摘要
现有的神经序列生成模型,要么是从头开始逐步生成字符,要么(迭代地)修改以固定长度为边界的字符序列。在这项工作中,我们提出了Levenshtein Transformer,这是一种新的部分自回归模型,旨在更灵活,更顺畅地生成序列。与以前的方法不同,我们模型的基本操作是insertion和deletion。它们的组合不仅有利于生成,而且有利于优化长度动态变化的序列。我们还提出了一套专门针对它们的新训练技术,由于它们的互补性,可以有效地利用一种作为另一种学习信号。提出的模型在生成(例如机器翻译,文本摘要)和优化任务(例如自动后编辑)方面都达到了相当甚至更好的性能,并且效率大大提高。通过展示经过机器翻译训练的Levenshtein Transformer可以直接用于自动后期编辑,我们进一步证实了模型的灵活性。
1.介绍
神经序列生成模型已经广泛开发并部署在诸如机器翻译之类的任务中。与会逐步生成字符的最流行的自回归模型框架相比,尽管性能略差,但最近的非自回归方法已证明可以在更少的解码迭代次数内执行生成。
在本文中,我们提出了Levenshtein Transformer(LevT),旨在解决当前解码模型缺乏灵活性的问题。值得注意的是,在现有框架中,随着解码的进行,生成的序列的长度是固定的或单调增加的。这仍然与人类的情况不兼容,人类可以修改,替换,撤消或删除其生成的文本的任何部分。因此,LevT被提出通过打破目前的标准化解码机制并将其替换为两个基本操作(insertion和deletion)来弥补这一差距。
我们使用模仿学习训练LevT。结果模型包含两个策略,它们以替代方式执行。从经验上讲,我们显示出LevT在机器翻译和摘要方面达到了比标准Transformer模型可比或更好的结果,同时保持了类似于 (Lee et al., 2018) 的受益于并行解码的效率优势。使用这种模型,我们认为解码变得更加灵活。例如,当给解码器一个空字符时,它会退回到正常的序列生成模型。另一方面,当初始状态是生成的低质量序列时,解码器充当优化模型。实际上,我们证明了通过机器翻译训练的LevT可以直接应用于翻译后编辑,而无需进行任何更改。对于文献中的任何框架,这都是不可能的,因为模型的归纳偏差将生成和完善视为两个不同的任务。
LevT框架中的一个关键组件是学习算法。我们利用insertion and deletion的特征—它们是互补的,但也具有对抗性。我们提出的算法称为“双重策略学习”。这个想法是,当训练一个策略(插入或删除)时,我们将另外一个策略在先前迭代中的输出用作输入。另一方面,绘制了专家策略以提供校正信号。从理论上讲,该学习算法适用于存在双重对抗策略的其他模仿学习场景。在这项工作中,我们主要关注该算法的概念验证,以训练所提出的LevT模型。
为此,我们将贡献总结如下:
- 我们提出了Levenshtein Transformer(LevT),这是一种由insertion和deletion操作组成的新型序列生成模型。在机器翻译和文本摘要方面,该模型可比强大的Transformer基线获得可比甚至更好的结果,但效率要高得多(就实际机器执行时间而言,最高可提高5倍);
- 我们在模仿学习的理论框架下提出了一种相应的学习算法,以解决双重政策的互补性和对抗性;
- 由于其内置的灵活性,我们认为我们的模型是统一序列生成和优化的先驱尝试。通过这种统一,我们凭经验验证了将机器翻译训练的LevT模型直接应用于翻译后编辑的可行性,而无需进行任何更改。
2.问题定义
2.1 序列生成和优化
通过将它们强制转换为由元组 ( Y , A , E , R , y 0 ) (\mathcal Y,\mathcal A,\mathcal E,\mathcal R,\textbf y_0) (Y,A,E,R,y0)定义的马尔可夫决策过程(MDP),可以统一序列生成和优化的一般问题。我们考虑由agent与环境 E \mathcal E E交互组成的设置,环境 E \mathcal E E接收agent的编辑动作并返回修改后的序列。我们将 Y = V N m a x \mathcal Y=\mathcal V^{N_{max}} Y=VNmax定义为一组长度为 N m a x N_{max} Nmax的离散序列,其中 V V V是符号词汇。在每次迭代解码中,agent都会收到从头开始或未完成生成的输入 y \textbf y y,选择动作 a \textbf a a并获得奖赏 r r r。