imdb数据集介绍
IMDB影评数据集中含有来自IMDB的25,000条影评,被标记为正面/负面两种评价。影评已被预处理为词下标构成的序列。方便起见,单词的下标基于它在数据集中出现的频率标定,例如整数3所编码的词为数据集中第3常出现的词。这样的组织方法使得用户可以快速完成诸如“只考虑最常出现的10,000个词,但不考虑最常出现的20个词”这样的操作
按照惯例,0不代表任何特定的词,而用来编码任何未知单词
keras中内置了imdb数据集,我们直接导入即可(第一次导入会自动下载)。
导入数据
from keras.datasets import imdb
#只考虑出现频率最高的10000个单词,其余低频率单词会被编码为0
max_word = 10000
(train_x, train_y), (test_x, test_y) = imdb.load_data(num_words=max_word)
观察数据
print(train_y)
print(len(train_y))
print(train_y.sum())
print(test_y)
print(len(test_y))
print(test_y.sum())
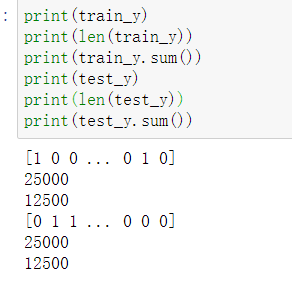
数据已经被分为训练集和测试集,均有25000条数据,其中正面评价已被编码为1,负面编码为0,且两者在数据集中的频率相同。
再来看训练数据
print(train_x)

单词已被编码为整数序列,且不同评论编码的序列长度不同,由于神经网络的输入需要特征数相同,所以我们需要对数据进行填充或切割。
解码数据
这里提供给大家一个函数,用于将整数序列解码为英文。
def decode_word(word):
word_index = imdb.get_word_index()
reverse_word_index = dict([(value,key) for (key, value) in word_index.items()])
decode_review = ' '.join([reverse_word_index.get(i - 3,"?") for i in word])
return decode_review
我们尝试解码第一条测试数据
print(decode_word([1, 591, 202, 14, 31, 6, 717, 10, 10, 2, 2, 5, 4, 360, 7, 4, 177, 5760, 394, 354, 4, 123, 9, 1035, 1035, 1035, 10, 10, 13, 92, 124, 89, 488, 7944, 100, 28, 1668, 14, 31, 23, 27, 7479, 29, 220, 468, 8, 124, 14, 286, 170, 8, 157, 46, 5, 27, 239, 16, 179, 2, 38, 32, 25, 7944, 451, 202, 14, 6, 717]))

处理数据
from keras.preprocessing.sequence import pad_sequences
maxlen = 500
train_x = pad_sequences(train_x,maxlen=maxlen)
test_x = pad_sequences(test_x,maxlen=maxlen)
用keras中的pad_sequences方法对数据进行填充或切割,使数据序列长度的恒为500,长度不足的填充0,长度大于500的被截断。
定义回调函数
keras会在每一轮训练后调用回调函数
from keras.callbacks import EarlyStopping,ModelCheckpoint
callbacks_list = [
EarlyStopping(
monitor = 'val_accuracy', #监控验证精度
patience = 3, #如果验证精度多于三轮不改善则中断训练
),
#在训练的过程中不断得保存最优的模型
ModelCheckpoint(
filepath = 'my_model_conv1d.h5', #模型保存路径
monitor = 'val_accuracy', #监控验证精度
save_best_only = True, #如果val_accuracy没有改善则不需要覆盖模型
)
]
Embedding层
嵌入层将正整数(下标)转换为具有固定大小的向量,如[[4],[20]]->[[0.25,0.1],[0.6,-0.2]]
Embedding层只能作为模型的第一层
第一个参数input_dim:大或等于0的整数,字典长度,即输入数据最大下标+1
第二个参数output_dim:大于0的整数,代表全连接嵌入的维度
Conv1D和MaxPooling1D层
由于我们的模型需要用到Conv1D和MaxPooling1D层,我先在这里用一个小的案例来给大家讲解
from keras import layers
from keras import Sequential
import numpy as np
model_test = Sequential()
model_test.add(layers.Conv1D(4,3,input_shape=(9,3)))
model_test.add(keras.layers.MaxPool1D(pool_size=2,padding='same'))
model_test.add(layers.GlobalMaxPool1D())
model_test.compile(loss='mse',optimizer='sgd')
查看模型结构
model_test.summary()
