版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u014665013/article/details/85037671
本文是在transformer(attention is all you need)的基础上的,可参考博主之前博客:paper:Attention Is All You Need
之前已经有很多blog介绍了,这里引用一下,剩下的主要记录下自己的认识和体会
模型分析:
模型代码解读:
关于BERT其他相关资料:
paper 作者的一些issue
questions:
- Why 15% is masked rather all of the word like word2wec?
- when fintune,why get_pooled_output layer just use the first tokens’ output?
tricks:
- initilizer:
tf.truncated_normal_initializer(stddev=initializer_range) - embedding size 一般设置成了hidden_size
- loss = loss+1e-5
不同:
- self attention之后添加projection ,也就是transformer:multi head attention + add&norm + ffn layer + add&norm,而在bert中变成了:multi head attention + projection layer + add&norm + ffn layer + add&norm
- layer norm的结构稍有变化
- ffn layer中的激活函数改为gelu
model整体流程图:
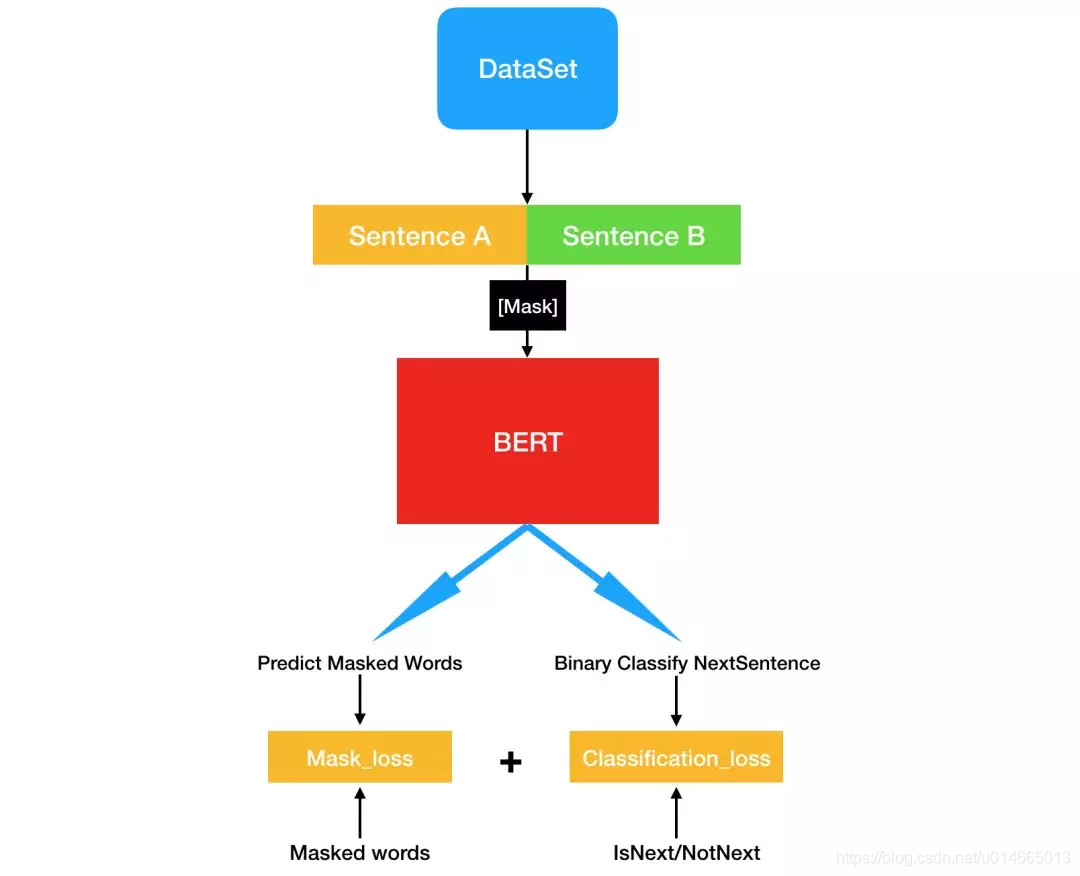
详细流程:
- word_embedding+sentense_mask_embedding+position_embedding
- layer_norm_and_dropout
- get mask attention
- multi head self attention
- Q、K、V dense layer
- self attention = 中间包括:self attention + mask attention和dropout
- projection + dropout
- layer norm+residual
- ffn layer :intermediate (dense layer(激活函数gelu))+output(dense layer)+dropout
- layer norm+residual 这里得到
sequence output
- 取sequence output中每个case的第一个输出向量(CLS对应的向量),并经过dense layer(激活函数为tanh),得到
pooled_output - 从
sequence output中取出mask的位置的vector,过dense layer,激活函数为gelu,并对结果进行layer_norm,得到结果mask output - matmul(
mask output,embedding table)+bias,后交叉熵损失函数mask_loss - 对
pooled_output过dense layer,然后交叉熵函数得到sequence_loss - 最终的loss=
mask_loss+sequence_loss