我们用 A \mathcal A A表示动作集合,用 R \mathcal R R表示奖赏函数。通常,奖赏函数 R \mathcal R R测量生成序列与真实序列之间的距离 R ( y ) = − D ( y , y ∗ ) \mathcal R(y)=-\mathcal D(\textbf y,\textbf y^∗) R(y)=−D(y,y∗),该距离可以是任何距离度量,例如Levenshtein距离。将 y 0 ∈ Y \textbf y_0∈\mathcal Y y0∈Y纳入我们的公式至关重要。作为初始序列,当 y 0 \textbf y_0 y0是从另一个系统已经生成的序列时,agent会从本质上学习进行优化,而如果 y 0 \textbf y_0 y0是空序列则会回落到生成。agent通过策略 π π π建模,该策略将当前生成映射到 A A A上的概率分布。即, π : Y → P ( A ) π:\mathcal Y→P(\mathcal A) π:Y→P(A)。
2.2 Actions: Deletion & Insertion
按照上述MDP公式,根据子序列 y k = ( y 1 , y 2 , . . . , y n ) \textbf y^k=(y_1,y_2,...,y_n) yk=(y1,y2,...,yn),环境调用了两个基本操作(deletion和insertion)来生成 y k + 1 = E ( y k , a k + 1 ) y^{k+1}=E(\textbf y^k,\textbf a^{k+1}) yk+1=E(yk,ak+1)。在这里,我们让 y 1 y_1 y1和 y n y_n yn分别为特殊符号 < s > <s> <s>和 < / s > </s> </s>。由于我们主要关注单轮生成的策略,因此在本节中为简单起见省略了上标。对于像MT这样的条件生成,我们的策略还包括源信息 x \textbf x x的输入,此处也将其省略。
(1)Deletion
deletion策略读取输入序列 y \textbf y y,并且对于每个字符 y i ∈ y y_i∈\textbf y yi∈y,删除策略 π d e l ( d ∣ i , y ) π^{del}(d|i,\textbf y) πdel(d∣i,y)做出二分类决策,即1(删除字符)或0(保留字符)。我们另外约束 π d e l ( 0 ∣ 1 , y ) = π d e l ( 0 ∣ n , y ) = 1 π^{del}(0|1,\textbf y)=π^{del}(0|n,\textbf y)=1 πdel(0∣1,y)=πdel(0∣n,y)=1,以避免破坏序列边界。删除分类器也可以看作是GAN中使用的细粒度判别器,在该分类器中,我们为每个预测的字符预测一个“假”或“真实”标签。
(2)Insertion
在这项工作中,构建插入操作要稍微复杂些,因为它涉及两个阶段:占位符预测和字符预测,因此它能够在同一插槽中插入多个字符。首先,在 y \textbf y y中所有可能的插槽 ( y i , y i + 1 ) (y_i,y_{i+1}) (yi,yi+1)中, π p l h ( p ∣ i , y ) π^{plh}(p|i,\textbf y) πplh(p∣i,y)预测添加占位符数目的概率。接下来,对于如上预测的每个占位符,字符预测策略 π t o k ( t ∣ i , y ) π^{tok}(t|i,\textbf y) πtok(t∣i,y)用词汇表中的实际字符替换占位符。两阶段插入过程也可以看作是Insertation Transformer和屏蔽语言模型的混合体。
(3)Policy combination
