# !/usr/bin/env Python3
# -*- coding: utf-8 -*-
# @version: v1.0
# @Author : Meng Li
# @contact: [email protected]
# @FILE : torch_transformer.py
# @Time : 2022/6/22 15:10
# @Software : PyCharm
# @site:
# @Description : 自己实现的基于Encoder-Decoder的Transformer模型
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
import numpy as np
import math
torch.backends.cudnn.enabled = False
dim = 64 # Q K V 矩阵的维度
embed_size = 512
batch_size = 2
num_heads = 8
num_layers = 6
d_ff = 2048 # FeedForward dimension
dropout = 0.5
mask_pt_flg = False
sentences = [
# enc_input dec_input dec_output
['ich mochte ein bier P', 'S i want a beer .', 'i want a beer . E'],
['ich mochte ein cola P', 'S i want a coke .', 'i want a coke . E']
]
src_vocab_size = len(set(np.array([i[0].split(" ") for i in sentences]).flatten())) # 计算sentences中enc_input中单词最长的长度
# 计算sentences中 dec_input + dec_output 中单词最长的长度
dst_vocab_size = len(
set(np.array([i[1].split(" ") for i in sentences] + [i[2].split(" ") for i in sentences]).flatten()))
class my_dataset(Dataset):
def __init__(self, enc_inputs, dec_inputs, dec_outputs):
super(my_dataset, self).__init__()
self.enc_inputs = enc_inputs
self.dec_inputs = dec_inputs
self.dec_outputs = dec_outputs
def __getitem__(self, index):
return self.enc_inputs[index], self.dec_inputs[index], self.dec_outputs[index]
def __len__(self):
return self.enc_inputs.size(0) # 返回张量的第一个维度
def get_attn_pad_mask(seq_q, seq_k):
"""
:param seq_q: seq_q -> [Batch_size, len_q]
:param seq_k: seq_k -> [Batch_size, len_k]
:return:
"""
Batch_size, len_q = seq_q.size()
Batch_size, len_k = seq_k.size()
atten_mask = seq_k.eq(0).unsqueeze(1) # atten_mask -> [Batch_size, 1, len_k]
atten_mask = atten_mask.expand(Batch_size, len_q, len_k) # atten_mask -> [Batch_size, len_q, len_k]
return atten_mask
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask):
"""
Q: [batch_size, n_heads, len_q, d_k]
K: [batch_size, n_heads, len_k, d_k]
V: [batch_size, n_heads, len_v(=len_k), d_v]
attn_mask: [batch_size, n_heads, seq_len, seq_len]
这里求取注意力相似度采用的是可缩放点积,普通的点乘,方差会很大,反向传播时梯度会变小
"""
# scores : [batch_size, n_heads, len_q, len_k] 表明向量len_q 与 向量len_k之间的相似度
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(dim) # scores : [batch_size, n_heads, len_q, len_k]
# 将矩阵scores中attn_mask为True时对应的元素索引置-1e9
# scores.masked_fill_(attn_mask, -1e9) # Fills elements of self tensor with value where mask is True.
scores.masked_fill_(attn_mask, 0) # Fills elements of self tensor with value where mask is True.
# scores = torch.matmul(attn_mask.float(), scores)
attn = nn.Softmax(dim=-1)(scores) # [batch_size, n_heads, len_q]
# atten_mask 与 V 相乘得到经过Masked后的注意力矩阵
context = torch.matmul(attn, V) # [batch_size, n_heads, len_q, d_v]
return context
def get_attn_subsequence_mask(seq):
"""
seq: [batch_size, dst_len]
return:
[[1., 0., 0., 0.],
[1., 1., 0., 0.],
[1., 1., 1., 0.],
[1., 1., 1., 1.]]
