YOLOV1目标检测代码逻辑讲解
1、标注xml数据转txt文件
数据标注完,会生成对应的数据格式,这里我就以VOC数据集的xml格式为例,通常需要解析xml转txt文件,便于我们后面对img和label信息进行读取。
下图就是xml文件格式了:
<annotation>
<folder>blcak</folder>
<filename>img000001.jpg</filename>
<source>
<database>Unknown</database>
</source>
<size>
<width>1024</width>
<height>1024</height>
<depth>1</depth>
</size>
<segmented>0</segmented>
<object>
<name>black_core</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>47</xmin>
<ymin>69</ymin>
<xmax>961</xmax>
<ymax>967</ymax>
</bndbox>
</object>
</annotation>
其中 annotation是第0阶段的字段;folder、filename、source、size、segmented、object是第1阶段的字段,通常object还会有下一阶段的字段。
1.1使用.tag获取字段
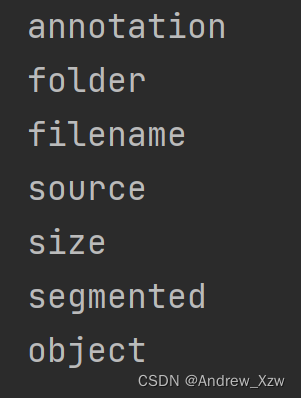
下面输出 第0阶段的字段,root.tag输出annotation。
import xml.etree.ElementTree as ET
tree = ET.parse('D:\\YOLOv1\\data\\trainval\\Annotations\\img000001.xml')
root = tree.getroot() #获取
print(root.tag) #输出annotation
遍历root,输出第1阶段的所有字段。
for i in root:
print(i.tag) #输出root下第1阶段的所有字段
1.2使用.text获取字段的值。
其实字段比较清晰,这里说一下字段的值是相对复杂的。
for i in root:
print(i.text) #输出root下第1阶段的所有字段的值
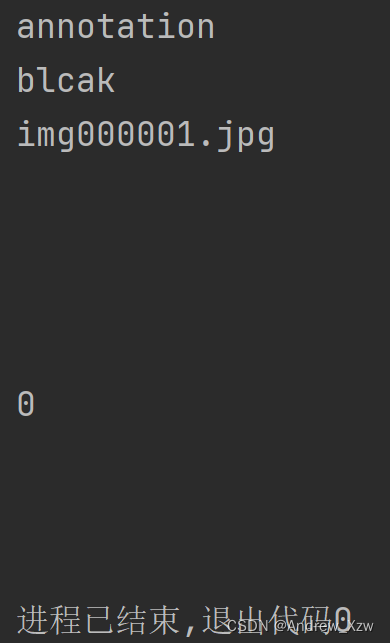
可以看一下为什么输出会产生很多"\n"换行呢???
.text表示当前字段的尖括号和下一个尖括号之间的部分,比如上面代码遍历的i,当i=folder时,i.text为<folder>与</folder>之间的部分也就是blcak;
但是!如果i遍历到source时,<source>与下一个字段<database>的中间部分是换行啊!所以这里i.text输出换行!<ymin>
1.3获得xml文件里object部分
//其实一个阶段再往下一阶段慢慢访问,理解了也不是很难!
在目标检测中,object部分的坐标、中心点相关信息是比较重要的。下面的代码中:
这里遍历tree.findall('object'),因为一幅图中可能不止一个目标,每一次遍历,obj就相当于一个目标框。
那么,既然obj就相当于相当于一个阶段了,继续往下一个阶段获得标注信息:
obj.find('name').text就是获得<object>下一个阶段<name>字段的值:black_core。
因为坐标信息是在<bndbox>这一阶段的下一阶段,需要先通过obj.find('bndbox')访问<obj>的下一阶段<bndbox>,再通过bbox.find('ymin').text)访问<bndbox>下一阶段<ymin>这一阶段对应的值。
objects = []
for obj in tree.findall('object'):
obj_struct = {
}
difficult = int(obj.find('difficult').text)
if difficult == 1: # 若为1则跳过本次循环
continue
obj_struct['name'] = obj.find('name').text
bbox = obj.find('bndbox')
obj_struct['bbox'] = [int(float(bbox.find('xmin').text)),
int(float(bbox.find('ymin').text)),
int(float(bbox.find('xmax').text)),
int(float(bbox.find('ymax').text))]
objects.append(obj_struct)
1.4保存为txt文件
//这里其实都差不多,就讲一下训练部分的txt文件
train_set = open('pveltrain.txt', 'w')
Annotations = 'D://YOLOv1/data/trainval/Annotations/'
xml_files = os.listdir(Annotations) #获取Annotations文件下所有每个标注文件的名字,list[img000001.xml, ....]
