本文我们通过源码,来介绍下spark sql的执行流程。 Spark sql是spark内部最核心,也是社区最活跃的组件。Spark SQL支持在Spark中执行SQL,或者HiveQL的关系查询表达式。列式存储的类RDD(DataSet/DataFrame)数据类型以及对sql语句的支持使它更容易上手,同时,它对数据的抽取、清洗的特性,使它广泛的用于etl,甚至是机器学习领域。因此,saprk sql较其他spark组件,获得了更多的使用者。 下文,我们首先通过查看一个简单的sql的执行计划,对sql的执行流程有一个简单的认识,后面将通过对sql优化器catalyst的每个部分的介绍,来让大家更深入的了解sql后台的执行流程。由于此模板中代码较多,我们在此仅就执行流程中涉及到的主要代码进行介绍,方便大家更快地浏览spark sql的源码。本文中涉及到的源码都是最新版本spark 2.1.1的。
1. catalyst整体执行流程介绍
1.1 catalyst整体执行流程
说到spark sql不得不提的当然是Catalyst了。Catalyst是spark sql的核心,是一套针对spark sql 语句执行过程中的查询优化框架。因此要理解spark sql的执行流程,理解Catalyst的工作流程是理解spark sql的关键。而说到Catalyst,就必须得上下面这张图1了,这张图描述了spark sql执行的全流程。其中,长方形框内为catalyst的工作流程。
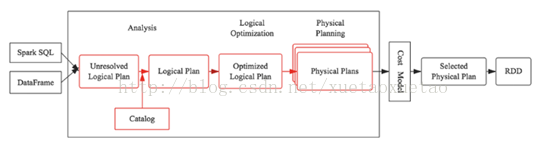
图1 spark sql 执行流程图
SQL语句首先通过Parser模块被解析为语法树,此棵树称为Unresolved Logical Plan;Unresolved Logical Plan通过Analyzer模块借助于Catalog中的表信息解析为Logical Plan;此时,Optimizer再通过各种基于规则的优化策略进行深入优化,得到Optimized Logical Plan;优化后的逻辑执行计划依然是逻辑的,并不能被Spark系统理解,此时需要将此逻辑执行计划转换为Physical Plan。
1.2 一个简单sql语句的执行
为了更好的对整个过程进行理解,下面通过一个简单的sql示例来查看采用catalyst框架执行sql的过程。示例代码如下:
-
object TestSql { -
case class Student(id:Long,name:String,chinese:String,math:String,English:String,age:Int) -
case class Score(sid:Long,weight1:String,weight2:String,weight3:String) -
def main(args: Array[String]): Unit = { -
//使用saprkSession初始化spark运行环境 -
val spark=SparkSession.builder().appName("Spark SQL basic example").config("spark.some.config.option", "some-value").getOrCreate() -
//引入spark sql的隐式转换 -
import sqlContext.implicits._ -
//读取第一个文件的数据并转换成DataFrame -
val testP1 = spark.sparkContext.textFile("/home/dev/testP1").map(_.split(" ")).map(p=>Student(p(0).toLong,p(1),p(2),p(3),p(4),p(5).trim.toInt)).toDF() -
//注册成表 -
testP1.registerTempTable("studentTable") -
//读取第二个文件的数据并转换成DataFrame -
val testp2 = spark.sparkContext.textFile("/home/dev/testP2").map(_.split(" ")).map(p=>Score(p(0).toLong,p(1),p(2),p(3))).toDF() -
//注册成表 -
testp2.registerTempTable("scoreTable") -
//查看sql的逻辑执行计划 -
val dataframe = spark.sql("select sum(chineseScore) from " + -
"(select x.id,x.chinese+20+30 as chineseScore,x.math from studentTable x inner join scoreTable y on x.id=y.sid)z" + -
" where z.chineseScore <100").map(p=>(p.getLong(0))).collect.foreach(println)
此例也是针对spark2.1.1版本的,程序的入口是SparkSession。由于此例超级简单,做过spark的人一眼就能看出,而且每行代码都带有中文注释,所以在这里,我们就不做具体的介绍了。
这里涉及到的sql查询就是最后一句,通过spark shell可以看到该sql查询的逻辑执行计划和物理执行计划。进入sparkshell后,输入一下代码即可显示此sql查询的执行计划。
-
spark.sql("select sum(chineseScore) from " + -