"""
_, dst_len = seq.size()
subsequence_mask = 1 - torch.triu(seq, diagonal=1) # [Batch_size, dst_len]
subsequence_mask = subsequence_mask.unsqueeze(-1) # [Batch_size, dst_len, 1]
subsequence_mask = subsequence_mask.repeat(1, 1, dst_len) # [Batch_size, dst_len, dst_len]
return subsequence_mask # [batch_size, dst_len, dst_len]
def make_data(seq_data):
"""
:param seq_data:
:return: 返回的是三个张量:enc_inputs, dec_inputs, dec_outputs 张量维度分别是[Batch_size, seq_len, embed_size]
seq_len是句子长度, embed_size是词汇表长度
"""
src_vocab = [i[0].split(" ") for i in seq_data]
src_vocab = set(np.array(src_vocab).flatten())
target_vocab = [i[1].split(" ") for i in seq_data] + [i[2].split(" ") for i in seq_data]
target_vocab = set(np.array(target_vocab).flatten())
enc_input_all, dec_input_all, dec_output_all = [], [], []
src_word2idx = {j: i for i, j in enumerate(src_vocab)}
dst_word2idx = {j: i for i, j in enumerate(target_vocab)}
for seq in seq_data:
enc_input = [src_word2idx[n] for n in seq[0].split(" ")]
dec_input = [dst_word2idx[i] for i in seq[1].split(" ")]
dec_output = [dst_word2idx[i] for i in seq[2].split(" ")]
enc_input_all.append(enc_input)
dec_input_all.append(dec_input)
dec_output_all.append(dec_output) # not one-hot
# make tensor
return torch.LongTensor(enc_input_all), torch.LongTensor(dec_input_all), torch.LongTensor(dec_output_all)
enc_inputs, dec_inputs, dec_outputs = make_data(sentences)
train_data = my_dataset(enc_inputs, dec_inputs, dec_outputs)
train_data_iter = DataLoader(train_data, batch_size, shuffle=False)
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
"""
x: [seq_len, batch_size, d_model]
"""
x = x + self.pe[:x.size(0), :]
return self.dropout(x)
class Multi_Head_Attention(nn.Module):
def __init__(self):
super().__init__()
self.W_Q = nn.Linear(embed_size, dim * num_heads, bias=False) # 将输入矩阵映射为低维度
self.W_K = nn.Linear(embed_size, dim * num_heads, bias=False) # 将输入矩阵映射为低维度
self.W_V = nn.Linear(embed_size, dim * num_heads, bias=False) # 将输入矩阵映射为低维度
self.projection = torch.nn.Linear(num_heads * dim, embed_size) # 将atten的维度转换为与输入的维度一致
def forward(self, input_Q, input_K, input_V, atten_mask):
"""
:param input_Q: -> [Batch_size, len_q, embedding_size]
:param input_K: -> [Batch_size, len_k, embedding_size]
:param input_V: -> [Batch_size, len_v(=len_k), embedding_size]
:param atten_mask: -> [Batch_size, atten_len_k, atten_len_v]
:return: 这里的dim是QKV矩阵的维度
# 对输入求得Q、K、V三个矩阵,然后根据Q和K矩阵求得注意力矩阵,最后根据注意力矩阵求得经过Masked后的注意力矩阵
# 返回的enc_inputs 和 atten 张量维度的一样的
"""
torch.backends.cudnn.enabled = False
residual = input_Q # [Batch_size, len_q, embedding_size] 这里是残差项,多层注意力的输出与此项相加
_, len_q, embedding_size = input_Q.size()
_, len_k, _ = input_K.size()
Batch_size, atten_len_k, atten_len_v = atten_mask.size()
# 输入乘以矩阵得到Q、K、V矩阵
Q = self.W_Q(input_Q).view(Batch_size, num_heads, len_q, dim) # Q -> [Batch_size, len_q, dim*num_heads]
K = self.W_K(input_K).view(Batch_size, num_heads, len_k, dim) # K -> [Batch_size, len_k, dim*num_heads]
V = self.W_V(input_V).view(Batch_size, num_heads, len_k, dim) # V -> [Batch_size, len_v, dim*num_heads]
atten_mask = atten_mask.unsqueeze(1) # atten_mask -> [Batch_size, 1, atten_len_k, atten_len_v]
# atten_mask -> [Batch_size, num_heads, atten_len_k, atten_len_v] 这里的 atten_len_v == len_q
atten_mask = atten_mask.repeat(1, num_heads, 1, 1)
atten = ScaledDotProductAttention()(Q, K, V, atten_mask)
atten = atten.transpose(1, 2) # atten -> [Batch_size, atten_len_k, num_heads, dim]