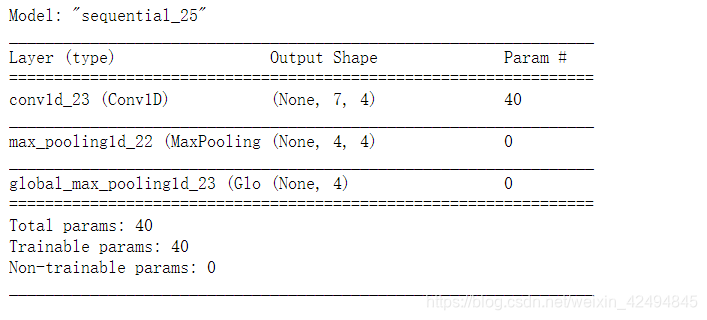
首先输入的向量为9行三列,由于我们设置了4个一维卷积核,所以输出的列数为4,卷积核大小为3,每个卷积核做的运算如下:
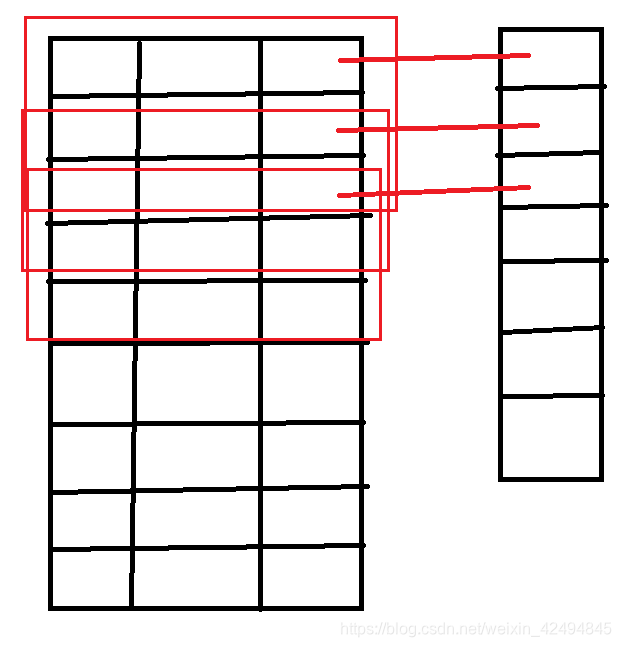
将挨着的三行和卷积核中的参数进行矩阵运算得到一个结果,然后卷积核向下移动一行,再将挨着的三行运算后得到一个结果,直到达到末尾。总共运算了七次,于是得到七行一列,因为有四个卷积核,所以最终为七行四列。
而MaxPool1D层我们指定了pool_size=2,他只保留每两行中每一列最大的数,然后向下移动两行。由于指定了padding=‘same’,在移动到只有一行时它就会全部保留这一行的数。
而GlobalMaxPool1D只保留所有行中每一列最大的数。
我们通过获取每一行的输出来帮助我们理解。
下面这些代码会打印出每一行输出的结果:
from keras import backend as K
inp = model_test.input
outputs = [layer.output for layer in model_test.layers]
functor = K.function([inp, K.learning_phase()], outputs )
input_shape = (9,3)
test = np.random.random(input_shape)
test = np.expand_dims(test,axis=0)
layer_outs = functor([test,1])
for i,j in enumerate(layer_outs):
print(f"第{i+1}层输出为:")
print(j)
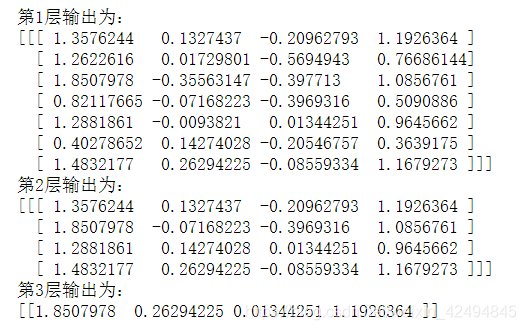
可以很直观的看到三层的效果。
解释了这么多下面我们就来定义模型了。
定义模型
from keras.layers import Embedding
from keras.layers import Conv1D
from keras.layers import MaxPooling1D
from keras.layers import GlobalMaxPooling1D
from keras.layers import Dense
from keras.losses import BinaryCrossentropy
from keras.models import Sequential
model = Sequential([
Embedding(max_word,128,input_length=maxlen),
Conv1D(32,7,activation="relu"),
MaxPooling1D(5),
Conv1D(32,7,activation="relu"),
GlobalMaxPooling1D(),
Dense(1,activation="sigmoid")
])
model.compile(optimizer="rmsprop",loss=BinaryCrossentropy(),metrics=["accuracy"])
训练模型
history = model.fit(train_x,train_y,epochs=10,batch_size = 128,validation_data=(test_x, test_y),callbacks=callbacks_list)
训练结果如下
Train on 25000 samples, validate on 25000 samples
Epoch 1/10
25000/25000 [==============================] - 143s 6ms/step - loss: 0.2687 - accuracy: 0.8895 - val_loss: 0.3584 - val_accuracy: 0.8468
Epoch 2/10
25000/25000 [==============================] - 140s 6ms/step - loss: 0.2023 - accuracy: 0.9210 - val_loss: 0.3358 - val_accuracy: 0.8592
Epoch 3/10
25000/25000 [==============================] - 140s 6ms/step - loss: 0.1527 - accuracy: 0.9448 - val_loss: 0.3889 - val_accuracy: 0.8497
Epoch 4/10
25000/25000 [==============================] - 141s 6ms/step - loss: 0.1109 - accuracy: 0.9623 - val_loss: 0.3913 - val_accuracy: 0.8516
Epoch 5/10
25000/25000 [==============================] - 139s 6ms/step - loss: 0.0703 - accuracy: 0.9791 - val_loss: 0.4550 - val_accuracy: 0.8448
可以看到在第五轮训练完成后训练就提前结束了,因为三轮验证精度都没有改善,同时训练过程中最好的模型已经被保存了。
今天的分享就到这里了,希望大家能够有所收获。
PS:博主有时间还会分享出用LSTM模型进行训练还有比较其和一维卷积模型的预测效果,同时讲解两者的区别。
写文不易,只希望能得到大家的认可~