"(select x.id,x.chinese+20+30 as chineseScore,x.math from studentTable x inner join scoreTable y on x.id=y.sid)z" + -
" where z.chineseScore <100").explain(true)
这里,是使用DataSet的explain函数实现逻辑执行计划和物理执行计划的打印,调用explain的源码如下:
-
/** -
* Prints the plans (logical and physical) to the console for debugging purposes. -
* -
* @group basic -
* @since 1.6.0 -
*/ -
def explain(extended: Boolean): Unit = { -
val explain = ExplainCommand(queryExecution.logical, extended = extended) -
sparkSession.sessionState.executePlan(explain).executedPlan.executeCollect().foreach { -
// scalastyle:off println -
r => println(r.getString(0)) -
// scalastyle:on println -
} -
}
显示在spark shell中的unresolved logical plan、resolved logical plan、optimized logical plan和physical plan如下图2所示:
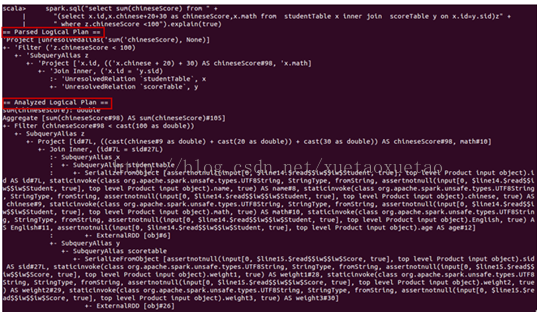
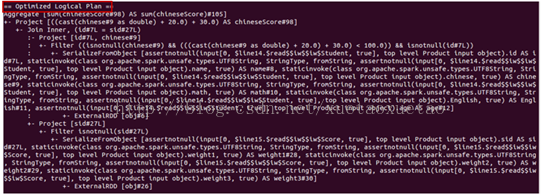
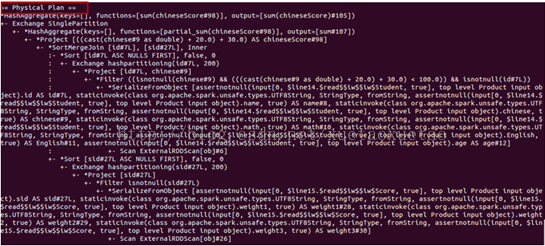
图2 spark sql 执行计划
将上图2中的Parsed Logical Plan表示成树结构如下图3所示。Catalyst中的parser将图左中一个sql查询的字符串解析成图右的一个AST语法树,该语法树就称为Parsed Logical Plan。解析后的逻辑计划基本形成了执行计划的基础骨架,此逻辑执行计划被称为 unresolved Logical Plan,也就是说该逻辑计划是无法执行的,系统并不知道语法树中的每个词是神马意思,如图中的filter,join,以及studentTable等。
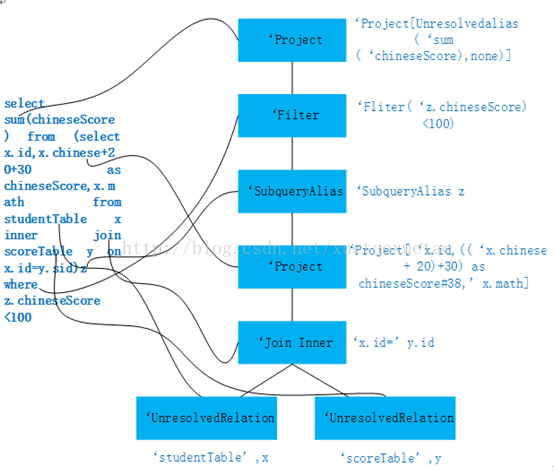
图3 Parsed Logical Plan树
将上图2中的Analyzed logical plan,即Resolved logical plan表示成树结构如下图4所示。Catalyst的analyzer将unresolved Logical Plan解析成resolved Logical Plan。Analyzer借助cataLog(下文介绍)中表的结构信息、函数信息等将此逻辑计划解析成可被识别的逻辑执行计划。
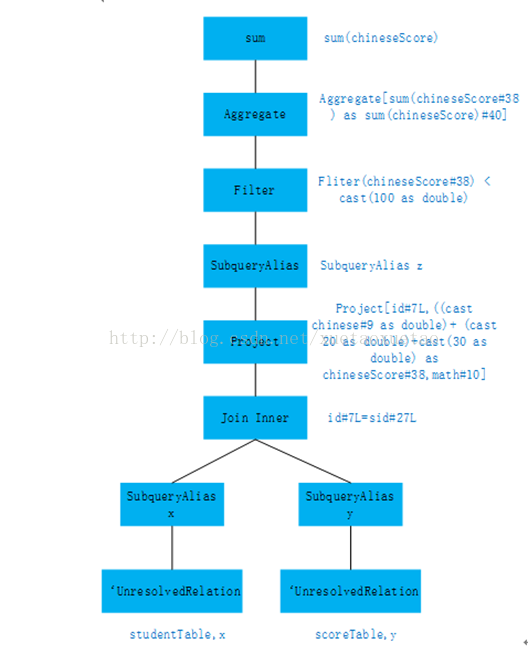
图4 Analyzed logical plan树
optimized logical plan与physical plan的树结构跟上面两种逻辑执行计划树结构的画法相似,下面就不在画了。从optimized logical plan可出,此次优化使用了Filter下推的策略,即将Filter下推到子查询中实现,继而减少后续数据的处理量。
前面我们展示了catalyst执行一段sql语句的大致流程,下面我们就从源代码的角度来分析catalyst的每个部分内部如何实现,以及它们之间是如何承接的。
2. catalyst各个模块介绍
本章我们通过分析上面的例子代码的调用过程来分析catalys各个部分的主要代码模块,spark sql的入口是最后一句,SparkSession类里的sql函数,传入一个sql字符串,返回一个dataframe对象。入口调用的代码如下:
-
code 1 -
def sql(sqlText: String): DataFrame = { -
Dataset.ofRows(self, sessionState.sqlParser.parsePlan(sqlText)) -
}
2.1 Parser
从入口代码可看出,首先调用sqlParser的parsePlan方法,将sql字符串解析成unresolved逻辑执行计划。parsePlan的具体实现在AbstractSqlParser类中。如下:
-
code 2 -
/** Creates LogicalPlan for a given SQL string. */ -
override def parsePlan(sqlText: String): LogicalPlan = parse(sqlText) { parser => -
astBuilder.visitSingleStatement(parser.singleStatement()) match { -
case plan: LogicalPlan => plan -
case _ => -
val position = Origin(None, None) -
throw new ParseException(Option(sqlText), "Unsupported SQL statement", position, position) -
} -
}
由上段代码可看出,调用的主函数是parse,继续进入到parse中,代码如下:
-
code 3 -