atten = atten.reshape(Batch_size, atten_len_k, -1) # atten -> [Batch_size, atten_len_k, num_heads * dim]
atten = self.projection(atten) # atten -> [Batch_size, atten_len_k, embed_size] atten_len_k == len_q
# softmax 不改变矩阵的维度,这里对行方向对行向量进行归一化 这里对输出和残差 进行Add && Norm 操作
atten_ret = (residual + torch.softmax(atten, dim=1))
atten_ret = nn.LayerNorm(embed_size).to(device)(atten_ret)
return atten_ret
class Feed_forward(nn.Module):
"""
对应于原论文中的Feed-Forward流程
查看某个数据是否存储于cuda上,可键入命令: x.is_cuda 其中x为变量
"""
def __init__(self):
super().__init__()
self.W1 = nn.Linear(embed_size, d_ff).to(device)
self.W2 = nn.Linear(d_ff, embed_size).to(device)
self.b1 = torch.rand(d_ff).to(device)
self.b2 = torch.rand(embed_size).to(device)
self.relu = nn.ReLU().to(device)
self.dropout = nn.Dropout(p=dropout)
def forward(self, enc_inputs):
"""
:param enc_inputs: # enc_inputs -> [Batch_size, seq_len, embedding_size]
# atten -> [Batch_size, seq_len, embedding_size]
:return:
"""
fc1 = self.W1(enc_inputs) + self.b1
fc1 = self.relu(fc1)
fc2 = self.W2(fc1) + self.b2 # fc2 -> [Batch_size, seq_len, embedding_size]
output = fc2 # output -> [Batch_size, seq_len, embedding_size]
residual = enc_inputs
Add_And_Norm = nn.LayerNorm(embed_size).cuda()(output + residual)
return Add_And_Norm
class Encoder_layer(nn.Module):
def __init__(self):
super().__init__()
self.multi_head_attention = Multi_Head_Attention()
self.feed_forward = Feed_forward()
def forward(self, enc_inputs, enc_atten_mask):
"""
:param enc_inputs: -> [Batch_size, src_len, embedding_size]
:param enc_atten_mask: -> [Batch_size, src_len, src_len]
:return:
"""
# 传入多层注意力机制的输入Q、K、V 都假定为一样的
atten_output = self.multi_head_attention(enc_inputs, enc_inputs, enc_inputs, enc_atten_mask) # 这里得到的是注意力矩阵
output = self.feed_forward(atten_output).to(device) # output -> [Batch_size, seq_len, embeded_size]
return output, atten_output
class Decoder_layer(nn.Module):
def __init__(self):
super().__init__()
self.masked_multi_head_attention = Multi_Head_Attention()
self.multi_head_attention = Multi_Head_Attention()
self.feed_forward = Feed_forward()
self.embed = torch.nn.Embedding(dst_vocab_size, embed_size)
def forward(self, dec_input, enc_output, dec_atten_mask, dec_mask_atten_mask):
"""
:param dec_input: [Batch_size, dst_len]
:param enc_output: [Batch_size, src_len]
:param dec_atten_mask: [Batch_size, dst_len, dst_len]
:param dec_mask_atten_mask: [Batch_size, dst_len, src_len]
:return: [Batch_size,dst_len,embedding_size]
查看变量类型 -> 采用 data.dtype
"""
# 得到Decoder Layer的第一个多层注意力输出,输入为解码层的输入
masked_atten_outputs = self.masked_multi_head_attention(dec_input, dec_input, dec_input, dec_atten_mask)
# masked_atten_outputs -> [Batch_size, dst_len, embedding_size]
# enc_outputs -> [Batch_size, src_len, embedding_size]
# Decoder层第二个多层注意力机制, K和V采用Encoder编码信息矩阵进行计算,Q采用上一个Decoder block进行计算
dec_atten_outputs = self.multi_head_attention(masked_atten_outputs, enc_output, enc_output,
dec_mask_atten_mask)
output = self.feed_forward(dec_atten_outputs) # output -> [Batch_size, dst_len, embeded_size]
return output, dec_atten_outputs
class Encoder(nn.Module):
def __init__(self):
super().__init__()
self.layers = nn.ModuleList(Encoder_layer() for _ in range(num_layers))
self.embed = torch.nn.Embedding(src_vocab_size, embed_size)
self.pos = PositionalEncoding(embed_size)
def forward(self, enc_input_encoder):
"""
:param enc_input_encoder: -> [Batch_size, src_len]
:param enc_atten_mask: -> [Batch_size, src_len, src_len]
