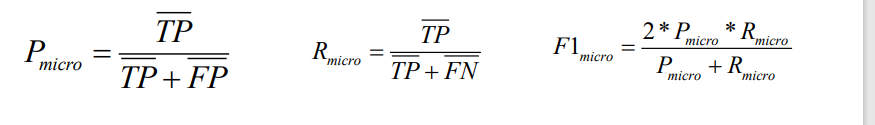文章目录
一、基本概念
真正例/真阳例(TP):预测正确的正例
真负例/真阴例(TF):预测正确的负例
假正例/假阳例(FT):错误得预测为正例,实际为负例
假负例/假阴例(FP):错误得预测为负例,实际为正例
二、混淆矩阵
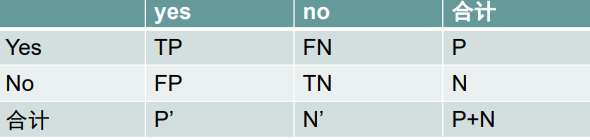
其中第一行可以看成实际为正,第二行看成实际为假,
第一列看成预测为正,第二列看出预测为假。
准确率,识别率:(TP + TN)/(TP + FN + FP + TN)
错误率:(FP + FN)/(TP + FN + FP + TN)
召回率(实际正例中,预测为正例的比例):TP / (TP + FN)
精确率(预测为正例当中,实际正例得比例):TP / (TP + FP)
F分数:(2 * recall * precision)/(precision + recall)
三、多分类模型评价指标
Macro Average(宏平均):
所以类别的每一个统计指标值的算术平均值,例如宏精确率,宏召回率,宏F值。
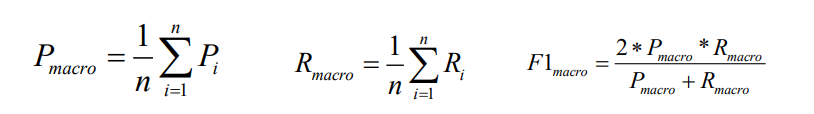
Micro Average(微平均)
将所有类别的TP,FP,TN,FN分别合起来,建立全局混淆矩阵,对应的微精确率,微召回率,微F值。