protected def parse[T](command: String)(toResult: SqlBaseParser => T): T = { -
logInfo(s"Parsing command: $command") -
val lexer = new SqlBaseLexer(new ANTLRNoCaseStringStream(command)) -
lexer.removeErrorListeners() -
lexer.addErrorListener(ParseErrorListener) -
val tokenStream = new CommonTokenStream(lexer) -
val parser = new SqlBaseParser(tokenStream) -
parser.addParseListener(PostProcessor) -
parser.removeErrorListeners() -
parser.addErrorListener(ParseErrorListener) -
try { -
try { -
// first, try parsing with potentially faster SLL(Strong-LL) mode -
parser.getInterpreter.setPredictionMode(PredictionMode.SLL) -
toResult(parser) -
} -
} -
}
从parse函数可以看出,这里对于SQL语句的解析采用的是ANTLR 4,这里使用到了两个类:词法解析器SqlBaseLexer和语法解析器SqlBaseParser
SqlBaseLexer和SqlBaseParser均是使用ANTLR 4自动生成的Java类。这里,采用这两个解析器将SQL语句解析成了ANTLR 4的语法树结构ParseTree。之后,在parsePlan(见code 2)中,使用AstBuilder(AstBuilder.scala)将ANTLR 4语法树结构转换成catalyst表达式,即logical plan。
此时生成的逻辑执行计划成为unresolved logical plan。只是将sql串解析成类似语法树结构的执行计划,系统并不知道每个词所表示的意思,离真正能够执行还差很远。
2.2 Analyzer
parser生成逻辑执行计划后,使用analyzer将逻辑执行计划进行分析。我们回到Dataset的ofRows函数:
-
code 4 -
def ofRows(sparkSession: SparkSession, logicalPlan: LogicalPlan): DataFrame = { -
val qe = sparkSession.sessionState.executePlan(logicalPlan) -
qe.assertAnalyzed() -
new Dataset[Row](sparkSession, qe, RowEncoder(qe.analyzed.schema)) -
}
这里首先创建了queryExecution类对象,QueryExecution中定义了sql执行过程中的关键步骤,是sql执行的关键类,返回一个dataframe类型的对象。QueryExecution类中的成员都是lazy的,被调用时才会执行。只有等到程序中出现action算子时,才会调用 queryExecution类中的executedPlan成员,原先生成的逻辑执行计划才会被优化器优化,并转换成物理执行计划真正的被系统调用执行。
QueryExecution类的主要成员如下所示。其中定义了解析器analyzer、优化器optimizer以及生成物理执行计划的sparkPlan。
-
code 5 -
//调用analyzer解析器 -
lazy val analyzed: LogicalPlan = { -
SparkSession.setActiveSession(sparkSession) -
sparkSession.sessionState.analyzer.execute(logical) -
} -
lazy val withCachedData: LogicalPlan = { -
assertAnalyzed() -
assertSupported() -
sparkSession.sharedState.cacheManager.useCachedData(analyzed) -
} -
//调用optimizer优化器 -
lazy val optimizedPlan: LogicalPlan = sparkSession.sessionState.optimizer.execute(withCachedData) -
//将优化后的逻辑执行计划转换成物理执行计划 -
lazy val sparkPlan: SparkPlan = { -
SparkSession.setActiveSession(sparkSession) -
// TODO: We use next(), i.e. take the first plan returned by the planner, here for now, -
// but we will implement to choose the best plan. -
planner.plan(ReturnAnswer(optimizedPlan)).next() -
} -
// executedPlan should not be used to initialize any SparkPlan. It should be -
// only used for execution. -