:return:
"""
self_atten = get_attn_pad_mask(enc_input_encoder, enc_input_encoder) # [Batch_size, seq_len, seq_len]
enc_input_embed = self.embed(enc_input_encoder) # output -> [Batch_size, seq_len, embed_size]
output = self.pos(enc_input_embed.transpose(0, 1)).transpose(0, 1)
for layer in self.layers:
output, atten = layer(output, self_atten) # output -> [Batch_size, seq_len, embedding_size]
return output
class Decoder(nn.Module):
def __init__(self):
super().__init__()
self.layers = nn.ModuleList(Decoder_layer() for _ in range(num_layers))
self.embed = torch.nn.Embedding(dst_vocab_size, embed_size) # 这里的维度一定要正确,否则会由于索引超过范围报错
self.pos = PositionalEncoding(embed_size)
def forward(self, decoder_enc_input, decoder_dec_input, decoder_enc_output):
"""
:param decoder_enc_input: [Batch_size, src_len]
:param decoder_dec_input: [Batch_size, dst_len]
:param decoder_enc_output:[Batch_size, src_len, embedding_size]
:return: 第一个多头注意力模块的输入序列不能看到当前token之后的信息,需要对当前token之后的tokens进行mask
"""
dec_inputs_embed = self.embed(decoder_dec_input) # [Batch_size, dst_len, embedding_size]
# output = self.pos(dec_inputs_embed)
dec_inputs_embed_pos = self.pos(dec_inputs_embed.transpose(0, 1)).transpose(0, 1).to(device)
output = dec_inputs_embed_pos
dec_self_atten = get_attn_pad_mask(decoder_dec_input, decoder_dec_input).to(
device) # [Batch_size, dst_len, dst_len]
sub_mask = get_attn_subsequence_mask(decoder_dec_input) # [Batch_size, dst_len, dst_len]
dec_self_atten = dec_self_atten * sub_mask # 将斜三角矩阵与
dec_self_atten = dec_self_atten.bool() # 将矩阵转化为bool型,方便后续调用torch.mask_fill函数
# 得到的是解码器的第二个注意力层->交叉注意力
dec_cross_atten = get_attn_pad_mask(decoder_dec_input, decoder_enc_input).to(
device) # [Batch_size, dst_len, src_len]
# dec_atten_mask = get_attn_pad_mask(decoder_dec_input, decoder_dec_input).to(device) # [Batch_size, dst_len, src_len]
for layer in self.layers:
output, atten = layer(output, decoder_enc_output, dec_self_atten, dec_cross_atten)
return output
class Transformer(nn.Module):
def __init__(self):
super().__init__()
self.encoder = Encoder().to(device)
self.decoder = Decoder().to(device)
self.lr_rate = 1e-3
self.optim = torch.optim.Adam(self.parameters(), lr=self.lr_rate)
self.crition = nn.CrossEntropyLoss(ignore_index=0)
self.projection = nn.Linear(embed_size, dst_vocab_size, bias=False).to(device)
def forward(self, enc_input, dec_input, dec_output):
"""
:param enc_input: -> [Batch_size, src_len]
:param dec_input: -> [Batch_size, dst_len]
:param dec_output: -> [Batch_size, dst_len]
:return:
"""
encode_outputs = self.encoder(enc_input) # enc_outputs -> [Batch_size, src_len, embedding_size]
# decode_output -> [Batch_size, dst_len, embedding_size]
decode_output = self.decoder(enc_input, dec_input, encode_outputs)
decode_output = self.projection(decode_output) # decode_output -> [Batch_size, dst_len, dst_vocab_size]
out_put = torch.argmax(decode_output, 2) # 沿维度为2的维度求取最大值的索引
loss = 0
# decode_output = decode_output.view(-1, out_put.size(-1))
# out_put = out_put.view(
for i in range(len(decode_output)): # 对seq的每一个输出进行二分类损失计算
loss += self.crition(decode_output[i], dec_output[i])
# dec_output = dec_output.view(-1) # decode_output -> [Batch_size * dst_len]
# decode_output = decode_output.view(-1, decode_output.size(-1)) # [Batch_size * dst_len, dst_vocab_size]
# print("dec_output.size() ", dec_output.size())
# print("decode_output.size()", decode_output.size())
# loss = self.crition(decode_output, dec_output)
return out_put, loss