回想一下,我们的两个操作是相辅相成的。因此,我们以另一种方式将它们组合在一起。例如,在从空开始的序列生成中,首先调用插入策略,然后将其删除,然后重复执行,直到满足特定的停止条件为止。实际上,可以在这种组合中利用并行性。我们实质上将序列生成器的一个迭代分解为三个阶段:(1)删除字符;(2)插入占位符;(3)用新字符替换占位符。在每个阶段内,所有操作都是并行执行的。更准确地说,给定当前序列 y = ( y 0 , . . . , y n ) \textbf y=(y_0,...,y_n) y=(y0,...,yn),并假设要进行预测的动作是 a = { d 0 , . . . , d n ⏟ d ; p 0 , . . . , p n − 1 ⏟ p ; t 0 1 , . . . t 0 p 0 , . . . , t n − 1 p n − 1 ⏟ t } \textbf a =\{\underbrace{d_0,...,d_n}_{\textbf d};\underbrace{p_0,...,p_{n-1}}_{\textbf p};\underbrace{t^1_0,...t^{p_0}_0,...,t^{p_{n-1}}_{n-1}}_{\textbf t}\} a={
d
d0,...,dn;p
p0,...,pn−1;t
t01,...t0p0,...,tn−1pn−1},一次迭代的策略是:
π ( a ∣ y ) = ∏ d i ∈ d π d e l ( d i ∣ i , y ) ⋅ ∏ p i ∈ p π p l h ( p i ∣ i , y ′ ) ⋅ ∏ t i ∈ t π t o k ( t i ∣ i , y ′ ′ ) , (1) \pi(\textbf a|\textbf y)=\prod_{d_i\in\textbf d}\pi^{del}(d_i|i,\textbf y)\cdot \prod_{p_i\in \textbf p}\pi^{plh}(p_i|i,\textbf y')\cdot \prod_{t_i\in\textbf t}\pi^{tok}(t_i|i,\textbf y''),\tag{1} π(a∣y)=di∈d∏πdel(di∣i,y)⋅pi∈p∏πplh(pi∣i,y′)⋅ti∈t∏πtok(ti∣i,y′′),(1)
其中 y ′ = E ( y , d ) \textbf y'=\mathcal E(\textbf y,\textbf d) y′=E(y,d)和 y ′ ′ = E ( y ′ , p ) \textbf y''=\mathcal E(\textbf y',\textbf p) y′′=E(y′,p)。我们在每个子任务中并行化计算。
3.Levenshtein Transformer
在本节中,我们介绍了Levenshtein Transformer的框架和双重策略学习算法。总体而言,我们的模型将字符序列(或空字符)作为输入,然后通过在插入和删除交替进行迭代地修改它,直到两个策略组合在一起为止。我们在附录中描述了详细的学习和推理算法。
3.1 模型

我们使用Transformer作为基本构建块。对于条件生成,源 x \textbf x x包含在每个TransformerBlock中。第l个块的状态为:
h 0 ( l + 1 ) , h 1 ( l + 1 ) , . . . , h n ( l + 1 ) = { E y 0 + P 0 , E y 1 + P 1 , . . . , E y n + P n , l = 0 T r a n s f o r m e r B l o c k l ( h 0 ( l ) , h 1 ( l ) , . . . , h n ( l ) ) , l > 0 (2) \textbf h^{(l+1)}_0,\textbf h^{(l+1)}_1,...,\textbf h^{(l+1)}_n=\begin{cases} E_{y_0}+P_0,E_{y_1}+P_1,...,E_{y_n}+P_n, & l=0\\ TransformerBlock_l(\textbf h^{(l)}_0,\textbf h^{(l)}_1,...,\textbf h^{(l)}_n), & l\gt 0 \end{cases}\tag{2} h0(l+1),h1(l+1),...,hn(l+1)={
Ey0+P0,Ey1+P1,...,Eyn+Pn,TransformerBlockl(h0(l),h1(l),...,hn(l)),l=0l>0(2)
其中 E ∈ R ∣ V ∣ × d m o d e l E∈\mathbb R^{|V|×d_{model}} E∈R∣V∣×dmodel和 P ∈ R N m a x × d m o d e l P∈\mathbb R^{N_{max}×d_{model}} P∈RNmax×dmodel分别是字符和位置嵌入。我们展示了提出的用于修改序列(删除,插入)的LevT模型的示意图,如图1所示。
