一.配置环境及数据准备
我们要在ubuntu16.04系统上先搭建好caffe的环境,确保能正常使用。然后准备好数据集,接下来准备制作我们自己的数据集。如果只是拿来练手,那caffe/examples/images/下的图片就可以先用来练手。
先把最后的成果放上来,有个感性认识

二.目的简介
我们在学习深度(caffe框架)的时候,多数用的都是别人处理好的图片数据集,我们自己手里的图片的文件的格式为jpg,png,jpeg等而且可能图片的大小还不一致,但是caffe中使用的数据类型为lmdb或leveldb,所以我们需要将原始的图片文件转换成caffe中使用的数据类型。
在caffe/build/tools/文件夹下,有一个convert_imageset.cpp文件,这个文件的作用就是用于将图片文件转换成caffe框架中能直接使用的db文件。
使用格式为:
convert_imageset [FLAGS] ROOTFOLDER/ LISTFILE DB_NAME参数解读:
FLAGS:图片参数组
ROOTFOLDER:原始数据集的绝对路径
LISTFILE:图片的文件名列表,一般为txt文件,一行一张图片的信息,下面会给出如何生成filelist的方法。
DB_NAME:生成的db文件的存放目录
三.生成图片集的列表清单
我先在根目录下创建一个名为mydatabase的文件夹,并在mydatabse下创建cat_dog_train和cat_dog_val文件夹。然后将用来训练的图片放入cat_dog_train文件夹下,将用来验证的图片放入cat_dog_val文件夹下。
接下来我们要创建一个sh脚本文件,手动创建并命名为create_trainfilelist.sh
# /usr/bin/env sh
DATA=/home/hca/mydatabase/cat_dog_train #DATA为训练集的路径
echo "Create train.txt..."
rm -rf $DATA/train.txt
find $DATA -name ca*.jpg | cut -d '/' -f6 | sed "s/$/ 1/">>$DATA/train.txt
find $DATA -name do*.jpg | cut -d '/' -f6 | sed "s/$/ 2/">>$DATA/tmp.txt
cat $DATA/tmp.txt>>$DATA/train.txt
rm -rf $DATA/tmp.txt
echo "Done.."这个脚本文件中,用到了rm,find, cut, sed,cat等linux命令。
rm: 删除文件
find: 寻找文件
cut: 截取路径
sed: 在每行的最后面加上标注。本例中将找到的*cat.jpg文件加入标注为1,找到的*dog.jpg文件加入标注为2
cat: 将两个类别合并在一个文件里。
然后执行该sh文件
cd caffe
sh /home/hca/mydatabase/create_trainfilelist.sh执行完之后,会在训练集的文件夹下生成train.txt文件,train.txt文件里存放的是训练集中图片的文件名及标签。效果如下:
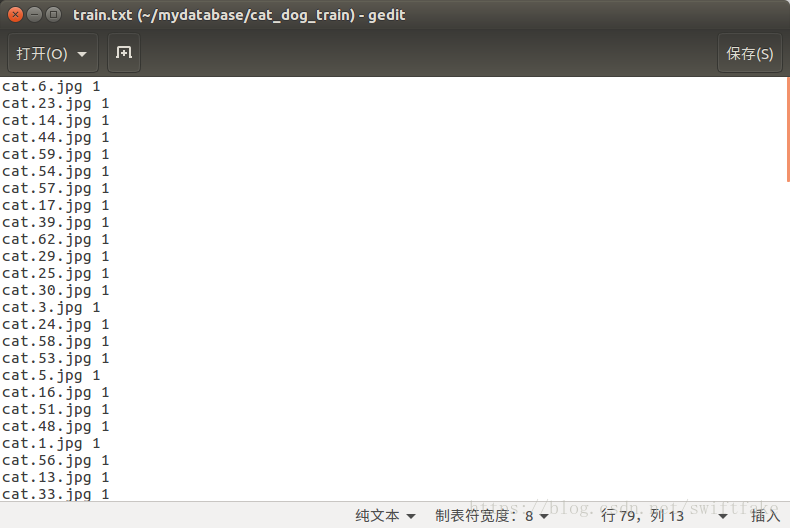
验证列表的清单跟训练列表的几乎一模一样,类比着操作即可。
四.格式转化
在mydatabse文件夹下创建sh脚本文件,我将该文件命名为create_resnet.sh。输入内容为:
#!/usr/bin/en sh
DATA=/home/hca/mydatabase
EXAMPLE=/home/hca/mydatabase
DBTYPE=lmdb
echo "create train lmdb..."