device = "cuda" if torch.cuda.is_available() else "cpu"
model = Transformer().to(device)
lr_rate = 1e-3
# optimizer = torch.optim.Adam(model.parameters(), lr=lr_rate)
optimizer = torch.optim.SGD(model.parameters(), lr=lr_rate, momentum=0.99)
for i in range(1000):
for enc_inputs_i, dec_inputs_i, dec_output_i in train_data_iter:
enc_inputs_i, dec_inputs_i, dec_output_i = enc_inputs_i.to(device), dec_inputs_i.to(device), dec_output_i.to(
device)
predict, loss_i = model(enc_inputs_i, dec_inputs_i, dec_output_i)
optimizer.zero_grad()
loss_i.backward()
optimizer.step()
if i % 100 == 0:
print("step {0} loss {1}".format(i, loss_i))
# print("predict ", predict)
先上代码。
根据Transformer的论文,采用Pytorch框架基于Encoder_Decoder+Multi-Head Attention多层注意力模型构建的Transformer框架,用来进行机器翻译
为了方便,语料库采用自己构造的语料库
# enc_input dec_input dec_output
['ich mochte ein bier P', 'S i want a beer .', 'i want a beer . E'],
['ich mochte ein cola P', 'S i want a coke .', 'i want a coke . E']
数据集的构建采用DataSet和DataLoader两个原生类,将语料库采用键值对的形式进行保存
enc_input: [[1, 2, 3, 4, 0], [1, 2, 3, 5, 0]]
dec_input: [[6, 1, 2, 3, 4, 8], [6, 1, 2, 3, 5, 8]]
dec_output:[[1, 2, 3, 4, 8, 7], [1, 2, 3, 5, 8, 7]]这三个输入分别为编码器的输入,解码器的输入以及解码器的输出。这里解码器的输入为真实的解码器的输出是为了在编解码器模型中采用Teacher-Forcing模型进行训练。(与不采用Teacher-Forcing方法相比,在小规模的样本中模型的准确率区别不大,大规模样本中没有测试过)
根据Transforer原论文,每个词向量维度为512维,这里采用Torch.nn.Embedding将词索引转化为向量
self.embed = torch.nn.Embedding(src_vocab_size, embed_size)src_vocab_size 为语料库的大小,embed_size为向量的维度。由于Transformer没有向RNN/LSTM/GRU等循环神经网络一样对具有时序性的序列进行建模,故这里有一个基于位置的Encoding,采用的是数学公式法,sin/cos:
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
"""
x: [seq_len, batch_size, d_model]
"""
x = x + self.pe[:x.size(0), :]
return self.dropout(x)其实就是将语料根据相对位置采用正余弦函数进行编码。将编码后的值与self.embed进行累加,作为网络的输入,此时向量中既包含了不同分词之间的位置信息又包含了语义信息
enc_input_embed = self.embed(enc_input_encoder)
output = self.pos(enc_input_embed.transpose(0, 1)).transpose(0, 1)在编码器中,
Encoder由num_heads个同样大小的编码器串联。为什么要串联,我个人觉得跟CV里面的加深网络深度差不多的意思。这里采用 nn.ModuleList 将num_heads个编码器连接起来
self.layers = nn.ModuleList(Encoder_layer() for _ in range(num_layers))解码器的构造跟编码器类似,但是解码器有两个多层注意力层
第一个多层注意力层是将解码器的输入进行注意力转换得到与输入同样大小的输出,这个叫自注意力层。

比如,解码器的输入在经过位置编码和embedding后的输入:dec_inputs -> [Batch_size, dst_len, embedding_size]
解码器的输出也是同样大小,dec_outputs -> [Batch_size, dst_len, embedding_size]
第二层注意力层的input_Q为第一层的输出,input_K和input_Q为Encoder的输出,这样做的目的是根据解码器的输入找到和编码器的输出之前的相关性,并得到解码器的输出。
这三个注意力层需要着重说明一下
Encoder层的注意力层
因为在做语料库的时候,不同的语句长短不一,需要对长度少于vocab_size的语句进行补0操作。但是在求注意力的时候,是对向量的每一个元素都进行求解的,这个时候那些为0的zero_padding元素也会得到一个注意力值,但是这个注意力值是没有任何意义的,需要采用一个mask矩阵将其进行过滤。
def get_attn_pad_mask(seq_q, seq_k):
"""
:param seq_q: seq_q -> [Batch_size, len_q]
:param seq_k: seq_k -> [Batch_size, len_k]
:return:
"""
Batch_size, len_q = seq_q.size()
Batch_size, len_k = seq_k.size()
atten_mask = seq_k.eq(0).unsqueeze(1) # atten_mask -> [Batch_size, 1, len_k]
atten_mask = atten_mask.expand(Batch_size, len_q, len_k) # atten_mask -> [Batch_size, len_q, len_k]
return atten_maskDecoder层的自注意力层
Decoder的第一层是自注意力层,我们知道Transformer模型是由Seq2Seq+Attention 演化而来的,Seq2Seq的解码器中,是从左到右,逐字翻译的,也就是说每翻译一个token时,仅注意到当前词以及之前的词,这样做就是在训练时在预测某个token时不用看到这个token,那么在Transformer中,也是这样。所以为了满足这个算法条件,这里采取了一个mask矩阵。这里的注意力是对解码器的输入求注意力,一般 在训练时有训练集的输入,而在测试时,解码器的输入是随机生成的或者是初始化值,不过这都没关系。关于针对顺序解码的自注意力如下代码所示:
def get_attn_subsequence_mask(seq):
"""
seq: [batch_size, dst_len]
return:
[[1., 0., 0., 0.],
[1., 1., 0., 0.],
[1., 1., 1., 0.],
[1., 1., 1., 1.]]
