环境:Ubuntu18.04 GTX1080
文章目录
0 准备
0.1 配置OpenCV环境
sudo apt update
sudo apt install libopencv-dev
whereis opencv # 查看是否安装成功

0.2 配置CUDA环境
参考 cuda环境配置详细笔记
0.3 安装git
sudo apt update
sudo apt install git
1 示例Demo测试
1.1 下载Darknet
git clone https://github.com/pjreddie/darknet.git
1.2 修改Makfile
cd darknet
vim Makefile
贴出本文修改后的Makefile前面部分(其余部分不需要修改)。GPU=1,CUDNN=1,OPENCV=1表示使用GPU,使用CUDNN,使用OPENCV,下面的ARCH需要根据自己的GPU版本来做权衡,GTX1060和GTX1080按照本文的配置即可。

1.3 编译
make -j32
1.4 下载pre-trained model
cd darknet
wget https://pjreddie.com/media/files/yolov3.weights
1.5 修改网络配置文件
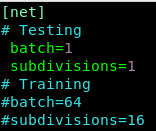
修改darknet/cfg/yolov3.cfg,注释掉Training参数,取消注释Testing参数。
1.6 图像检测
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
如果出现这个问题,查看段错误,核心已存储 两种解决办法。



1.7 Webcam检测
实时摄像头检测。
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights
1.8 Video检测
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights <video file>
2 制作YOLO数据集
现在可以从两种数据集格式快速生成YOLO数据集进行训练,分别是VOC数据集格式和MSCOCO数据集格式。
2.1 从VOC制作YOLO数据集
voc数据集可以从voc官网上直接下载得到,但这里是为了训练自己的数据集检测自己的类别,所以还是DIY VOC数据集先。
2.1.1 制作VOC数据集
2.1.2 VOC数据格式转YOLO数据格式
假定已经按照2.1.1中的步骤做好了VOC2007格式的数据集,那么可以复制下面的脚本到voc2yolo.py中,并把它同VOCdevkit放在同一目录下,运行脚本python voc2yolo.py,YOLO数据集便生成好了。
import xml.etree.ElementTree as ET
import os
from os import listdir, getcwd
# ==================可能需要修改的地方=====================================#
g_root_path = "D:/deep_learning/new_datas" # VOCdevkit目录
classes = ["gun"] # 类别
# ==========================================================================#
os.chdir(g_root_path)
sets = [('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml' % (year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt' % (year, image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/' % (year)):
os.makedirs('VOCdevkit/VOC%s/labels/' % (year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt' % (year, image_set)).read().strip().split()
list_file = open('%s_%s.txt' % (year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n' % (wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()



2.2 从MSCOCO制作YOLO数据集
【待完善】
现在环境和数据集都已经准备好了,万事俱备只欠东风,可以进行简单的配置,然后训练了。
【未完待续…】
下一篇 【笔记】YOLOv3训练自己的数据集(2)——训练和测试训练效果