rm -rf $DATA/cat_dog_train_lmdb
build/tools/convert_imageset --shuffle \
--resize_height=224 --resize_width=224 \
/home/hca/mydatabase/cat_dog_train/ $EXAMPLE/cat_dog_train/train.txt $DATA/cat_dog_train_lmdb
echo "Done."
echo "create val lmdb..."
rm -rf $DATA/cat_dog_val_lmdb
build/tools/convert_imageset --shuffle \
--resize_height=224 --resize_width=224 \
/home/hca/mydatabase/cat_dog_val/ $EXAMPLE/cat_dog_val/val.txt $DATA/cat_dog_val_lmdb
echo "Done."
echo "Computing image mean..."
./build/tools/compute_image_mean -backend=$DBTYPE \
$DATA/cat_dog_train_$DBTYPE $DATA/mean.binaryproto
echo "Done."接下来保存并执行该文件
cd caffe
sh /home/hca/mydatabase/cat_dog_train/create_resnet.sh执行完之后,会在mydatabase文件夹下生成cat_dog_train_lmdb、cat_dog_val_lmdb文件夹,和mean.binaryproto文件
五.运行solver.prototxt
在运行solver.prototxt文件之前,我们需要对它做一定的修改
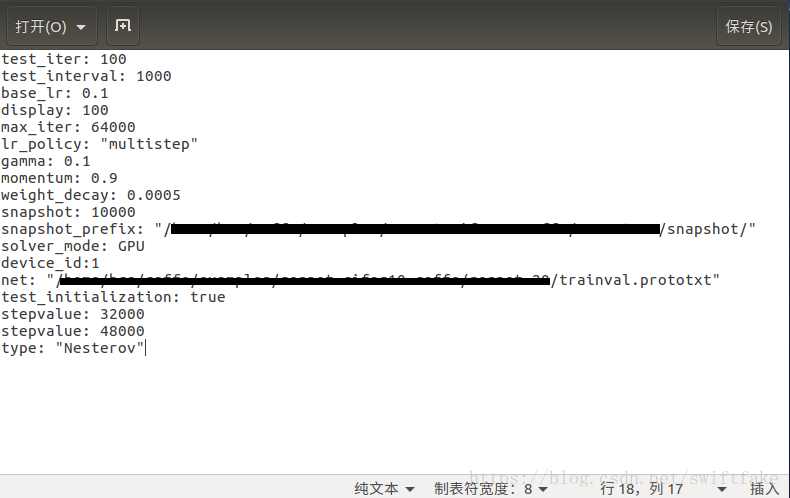
snapshot_prefix:用于存放生成的model的路径(最好写绝对路径)
net:是我们要调用的网络,所以我们需要修改成我们要调用的网络的路径
接下来就要打开我们调用的网络trainval.prototxt文件,修改source路径,并根据需要修改全连接层的num_output参数等。
下面开始运行solver.prototxt
cd caffe
./build/tools/caffe train -solver=/XXX/XXX/…/sovler.prototxt运行结束以后会在snapshot文件夹下生成caffemodel和solverstate文件,一个是模型文件,一个是中间状态文件。当训练过程中断,想要继续训练数据,此时只需要调用solverstate文件即可。命令如下:
cd caffe
./build/tools/caffe train -solver=/XXX/XXX/…/sovler.prototxt -snapshot=/XXX/XXX/…/XX.solverstate当需要用已经训练好的model对某次训练做finetune,可以使用caffemodel,命令如下:
cd caffe
./build/tools/caffe train -solver=/XXX/XXX/…/sovler.prototxt -weights=/XXX/XXX/…/XX.caffemodel