lazy val executedPlan: SparkPlan = prepareForExecution(sparkPlan) -
/** -
* Prepares a planned [[SparkPlan]] for execution by inserting shuffle operations and internal -
* row format conversions as needed. -
*/ -
protected def prepareForExecution(plan: SparkPlan): SparkPlan = { -
preparations.foldLeft(plan) { case (sp, rule) => rule.apply(sp) } -
}
前文有介绍,analyzer的主要职责是将parser生成的unresolved logical plan解析生成logical plan。调用analyzer的代码在QueryExecution中,code 5中已经有贴出。此模块的主函数来自于analyzer的父类RuleExecutor。主函数execute实现在RuleExecutor类中,代码如下:
-
code 6 -
/** -
* Executes the batches of rules defined by the subclass. The batches are executed serially -
* using the defined execution strategy. Within each batch, rules are also executed serially. -
*/ -
def execute(plan: TreeType): TreeType = { -
var curPlan = plan -
batches.foreach { batch => -
val batchStartPlan = curPlan -
var iteration = 1 -
var lastPlan = curPlan -
var continue = true -
// Run until fix point (or the max number of iterations as specified in the strategy. -
while (continue) { -
curPlan = batch.rules.foldLeft(curPlan) { -
case (plan, rule) => -
val startTime = System.nanoTime() -
val result = rule(plan) -
val runTime = System.nanoTime() - startTime -
RuleExecutor.timeMap.addAndGet(rule.ruleName, runTime) -
if (!result.fastEquals(plan)) { -
logTrace( -
s""" -
|=== Applying Rule ${rule.ruleName} === -
|${sideBySide(plan.treeString, result.treeString).mkString("\n")} -
""".stripMargin) -
} -
result -
} -
iteration += 1 -
}
此函数实现了针对analyzer类中定义的每一个batch(类别),按照batch中定义的fix point(策略)和rule(规则)对Unresolved的逻辑计划进行解析。其中batch的结构如下:
-
code 7 -
/** A batch of rules. */ -
protected case class Batch(name: String, strategy: Strategy, rules: Rule[TreeType]*)
由于在analyzer的batchs中定义了多个规则,代码段很长,因此这里就不再贴出,有需要的请去spark的源码中找到Analyzer类查看。
在batchs里的这些batch中,Resolution是最常用的,从字面意思就可以看出其用途,就是将parser解析后的逻辑计划里的各个节点,转变成resolved节点。而其中ResolveRelations是比较好理解的一个rule(规则),这一步调用了catalog这个对象,Catalog对象里面维护了一个tableName,Logical Plan的HashMap结果。通过这个Catalog目录来寻找当前表的结构,从而从中解析出这个表的字段,如UnResolvedRelations 会得到一个tableWithQualifiers。(即表和字段)。catalog中缓存表名称和逻辑执行计划关系的代码如下:
-
code 8 -
/** -
* A cache of qualified table names to table relation plans. -
*/ -
val tableRelationCache: Cache[QualifiedTableName, LogicalPlan] = { -
val cacheSize = conf.tableRelationCacheSize -
CacheBuilder.newBuilder().maximumSize(cacheSize).build[QualifiedTableName, LogicalPlan]() -
}
2.3 Optimizer