random.shuffle(xml_files) # 打乱数据集
train_num = int(len(xml_files) * 0.7) # 总数居的0.7为训练集数量
train_lists = xml_files[:train_num] # 训练列表
test_lists = xml_files[train_num:] # 测测试列表
def write_txt():
count = 0
for train_list in train_lists: # 遍历每一个xml文件
count += 1
image_name = train_list.split('.')[0] + '.jpg' # 图片文件名
results = parse_rec(Annotations + train_list) #这里就是上面讲的解析xml获取字段及字段的值部分, 返回是一个字典文件dict{
"name":name, "bbox":[xmin, ymin, xmax, ymax]}
if len(results) == 0:
print(train_list)
continue
train_set.write(image_name) #首先就是将图片名称存入txt文件
for result in results:
class_name = result['name']
bbox = result['bbox']
class_name = VOC_CLASSES.index(class_name) #获取对应的我们设置好的对应类别的索引
train_set.write(' ' + str(bbox[0]) +
' ' + str(bbox[1]) +
' ' + str(bbox[2]) +
' ' + str(bbox[3]) +
' ' + str(class_name))
train_set.write('\n')
#最后每遍历一次,每一行代表一幅图上的标注信息
train_set.close()
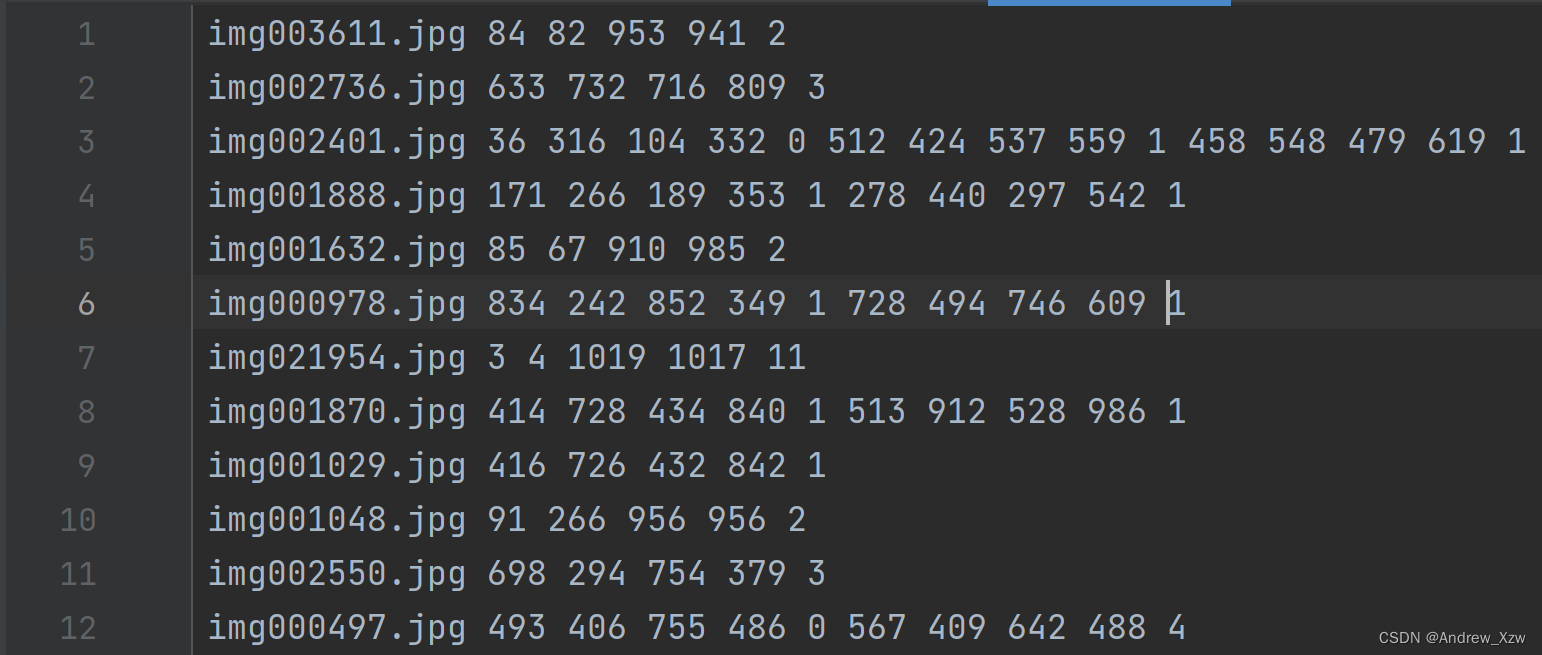

2、生成Dataset
2.1框架逻辑
通常生成Dataset主要就是3个关键魔法方法 __init__、__getitem__和__len__。
__init__主要就是读取每个img和label对应的路径,以及预处理方式(totensor等等…)
__len__就是返回img的数量。
这个方法在自己创建自己的数据集类并继承Dataset时候会被调用。
而!__getitem__和__len__是将Dataset送进DataLoader时,遍历DataLoader时调用。
for i, data in enumerate(train_loader):
img, target = data
先是__len__是返回整个Dataset中的img数量。
根据自己设置的batch_size,比如:20,__getitem__就会按照[0-19]的索引依次读入这个batch的所有img和label:
等到indx遍历到19结束后,这里返回的img:[20,3,448,448],target:[20,22,7,7]
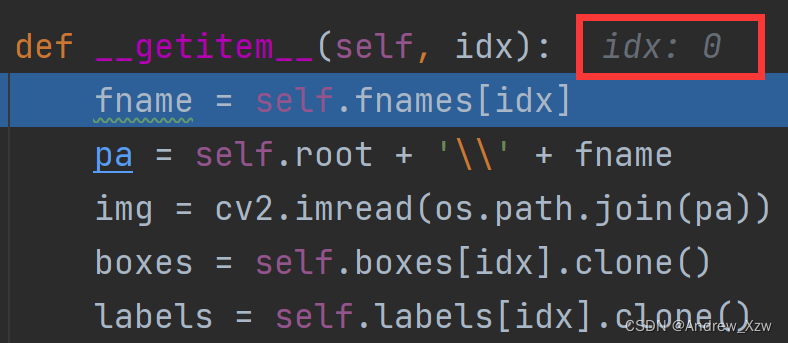
比如这里的fname = self.fnames[idx]就是读取第idx的图片名称。
2.2读取txt文件中bbox信息
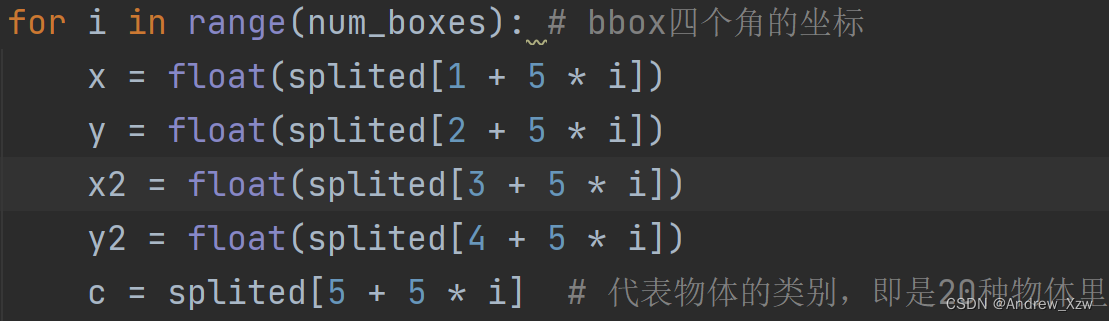
这里讲一下为啥主题代码中,存放bbox信息是这样的,以左上角的x坐标为例,txt文件其实存放位置是这样的,那如果一幅图片中如果多个目标,当i=1时,1 + 5 *1就是第6个索引,刚好对应的第二个bbox的x坐标!

2.3“encoder”部分!!
这一部分也是我认为预处理部分最为重要,最难懂的部分!
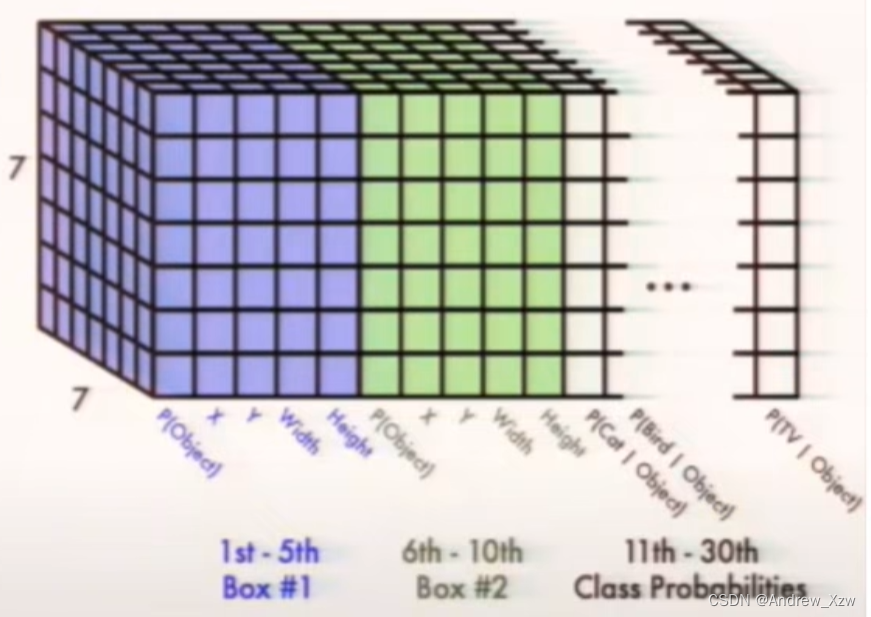
YOLOV1中是将图片划分成7X7的grid cell,那么我们肯定要将将我们的bbox信息处理成7X7X类别的形式!
