分类目录:《深入理解深度学习》总目录
相关文章:
· BERT(Bidirectional Encoder Representations from Transformers):基础知识
· BERT(Bidirectional Encoder Representations from Transformers):BERT的结构
· BERT(Bidirectional Encoder Representations from Transformers):MLM(Masked Language Model)
· BERT(Bidirectional Encoder Representations from Transformers):NSP(Next Sentence Prediction)任务
· BERT(Bidirectional Encoder Representations from Transformers):输入表示
· BERT(Bidirectional Encoder Representations from Transformers):微调训练-[句对分类]
· BERT(Bidirectional Encoder Representations from Transformers):微调训练-[单句分类]
· BERT(Bidirectional Encoder Representations from Transformers):微调训练-[文本问答]
· BERT(Bidirectional Encoder Representations from Transformers):微调训练-[单句标注]
· BERT(Bidirectional Encoder Representations from Transformers):模型总结与注意事项
BERT在预训练阶段使用了《深入理解深度学习——BERT(Bidirectional Encoder Representations from Transform):MLM(Masked Language Model)》和《深入理解深度学习——BERT(Bidirectional Encoder Representations from Transform):NSP(Next Sentence Prediction)任务》所述的两种训练方法,在真实训练的过程中,两种方法是混合在一起使用的。《深入理解深度学习——注意力机制(Attention Mechanism):自注意力(Self-attention)》中介绍的Self-attention不会考虑词的位置信息,因此Transformer需要两套Embedding操作,一套为One-hot词表映射编码(下图中标注为Token Embeddings),另一套为位置编码(下图中标注为Position Embeddings)。同时,在MLM的训练过程中,存在单句输入和双句输入的情况,因此BERT还需要一套区分输入语句的分割编码(下图中标注为Segment Embeddings)。BERT的Embedding过程包含三套Embedding操作,如下图所示。
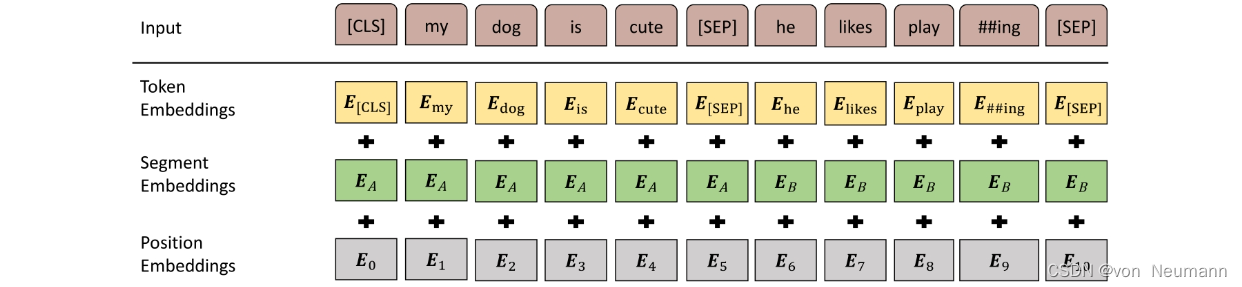
以下图中的样例数据作为原始输入,可以通过以下5步得到最终的BERT输入表示。
- 获得原始输入句对“my dog is cute”和“he likes playing”。
- 对输入句子使用WordPiece分词,变成“my dog is cute”和“he likes play##ing”。
- 将句对拼接并加上用于分类的特殊标签符和分隔符,得到“[CLS]my dog is cute[SEP]he likes play##ing[SEP]”。
- 计算每一个词的Position Embeddings、Segment Embeddings和Token Embeddings,如上图中灰色、绿色和黄色区域所示。
- 将三个Embeddings表示相加,得到最终的BERT输入表示。
值得注意的是,Transformer使用的位置编码一般为三角函数,而BERT使用的位置编码和分割编码均在预训练过程中训练得到,其表示位置信息的能力更强。
参考文献:
[1] Lecun Y, Bengio Y, Hinton G. Deep learning[J]. Nature, 2015
[2] Aston Zhang, Zack C. Lipton, Mu Li, Alex J. Smola. Dive Into Deep Learning[J]. arXiv preprint arXiv:2106.11342, 2021.
[3] 车万翔, 崔一鸣, 郭江. 自然语言处理:基于预训练模型的方法[M]. 电子工业出版社, 2021.
[4] 邵浩, 刘一烽. 预训练语言模型[M]. 电子工业出版社, 2021.
[5] 何晗. 自然语言处理入门[M]. 人民邮电出版社, 2019
[6] Sudharsan Ravichandiran. BERT基础教程:Transformer大模型实战[M]. 人民邮电出版社, 2023
[7] 吴茂贵, 王红星. 深入浅出Embedding:原理解析与应用实战[M]. 机械工业出版社, 2021.