompilationErrors.viewDepthExceedsMaxResolutionDepthError(
desc.identifier, maxNestedViewDepth, view)
}
SQLConf.withExistingConf(View.effectiveSQLConf(desc.viewSQLConfigs, isTempView)) {
// 执行子节点
executeSameContext(child)
}
}
// 由于在AnalysisContext之外,未解析的运算符在视图内部,可能解决不正确。
checkAnalysis(newChild)
view.copy(child = newChild)
// 封装表名称的子查询别名对象
case p @ SubqueryAlias(_, view: View) =>
// 副本递归调用
p.copy(child = resolveViews(view))
case _ => plan
}
这里面本质上还是个递归调用嵌套视图解析的过程,没啥值得多描述的地方。
应用规则后
经过了上面的一系列步骤,规则 ResolveRelations 应用后,生成的逻辑计划长这样:
'Project [*]
+- SubqueryAlias t_user
+- View (`t_user`, [addr#7,age#8L,name#9,sex#10])
+- Relation [addr#7,age#8L,name#9,sex#10] json
这里我们再回到上面的小问题:数据长啥样子呢?
数据长啥样子呢?
我们在创建视图的命令执行前得到的是一个 LogicalRelation 类型的逻辑计划,所以关键在于这个计划是怎么打印成上面那样的?
LogicalRelation.simpleString
override def simpleString(maxFields: Int): String = {
s"Relation ${
catalogTable.map(_.identifier.unquotedString).getOrElse("")}" +
s"[${
truncatedString(output, ",", maxFields)}] $relation"
}
AttributeReference.toString
override def toString: String = s"$name#${
exprId.id}$typeSuffix$delaySuffix"
结合这两段代码实际上我们明白了一个困惑,上面的 #7,#8 实际上就是代表的表达式 ID啊,这个表达式就是命名表达式(NamedExpression),我们在博客中实际上多次提到它,忘记的同学不妨回看下前面的内容。
ResolveReferences
ResolveReferences 规则的作用是将 UnresolvedAttribute 替换为逻辑计划节点子节点的具体 AttributeReference。
那么,它是怎么实现的呢?
还是老样子,先看 apply 方法:
apply
def apply(plan: LogicalPlan): LogicalPlan = plan.resolveOperatorsUpWithPruning(
AlwaysProcess.fn, ruleId) {
// 此查询计划的所有子项并没有都被解析
case p: LogicalPlan if !p.childrenResolved => p
// 等待规则 `DeduplicateRelations` 先解析冲突的属性
case p: LogicalPlan if hasConflictingAttrs(p) => p
// 如果投影中包含 * 号,则去扩展它。
case p: Project if containsStar(p.projectList) =>
p.copy(projectList = buildExpandedProjectList(p.projectList, p.child))
Project [*]
我们的例子中包含的 Project 投影对象里面很明显有个 * 号。
这里值得注意的是经过了
ResolveRelations规则后,我们得到的逻辑计划实际上是个树状结果,其中只有Project节点(也就是根节点)才会走到下面的分支(我们调用规则实际上就是递归调用的过程,先解决下面的子节点,再解决上面的父节点)。
private def buildExpandedProjectList(
exprs: Seq[NamedExpression],
child: LogicalPlan): Seq[NamedExpression] = {
exprs.flatMap {
// 使用 Dataframe/Dataset 的 API: testData2.groupBy($"a", $"b").agg($"*")
case s: Star => expand(s, child)
// 使用 SQL 的 API 但是没有运行规则 ResolveAlias: SELECT * FROM testData2 group by a, b
case UnresolvedAlias(s: Star, _) => expand(s, child)
// 如果 exprs 是一个列表类型有多个元素,并且其中包含 * 号
case o if containsStar(o :: Nil) => expandStarExpression(o, child) :: Nil
case o => o :: Nil
}.map(_.asInstanceOf[NamedExpression])
}
通过 Project [*] 我们知道传入的 exprs 实际上就是这个 *,而在第二讲中,我们知道了 * 的类型是UnresolvedStar,它是Star类型的子类,所以上面的调用中很明显走的是第一个分支。
private def expand(s: Star, plan: LogicalPlan): Seq[NamedExpression] = {
// 这个是用来捕获闭包内部抛出的 AnalysisExceptions 的,同时在异常上会附带一些 origin 信息
withPosition(s) {
try {
// 调用 UnresolvedStar 的 expand 方法
s.expand(plan, resolver)
} catch {
case e: AnalysisException =>
AnalysisContext.get.outerPlan.map {
// 只有 Project 和 Aggregate 可以有 star 表达式
case u @ (_: Project | _: Aggregate) =>
Try(s.expand(u.children.head, resolver)) match {
case Success(expanded) => expanded.map(wrapOuterReference)
case Failure(_) => throw e
}
// 不要使用外部计划来解析 star 表达式
// 因为 star 的使用无效
case _ => throw e
}.getOrElse {
throw e }
}
}
}
*
我们再看看 UnresolvedStar 的 expand 方法
override def expand(
input: LogicalPlan,
resolver: Resolver): Seq[NamedExpression] = {
// 如果没有指明任何表,使用所有的非隐藏属性
if (target.isEmpty) return input.output
// 如果指明了一个表,隐藏的属性也得使用
val hiddenOutput = input.metadataOutput.filter(_.supportsQualifiedStar)
val expandedAttributes = (hiddenOutput ++ input.output).filter(
matchedQualifier(_, target.get, resolver))
if (expandedAttributes.nonEmpty) return expandedAttributes
// 尝试将其解析为结构体类型扩展。
val attribute = input.resolve(target.get, resolver)
if (attribute.isDefined) {
// 如果目标可以解析成子节点的一个属性,那么它一定是个结构体,需要扩展
attribute.get.dataType match {
case s: StructType => s.zipWithIndex.map {
case (f, i) =>
val extract = GetStructField(attribute.get, i)
Alias(extract, f.name)()
}
case _ =>
throw QueryCompilationErrors.starExpandDataTypeNotSupportedError(target.get)
}
} else {
val from = input.inputSet.map(_.name).mkString(", ")
val targetString = target.get.mkString(".")