这里就是先创建全0的7X7X类别的tensor,然后将我们的所有bbox信息读取并赋值。
def encoder(self, boxes, labels): # 输入的box为归一化形式(X1,Y1,X2,Y2) , 输出ground truth (7*7)
grid_num = 7
target = torch.zeros((grid_num, grid_num, int(CLASS_NUM + 10))) # 7*7*30
cell_size = 1. / grid_num # 1/7
wh = boxes[:, 2:] - boxes[:, :2] # wh = [w, h] #就是拿x2,y2 - x1, y1
# 物体中心坐标集合
cxcy = (boxes[:, 2:] + boxes[:, :2]) / 2 # 求出每个bbox的中心坐标
for i in range(cxcy.size()[0]):#遍历每个中心点
cxcy_sample = cxcy[i] # 中心坐标 1*1
ij = (cxcy_sample / cell_size).ceil() - 1 # 左上角坐标 (7*7)为整数
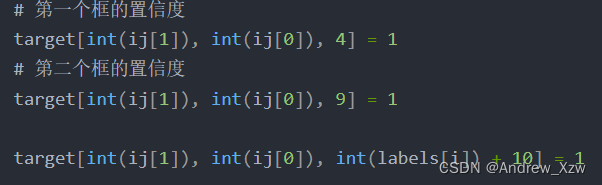
# 第一个框的置信度
target[int(ij[1]), int(ij[0]), 4] = 1
# 第二个框的置信度
target[int(ij[1]), int(ij[0]), 9] = 1
target[int(ij[1]), int(ij[0]), int(labels[i]) + 10] = 1 # 20个类别对应处的概率设置为1
xy = ij * cell_size # 归一化左上坐标 (1*1)
delta_xy = (cxcy_sample - xy) / cell_size # 中心与左上坐标差值 (7*7)
# 坐标w,h代表了预测的bounding box的width、height相对于整幅图像width,height的比例
target[int(ij[1]), int(ij[0]), 2:4] = wh[i] # w1,h1
target[int(ij[1]), int(ij[0]), :2] = delta_xy # x1,y1
# 每一个网格有两个边框
target[int(ij[1]), int(ij[0]), 7:9] = wh[i] # w2,h2
# 由此可得其实返回的中心坐标其实是相对左上角顶点的偏移,因此在进行预测的时候还需要进行解码
target[int(ij[1]), int(ij[0]), 5:7] = delta_xy # [5,7) 表示x2,y2
return target
这里的难懂的点主要就是将我们的所有bbox信息读取并赋值给全0的7X7X类别的tensor。
至于这里为什么这么做:
先讲一讲空间维度,为什么这里的bbox对应的空间维度是[int(ij[1]), int(ij[0]],因为,这里的cxcy_sample相当于第一个bbox的坐标信息,这个是已经相当于在原图,如(1000, 800)的图像上归一化的坐标,而我们要将在原图的对应的位置关系转变成现在的7x7的位置上,所以这里×cell_size分支1,也就是7。再通过.ceil()向下整除,-1就是左上角的坐标。

再来讲一讲通道维度,我们首先来看一幅图,这里的通道维度就是我们的x,w,w,h,c信息,因为是真是标签,要将对应类别的置信度和类别概率为1,所以对应下面的图,代码就是通道维的第4和第9个索引为置信度。后面的类别概率,因为前面有10个坐标信息了,10 + 类别索引就是对应下图立方体中我们的bbox对应的类别。
所以有了两个维度的信息,就可以进行赋值了。
主题代码:
class yoloDataset(Dataset):
image_size = 448 # 输入图片大小
def __init__(self, img_root, list_file, train, transform): # list_file为txt文件 img_root为图片路径
self.root = img_root
self.train = train
self.transform = transform
# 后续要提取txt文件信息,分类后装入以下三个列表
self.fnames = []
self.boxes = []
self.labels = []
self.S = 7 # YOLOV1
self.B = 2 # 相关
self.C = CLASS_NUM # 参数
self.mean = (83, 83, 83) # RGB
file_txt = open(list_file)
lines = file_txt.readlines() # 读取txt文件每一行
for line in lines: # 逐行开始操作
splited = line.strip().split() # 移除首位的换行符号再生成一张列表
self.fnames.append(splited[0]) # 存储图片的名字
num_boxes = (len(splited) - 1) // 5 # 每一幅图片里面有多少个bbox
box = []
label = []
#下面的主要是存放每个bbox 的左上、右下坐标,以及是置信度。
for i in range(num_boxes): # bbox四个角的坐标
x = float(splited[1 + 5 * i])
y = float(splited[2 + 5 * i])
x2 = float(splited[3 + 5 * i])