(1)Policy Classifiers
解码器的输出 ( h 0 , h 2 , . . . , h n ) (\textbf h_0,\textbf h_2,...,\textbf h_n) (h0,h2,...,hn)传递给三个策略分类器:
Deletion Classifier。LevT扫描输入字符(边界除外),并预测每个字符位置是否删除(0)或保留(1),
π θ d e l ( d ∣ i , y ) = s o f t m a x ( h i ⋅ A T ) , i = 1 , . . . n − 1 , (3) \pi^{del}_{\theta}(d|i,\textbf y)=softmax(\textbf h_i\cdot A^T),i=1,...n-1,\tag{3} πθdel(d∣i,y)=softmax(hi⋅AT),i=1,...n−1,(3)
其中 A ∈ R 2 × d m o d e l A∈\mathbb R^{2×d_{model}} A∈R2×dmodel,并且我们总是保留边界字符。
Placeholder Classifier。LevT通过将隐藏表示转换为分类概率分布来预测要在每个连续位置对上插入的字符数量:
π θ p l h ( p ∣ i , y ) = s o f t m a x ( c o n c a t ( h i , h i + 1 ) ⋅ B T ) , i = 0 , . . . n − 1 , (4) \pi^{plh}_{\theta}(p|i,\textbf y)=softmax(concat(\textbf h_i,\textbf h_{i+1})\cdot B^T),i=0,...n-1,\tag{4} πθplh(p∣i,y)=softmax(concat(hi,hi+1)⋅BT),i=0,...n−1,(4)
其中 B ∈ R ( K m a x + 1 ) × ( 2 d m o d e l ) B∈\mathbb R^{(K_{max}+1)×(2d_{model})} B∈R(Kmax+1)×(2dmodel)。根据它预测的字符数量(0到 K m a x K_{max} Kmax),我们在当前位置插入相应的占位符数量。在我们的实现中,占位符由保留在词汇表中的特殊字符 < P L H > <PLH> <PLH>表示。
Token Classifier。按照占位符预测结果,LevT需要填写字符来替换所有占位符。这是通过训练字符预测器来实现的,如下所示:
π θ t o k ( t ∣ i , y ) = s o f t m a x ( h i ⋅ C T ) , ∀ y i = < P L H > , (5) \pi^{tok}_{\theta}(t|i,\textbf y)=softmax(\textbf h_i\cdot C^T),\forall y_i=<PLH>,\tag{5} πθtok(t∣i,y)=softmax(hi⋅CT),∀yi=<PLH>,(5)
其中 C ∈ R ∣ V ∣ × d m o d e l C∈\mathbb R^{|V|×d_{model}} C∈R∣V∣×dmodel是与嵌入矩阵共享的参数。
(2)Weight Sharing
我们的默认实现始终假设这三个操作共享相同的Transformer,以使从其他操作中学到的特征受益。但是,也有可能禁用权重共享并为每个操作训练单独的解码器,这增加了模型的容量,同时不影响整体推理时间。
(3)Early Exit
尽管在上述三个分类器上共享相同的Transformer结构在参数上有效,但是仍有改进的空间,因为一次解码迭代需要网络的三个完整通道。为了在性能和计算成本之间进行权衡,我们提出对 π d e l π^{del} πdel和 π p l h π^{plh} πplh执行early exit(将分类器附加到中间块而不是最后一个块),以减少计算,同时使 π t o k π^{tok} πtok始终基于最后一块,这是因为字符预测通常比其他两个任务更具挑战性。
3.2 3.2 双重策略学习
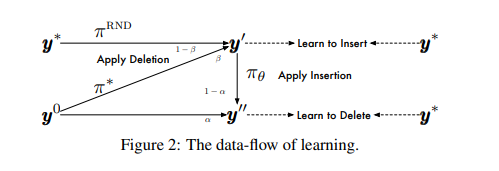
(1)Imitation Learning