optimizer是catalyst中关键的一个部分,提供对sql查询的一个优化。optimizer的主要职责是针对Analyzer的resolved logical plan,根据不同的batch优化策略),来对执行计划树进行优化,优化逻辑计划节点(Logical Plan)以及表达式(Expression),同时,此部分也是转换成物理执行计划的前置。optimizer的调用在QueryExecution类中,代码code 5中已经贴出。
其工作方式与上面讲的Analyzer类似,因为它们的主函数executor都是继承自RuleExecutor。因此,optimizer的主函数如上面的code 6代码,这里就不在贴出。optimizer的batchs(优化策略)定义如下:
-
code 9 -
def batches: Seq[Batch] = { -
// Technically some of the rules in Finish Analysis are not optimizer rules and belong more -
// in the analyzer, because they are needed for correctness (e.g. ComputeCurrentTime). -
// However, because we also use the analyzer to canonicalized queries (for view definition), -
// we do not eliminate subqueries or compute current time in the analyzer. -
Batch("Finish Analysis", Once, -
EliminateSubqueryAliases, -
EliminateView, -
ReplaceExpressions, -
ComputeCurrentTime, -
GetCurrentDatabase(sessionCatalog), -
RewriteDistinctAggregates, -
ReplaceDeduplicateWithAggregate) :: -
////////////////////////////////////////////////////////////////////////////////////////// -
// Optimizer rules start here -
////////////////////////////////////////////////////////////////////////////////////////// -
// - Do the first call of CombineUnions before starting the major Optimizer rules, -
// since it can reduce the number of iteration and the other rules could add/move -
// extra operators between two adjacent Union operators. -
// - Call CombineUnions again in Batch("Operator Optimizations"), -
// since the other rules might make two separate Unions operators adjacent. -
Batch("Union", Once, -
CombineUnions) :: -
Batch("Pullup Correlated Expressions", Once, -
PullupCorrelatedPredicates) :: -
Batch("Subquery", Once, -
OptimizeSubqueries) :: -
Batch("Replace Operators", fixedPoint, -
ReplaceIntersectWithSemiJoin, -
ReplaceExceptWithAntiJoin, -
ReplaceDistinctWithAggregate) :: -
Batch("Aggregate", fixedPoint, -
RemoveLiteralFromGroupExpressions, -
RemoveRepetitionFromGroupExpressions) :: -
Batch("Operator Optimizations", fixedPoint, -
// Operator push down -
PushProjectionThroughUnion, -
ReorderJoin, -
EliminateOuterJoin, -
PushPredicateThroughJoin, -
PushDownPredicate, -
LimitPushDown(conf), -
ColumnPruning, -
InferFiltersFromConstraints, -
// Operator combine -
CollapseRepartition, -
CollapseProject, -
CollapseWindow, -
CombineFilters, -
CombineLimits, -
CombineUnions, -
// Constant folding and strength reduction -
NullPropagation(conf), -
FoldablePropagation, -
OptimizeIn(conf), -
ConstantFolding, -
ReorderAssociativeOperator, -
LikeSimplification, -