y2 = float(splited[4 + 5 * i])
c = splited[5 + 5 * i] # 代表物体的类别,即是20种物体里面的哪一种 值域 0-19
box.append([x, y, x2, y2])
label.append(int(c))
self.boxes.append(torch.Tensor(box))
self.labels.append(torch.LongTensor(label))
self.num_samples = len(self.boxes)
def __getitem__(self, idx):
fname = self.fnames[idx]
pa = self.root + '\\' + fname
img = cv2.imread(os.path.join(pa))
boxes = self.boxes[idx].clone()
labels = self.labels[idx].clone()
if self.train: # 数据增强里面的各种变换用torch自带的transform是做不到的,因为对图片进行旋转、随即裁剪等会造成bbox的坐标也会发生变化,所以需要自己来定义数据增强
#print('------kk------',img)
img = self.cvtColor(img)
img, boxes = self.random_flip(img, boxes)
img, boxes = self.randomScale(img, boxes)
img = self.randomBlur(img)
img = self.RandomBrightness(img)
# img = self.RandomHue(img)
# img = self.RandomSaturation(img)
img, boxes, labels = self.randomShift(img, boxes, labels)
# img, boxes, labels = self.randomCrop(img, boxes, labels)
h, w, _ = img.shape
boxes /= torch.Tensor([w, h, w, h]).expand_as(boxes) # 坐标归一化处理,为了方便训练
img = self.BGR2RGB(img) # because pytorch pretrained model use RGB
img = self.subMean(img, self.mean) # 减去均值
img = cv2.resize(img, (self.image_size, self.image_size)) # 将所有图片都resize到指定大小
target = self.encoder(boxes, labels) # 将图片标签编码到7x7*30的向量
for t in self.transform:
img = t(img)
return img, target
def __len__(self):
return self.num_samples
# def letterbox_image(self, image, size):
# # 对图片进行resize,使图片不失真。在空缺的地方进行padding
# iw, ih = image.size
# scale = min(size / iw, size / ih)
# nw = int(iw * scale)
# nh = int(ih * scale)
#
# image = image.resize((nw, nh), Image.BICUBIC)
# new_image = Image.new('RGB', size, (128, 128, 128))
# new_image.paste(image, ((size - nw) // 2, (size - nh) // 2))
# return new_image
def encoder(self, boxes, labels): # 输入的box为归一化形式(X1,Y1,X2,Y2) , 输出ground truth (7*7)
grid_num = 7
target = torch.zeros((grid_num, grid_num, int(CLASS_NUM + 10))) # 7*7*30
cell_size = 1. / grid_num # 1/7
wh = boxes[:, 2:] - boxes[:, :2] # wh = [w, h] 1*1
2.4数据增强
在训练过程中,为了使我们的模型拟合能力更强,我们会通过颜色空间变换、水平翻转、随即裁剪等进行数据增强,逼迫模型学更多的特征。
而!用Pytorch框架自带的transform中各种数据增强的变换是不行的,因为对图片进行旋转、随即裁剪等会造成bbox的坐标也会发生变化,所以需要自己来定义数据增强。
如这里的随即反转,其实核心就是在于进行图像变换后,bbox的坐标信息需要进行相应的变换即可。
def random_flip(self, im, boxes):
if random.random() < 0.5:
im_lr = np.fliplr(im).copy()
h, w, _ = im.shape
xmin = w - boxes[:, 2]
xmax = w - boxes[:, 0]
boxes[:, 0] = xmin
boxes[:, 2] = xmax
return im_lr, boxes
return im, boxes