我们使用模仿学习来训练Levenshtein Transformer。本质上,我们让agent模仿从某些专家策略 π ∗ π^∗ π∗中得出的动作。专家政策源自直接使用真实目标或通过序列蒸馏过滤后获得的噪声较小的版本。目的是使以下期望最大化:
E y d e l ∼ d π ~ d e l ; d ∗ ∼ π ∗ ∑ d i ∗ ∈ d ∗ l o g π θ d e l ( d i ∗ ∣ i , y d e l ) ⏟ D e l e t i o n O b j e c t i v e + E y i n s ∼ d π ~ i n s ; p ∗ , t ∗ ∼ π ∗ [ ∑ p i ∗ ∈ p ∗ l o g π θ p l h ( p i ∗ ∣ i , y i n s ) + ∑ t i ∗ ∈ t ∗ l o g π θ t o k ( t i ∗ ∣ i , y i n s ′ ) ] ⏟ I n s e r t i o n O b j e c t i v e , \underbrace{\mathbb E_{\textbf y_{del}\sim d_{\tilde \pi_{del}};\textbf d^*\sim \pi^*}\sum_{d^*_i\in\textbf d^*}log~\pi^{del}_{\theta}(d^*_i|i,\textbf y_{del})}_{Deletion~Objective}+\underbrace{\mathbb E_{\textbf y_{ins}\sim d_{\tilde \pi_{ins}};\textbf p^*,\textbf t^*\sim \pi^*}[\sum_{p^*_i\in \textbf p^*}log~\pi^{plh}_{\theta}(p^*_i|i,\textbf y_{ins})+\sum_{t^*_i\in \textbf t^*}log~\pi^{tok}_{\theta}(t^*_i|i,\textbf y'_{ins})]}_{Insertion Objective}, Deletion Objective
Eydel∼dπ~del;d∗∼π∗di∗∈d∗∑log πθdel(di∗∣i,ydel)+InsertionObjective
Eyins∼dπ~ins;p∗,t∗∼π∗[pi∗∈p∗∑log πθplh(pi∗∣i,yins)+ti∗∈t∗∑log πθtok(ti∗∣i,yins′)],
其中 y i n s ′ \textbf y'_{ins} yins′是在 y i n s \textbf y_{ins} yins上插入占位符 p ∗ \textbf p^∗ p∗后的输出。 π ~ d e l , π ~ i n s \tilde π_{del},\tilde π_{ins} π~del,π~ins是roll-in策略,我们从它们的诱导状态分布 d π ~ d e l , d π ~ i n s d_{\tilde π_{del}},d_{\tilde π_{ins}} dπ~del,dπ~ins反复绘制状态(序列)。这些状态序列首先由专家策略执行,并由专家返回建议的操作,然后将它们的条件对数概率最大化。根据定义,roll-in策略确定训练期间馈入πθ的状态分布。在这项工作中,我们有两种方法来构建roll-in策略—在真实数据中增加噪声或使用对抗政策的输出。图2显示了这种学习范例的示意图。我们正式记录了以下roll-in策略。
Learning to Delete。通过混合因子 α ∈ [ 0 , 1 ] α∈[0,1] α∈[0,1],我们将 π ~ d e l \tilde π_{del} π~del设计为初始输入 y 0 \textbf y^0 y0或应用模型的插入操作输出之间的随机混合:
d π ~ d e l = { y 0 i f u < α e l s e E ( E ( y ′ , p ∗ ) , t ~ ) , p ∗ ∼ π ∗ , t ~ ∼ π θ } (6) d_{\tilde \pi_{del}}=\{\textbf y^0~~if~~u\lt \alpha~~else~~\mathcal E(\mathcal E(\textbf y',\textbf p^*),\tilde \textbf t),\textbf p^*\sim\pi^*,\tilde \textbf t\sim \pi_{\theta}\}\tag{6} dπ~del={