BooleanSimplification, -
SimplifyConditionals, -
RemoveDispensableExpressions, -
SimplifyBinaryComparison, -
PruneFilters, -
EliminateSorts, -
SimplifyCasts, -
SimplifyCaseConversionExpressions, -
RewriteCorrelatedScalarSubquery, -
EliminateSerialization, -
RemoveRedundantAliases, -
RemoveRedundantProject, -
SimplifyCreateStructOps, -
SimplifyCreateArrayOps, -
SimplifyCreateMapOps) :: -
Batch("Check Cartesian Products", Once, -
CheckCartesianProducts(conf)) :: -
Batch("Join Reorder", Once, -
CostBasedJoinReorder(conf)) :: -
Batch("Decimal Optimizations", fixedPoint, -
DecimalAggregates(conf)) :: -
Batch("Typed Filter Optimization", fixedPoint, -
CombineTypedFilters) :: -
Batch("LocalRelation", fixedPoint, -
ConvertToLocalRelation, -
PropagateEmptyRelation) :: -
Batch("OptimizeCodegen", Once, -
OptimizeCodegen(conf)) :: -
Batch("RewriteSubquery", Once, -
RewritePredicateSubquery, -
CollapseProject) :: Nil -
}
由此可以看出,Spark 2.1.1版本增加了更多的优化策略,因此如果要提高spark sql程序的性能,升级spark版本是非常必要的。
其中,"Operator Optimizations",即操作优化是使用最多的,也是比较好理解的优化操作。"Operator Optimizations"中包括的规则有PushProjectionThroughUnion,ReorderJoin等。
PushProjectionThroughUnion策略是将左边子查询的Filter或者是projections移动到union的右边子查询中。例如针对下面代码
-
case class a:item1:String,item2:String,item3:String -
case class b:item1:String,item2:String -
select a.item1,b.item2 from a where a.item1>'example' from a union all (select item1,item2 from b )
此时,通过PushProjectionThroughUnion规则后,查询优化器会将sql改为下面的sql,即将Filter右移到了union的右端。如下所示。
-
select a.item1,b.item2 from a where a.item1>’example’ union all (select item1,item2 from b where item1>’example’)
RorderJoin,顾名思义,就是对多个join操作进行重新排序。具体操作就是将一系列的带有join的子执行计划进行排序,尽可能地将带有条件过滤的子执行计划下推到执行树的最底层,这样能尽可能地减少join的数据量。
例如下面代码中是三个表做join操作,而过滤条件是针对表a的,但熟悉sql的人就会发现对a中字段item1的过滤可以挪到子查询中,这样可以减少join的时候数据量,如果满足此过滤条件的记录比较少,则可以大大地提高join的性能。
-
case class b:item1:String,item2:String -
select a.item1,d.item2 from a where a.item1> ‘example’ join (select b.item1,b.item2 from b join c on b.item1=c.item1) d on a.item1= d.item1
2.4 SparkPlann
optimizer将逻辑执行计划优化后,接着该SparkPlan登场了,SparkPlann将optimized logical plan转换成physical plans。执行代码如下:
-
code 10 -
lazy val sparkPlan: SparkPlan = { -
SparkSession.setActiveSession(sparkSession) -
// TODO: We use next(), i.e. take the first plan returned by the planner, here for now, -
// but we will implement to choose the best plan. -
planner.plan(ReturnAnswer(optimizedPlan)).next() -
}
其中,planner为SparkPlanner类的对象,对象的创建如下code 11所示。该对象中定义了一系列的执行策略,包括LeftSemiJoin 、HashJoin等等,这些策略用来指定实际查询时所做的操作。SparkPlanner中定义的策略如下code 12所示:
-
code 11 -
def strategies: Seq[Strategy] = -
extraStrategies ++ ( -
FileSourceStrategy :: -
DataSourceStrategy :: -
SpecialLimits :: -
Aggregation :: -
JoinSelection :: -
InMemoryScans :: -
BasicOperators :: Nil)
-
code 12 -
/** -
* Planner that converts optimized logical plans to physical plans. -
*/ -
def planner: SparkPlanner = -
new SparkPlanner(sparkContext, conf, experimentalMethods.extraStrategies)
plan真正的处理函数如下的code 13所示。该函数的功能是整合所有的Strategy,_(plan)每个Strategy应用plan上,得到所有Strategies执行完后生成的所有Physical Plan的集合。
-
code 13 -
def plan(plan: LogicalPlan): Iterator[PhysicalPlan] = { -
// Obviously a lot to do here still... -
// Collect physical plan candidates. -
val candidates = strategies.iterator.flatMap(_(plan)) -
// The candidates may contain placeholders marked as [[planLater]], -
// so try to replace them by their child plans. -
val plans = candidates.flatMap { candidate => -
val placeholders = collectPlaceholders(candidate) -
if (placeholders.isEmpty) { -
// Take the candidate as is because it does not contain placeholders. -
Iterator(candidate) -
} else { -
// Plan the logical plan marked as [[planLater]] and replace the placeholders. -
placeholders.iterator.foldLeft(Iterator(candidate)) { -
case (candidatesWithPlaceholders, (placeholder, logicalPlan)) => -
// Plan the logical plan for the placeholder. -
val childPlans = this.plan(logicalPlan) -
candidatesWithPlaceholders.flatMap { candidateWithPlaceholders => -
childPlans.map { childPlan => -
// Replace the placeholder by the child plan -
candidateWithPlaceholders.transformUp { -
case p if p == placeholder => childPlan -
} -
} -
} -
} -
}
3. spark2.x较spark1.x性能
对源码的分析后,可以看出spark 2.0较 spark 1.x版本性能有较大提升,具体可从以下几个方面看出:
1.parser语法解析不同
spark 1.x版本使用的是scala的parser语法解析器,而spark 2.x版本使用的是ANTLR4,解析性能更好
2.spark 2.x的optimizer优化策略不同
spark 2.x为optimizer优化器提供了更加丰富的优化策略,从两个版本里optimizer类中的batchs中可以看出。
3.spark 2.x提供了第二代Tungsten引擎
Spark2.x移植了第二代Tungsten引擎,这一代引擎是建立在现代编译器和MPP数据库的基础上,并且应用到数据的处理中。主要的思想是将那些拖慢整个程序执行速度的代码放到一个单独的函数中,消除虚拟函数的调用,并使用寄存器来存放中间结果。这项技术被称作“whole-stage code generation.”
下面通过在单机上执行10亿条数据的aggregations and joins操作,来对比spark1.6和2.0的性能。其中,ns为纳秒,表格中的处理时间为单个线程处理单行数据所用时间。由此,可看出spark2.0的处理性能远远好于1.6。
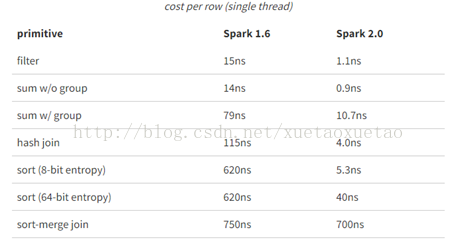
图5 spark性能对比
声明:
1.由于本人也是初次学习sql的源码,有什么理解错误,或者讲解不到位的地方请大家帮忙指出,以求大家一起进步。
2.性能对比第三点观点及图来自于一下链接:
https://databricks.com/blog/2016/05/11/apache-spark-2-0-technical-preview-easier-faster-and-smarter.html