throw QueryCompilationErrors.cannotResolveStarExpandGivenInputColumnsError(
targetString, from)
}
}
由于我们只是一个*,不是类似 a.* 这样的,故 target 就是空的,我们直接在第一步就返回了,即返回 input.output,这里就来问题了:input 是什么呢?
input
通过之前 AnalysisHelper.resolveOperatorsUpWithPruning (即之前递归应用偏函数一节) 的源码解析就可以看出来:
每一个规则的输入就是其子节点应用规则后的输出
故,input 就是 Project [*] 的子节点应用规则后的输出,也就是
+- SubqueryAlias t_user
+- View (`t_user`, [addr#7,age#8L,name#9,sex#10])
+- Relation [addr#7,age#8L,name#9,sex#10] json
SubqueryAlias及其子节点应用规则后未发生变化。
故,input.output 即 SubqueryAlias.output
SubqueryAlias.output
override def output: Seq[Attribute] = {
// 将 标识符 拼接起来
val qualifierList = identifier.qualifier :+ alias
child.output.map(_.withQualifier(qualifierList))
}
SubqueryAlias.output 所做的事情就是将包括子节点的标识符拼接起来。
最终解析后的逻辑计划长啥样子呢?
Project [addr#8, age#9L, name#10, sex#11]
+- SubqueryAlias t_user
+- View (`t_user`, [addr#8,age#9L,name#10,sex#11])
+- Relation [addr#8,age#9L,name#10,sex#11] json
照例,我们还是画一个表格将上面的输出和具体的源码对应起来:
| 打印 | 对应的源码 | 说明 |
|---|---|---|
| Project | org.apache.spark.sql.catalyst.plans.logical.Project | 投影对象 |
| [addr#8, age#9L, name#10, sex#11] | SubqueryAlias.output | 将包括子节点的标识符拼接起来,其中数字代表的是 NamedExpression 的 ID。 |
| SubqueryAlias | org.apache.spark.sql.catalyst.plans.logical.SubqueryAlias | 封装表名称的子查询别名对象 |
| t_user | SubqueryAlias.alias | 表别名 |
| View | org.apache.spark.sql.catalyst.plans.logical.View | 视图对象 |
| (t_user, [addr#8,age#9L,name#10,sex#11]) | View.simpleString | 表的标识符和属性序列,其中数字代表的是 NamedExpression 的 ID。 |
| Relation [addr#8,age#9L,name#10,sex#11] json | LogicalRelation.simpleString | 属性序列和关系名称,其中数字代表的是 NamedExpression 的 ID。 |
为啥和 Analyzed Logical Plan 的输出不太一样?
我们在第一讲中实际上已经提前给出了 analysis 阶段的最终输出了:
== Analyzed Logical Plan ==
addr: array<string>, age: bigint, name: string, sex: string
Project [addr#7, age#8L, name#9, sex#10]
+- SubqueryAlias t_user
+- View (`t_user`, [addr#7,age#8L,name#9,sex#10])
+- Relation [addr#7,age#8L,name#9,sex#10] json
为啥和上面的逻辑计划打印不太一样呢?
我们可以从 QueryExecution.writePlans 中找到答案
append("\n== Analyzed Logical Plan ==\n")
try {
if (analyzed.output.nonEmpty) {
append(
truncatedString(
analyzed.output.map(o => s"${
o.name}: ${
o.dataType.simpleString}"), ", ", maxFields)
)
append("\n")
}
QueryPlan.append(analyzed, append, verbose, addSuffix, maxFields)
可以看到,在打印生成的逻辑计划之前,还会先打印属性名称和类型。
小结
本讲是对 Spark SQL 工作流程中 analysis 阶段的源码解析。
上来我们就明确了自己的目标——我们要对 parsing 阶段生成的 AST 进行进一步的解析。
确定目标后,我们先盘算了手头已有的东西——一个临时视图:t_user 以及从 JSON 文件中推测到了字段名称和字段类型。
然后我们开始主流程的源码解析,从入口开始,讲到了执行和校验。
我们这时接触到了规则批(Batch)这个概念,并且我们梳理了所有的规则批。
接着我们梳理了所有的校验规则。
由于篇幅的限制,我们不可能做到详解每一种解析规则具体是怎么实现的。
所以,我们就回到了我们最初的例子,通过分析这个简单直接的例子能够帮助我们触类旁通。
我们详细解析了ResolveRelations 和 ResolveReferences 这两个规则是如何一步步的作用于我们的逻辑计划,最终完成 analysis 阶段的解析的。
至此,analysis 阶段的基本流程相信大家已经一览无余了。
麻烦看到这里的同学帮忙三连支持一波,万分感谢~