y0 if u<α else E(E(y′,p∗),t~),p∗∼π∗,t~∼πθ}(6)
其中 u 〜 U n i f o r m [ 0 , 1 ] u〜Uniform[0,1] u〜Uniform[0,1]和 y ′ \textbf y' y′是准备插入字符的任何序列。通过采样而不是从等式(5)中求出argmax来获得 t ~ \tilde \textbf t t~。
Learning to Insert。与删除步骤类似,受训练屏蔽语言模型的最新发展启发,我们将删除输出和对真实序列随机丢弃单词所得输出混合使用。我们之所以使用随机丢弃作为加噪的一种形式,以鼓励更多的探索。令 β ∈ [ 0 , 1 ] β∈[0,1] β∈[0,1]和 u 〜 U n i f o r m [ 0 , 1 ] u〜Uniform[0,1] u〜Uniform[0,1],
KaTeX parse error: Undefined control sequence: \p at position 169: …\textbf d \sim \̲p̲^{RND}\}\tag{7}
(2)Expert Policy
在模仿学习中构建专家策略至关重要,因为学习起来不能太难或太弱。具体来说,我们考虑了两种类型的专家:
Oracle。一种方法是建立一个可访问真实序列的oracle。它通过以下方式返回最佳操作 a ∗ \textbf a^∗ a∗(插入 p ∗ , t ∗ p^∗,t^∗ p∗,t∗或删除 d ∗ d^∗ d∗):
a ∗ = a r g m i n a D ( y ∗ , E ( y , a ) ) (8) \textbf a^*=\mathop{argmin}\limits_{\textbf a}~\mathcal D(\textbf y^*,\mathcal E(\textbf y,\textbf a))\tag{8} a∗=aargmin D(y∗,E(y,a))(8)
在这里,考虑到可以通过动态规划有效地获得动作建议,我们使用Levenshtein距离作为 D \mathcal D D。
Distillation。我们还探索使用另一种teacher模型来提供专家策略,这被称为 sequence-level knowledge distillation。 该技术已广泛用于先前的非自回归生成方法中。更准确地说,我们首先使用相同的数据集训练自回归teacher模型,然后用该教师模型的集束搜索结果 y A R \textbf y^{AR} yAR替换真实序列 y ∗ \textbf y^∗ y∗。我们使用与真实数据相同的机制来找到建议的动作。
3.3 推理
Greedy Decoding。在推理时,我们将训练后的模型应对初始序列 y 0 \textbf y^0 y0进行多次迭代。我们选择与等式3,4,5中的最高概率对应的动作。此外,我们发现使用搜索(而不是贪心解码)或噪声并行解码不会在LevT中获得太多收益。这种观察与自回归解码中广泛发现的相反。我们假设可能有两个原因导致此问题:(i)自回归模型中贪心解码带来的局部最优点通常离全局最优点很远。搜索技术通过表格化解决了这个问题。但是,在我们的情况下,由于LevT动态地插入或删除字符,因此可以轻松地删除次优字符,然后重新插入更好的字符。(ii)LevT的对数概率不是选择最佳输出的好指标。但是,我们确实相信,如果我们包含一个外部重新排名工具,例如,自回归teacher模型,能够对模型带来较大提升。我们把这个讨论留在以后的工作中。
Termination Condition。当满足以下两个条件之一时,解码将停止:
循环:如果两个连续的优化迭代返回相同的输出,则生成将终止,该输出可能是(i)没有要删除或插入的单词; (ii)agent陷入无限循环:即插入和删除相互抵消并保持循环。
超时:我们进一步设置了最大迭代次数(超时),以确保在最坏情况下保持恒定的时间复杂度。
Penalty for Empty Placeholder。与 Stern et al. (2019) 类似,我们增加了在解码中插入占位符数目为0的惩罚。过度插入0占位符可能会导致输出缩短。从等式(4)中的对数0中减去惩罚项 γ ∈ [ 0 , 3 ] γ∈[0,3] γ∈[0,3]。