"""
_, dst_len = seq.size()
subsequence_mask = 1 - torch.triu(seq, diagonal=1) # [Batch_size, dst_len]
subsequence_mask = subsequence_mask.unsqueeze(-1) # [Batch_size, dst_len, 1]
subsequence_mask = subsequence_mask.repeat(1, 1, dst_len) # [Batch_size, dst_len, dst_len]
return subsequence_mask # [batch_size, dst_len, dst_len]上面的mask,是专门处理解码器中顺序解码token的。这种注意力机制后面会用到GPT模型上
Decoder层的交叉注意力层
交叉注意力层是求解码器的输入与编码器的输出之间的注意力,这个与Seq2Seq模型中是一致的,模型的设计本身就应该是这样的,编码器的输出本身就应该是解码器的输出的参考。求Mask的思路跟Encoder是一致的。这里不做赘述。
多头注意力机制
其实Transformer用到的都是多头注意力机制,多头(Head)意思跟CV里面的多层卷积核差不多,每个注意力头都是一种特征提取机制,这样做的话能够提取更加丰富的语言特征信息。
不过这里有一个问题, 在对得到的注意力矩阵(atten)采用注意力掩码矩阵(atten_mask)进行mask后(这样做的目的是因为,句子中的每个词都只能对包括自己在内的前面所有词进行 Attention),训练模型,模型的损失Loss,在迭代1000次后,下降不明显一直维持在0.1左右。在这段时间成为了NLP在我心中的一朵乌云
scores = torch.matmul(atten_mask, atten)对求得的注意力进行masked,主要是因为在工程上为了处理不同的句子长度要进行padding操作,在self attention的时候,不希望把注意力放在padding的地方,因此通常要有一个mask矩阵来标识哪些位置是mask的,通常mask的位置给一个负无群大的值,在softmax的时候概率就转换为0了。
def get_attn_pad_mask(seq_q, seq_k):
"""
:param seq_q: seq_q -> [Batch_size, len_q]
:param seq_k: seq_k -> [Batch_size, len_k]
:return:
"""
Batch_size, len_q = seq_q.size()
Batch_size, len_k = seq_k.size()
atten_mask = seq_k.eq(0).unsqueeze(1) # atten_mask -> [Batch_size, 1, len_k]
atten_mask = atten_mask.expand(Batch_size, len_q, len_k) # atten_mask -> [Batch_size, len_q, len_k]
return atten_mask上述代码就是将向量中进行padding之后的 位置进行标记,在对self-Attention求得的注意力矩阵
这样做主要是Transformer在进行预测时,当前词仅获取当前词之前的词语之间的注意力进行计算,所以对求取出来的注意力进行注意力掩码计算,但是直接用掩码(atten_mask)与 注意力(atten)进行相乘,因为atten_mask中包含有0的部分,这样会导致得到的注意力atten中存在部分值为0的元素,在反向传播时存在梯度消失的情况。
所以我进行了改进,改成了
scores.masked_fill_(attn_mask, -1e9)这样的话, 得到的注意力矩阵中就没有元素值为零
这是采用点积进行注意力机制计算的Loss结果,可以看到Loss在迭代到100次后几乎没有明显的变化,说明梯度很小,在回传时出现梯度消失了
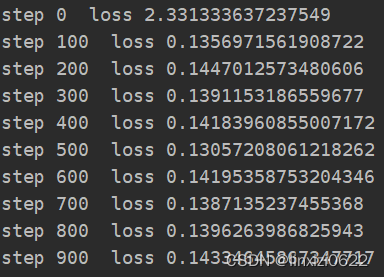
在将点积更改为可缩放点积之后,loss下降的情况

可以看出,Loss 在每迭代100次,每次下降一个数量级
所以可缩放点积代替点积是可行的
其他方面没什么好说的,因为这是一个基于序列多分类的问题,在模型的输出端遍历序列,对每个分类采用交叉熵求得loss再相加,再进行反向传播即可。