一、深度学习与深层神经网络
深层神经网络是实现“多层非线性变换”的一种方法。
深层神经网络有两个非常重要的特性:深层和非线性。
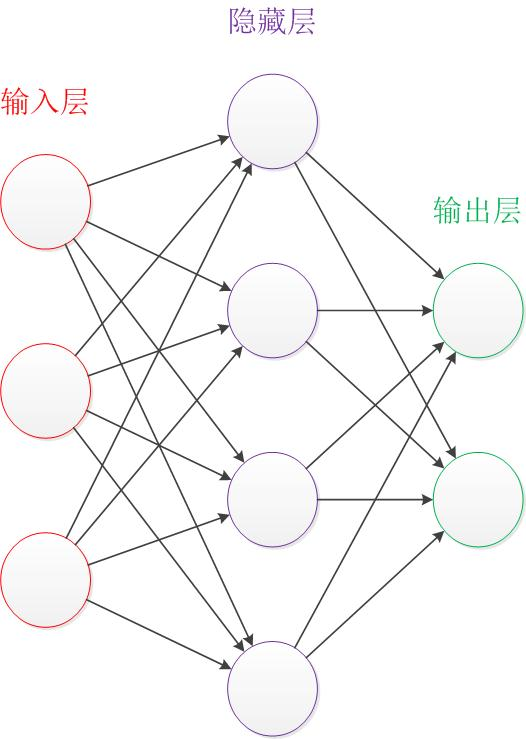
1.1线性模型的局限性
线性模型:y =wx+b
线性模型的最大特点就是任意线性模型的组合仍然还是线性模型。
如果只通过线性变换,任意层的全连接神经网络和单层神经网络模型的表达能力没有任何的区别,它们都是线性模型。然而线性模型能够解决的问题是有限的。
如果一个问题是线性不可分的,通过线性模型就无法很好的去分类这些问题。
1.2激活函数实现去线性化
神经元的输出为所有输入的加权和,所以整个神经网络就是一个线性模型。如果将每个神经元的输出通过一个激活函数,那么整个神经网络就变成了一个非线性的模型。

几种常用的非线性激活函数及其图像。
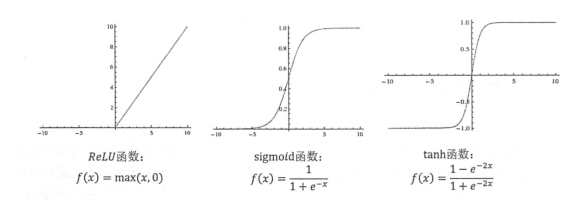
TF提供了7中不同的非线性激活函数,relu,sigmod和tanh是其中最常用的。TF还支持使用自己定义的激活函数。

这是一个加入了偏置项和激活函数的网络结构。
那么,怎么用TF实现这个网络结构的前向传播算法呢。
import tensorflow as tf #声明w1,w2 两个变量,通过seed设定随机种子 w1 = tf.Variable(tf.random_normal([2,3],stddev=1.0 ,seed =1 )) w2 = tf.Variable(tf.random_normal([3,1],stddev=1.0 ,seed =1 )) bias1 = tf. Variable(tf.random_normal([3,1],stddev=1.0 ,seed =1 ))
bias2 = tf. Variable(tf.random_normal([1,1],stddev=1.0 ,seed =1 ))
#暂时将输入的誊正向量定义为一个常量,这里的X是一个【1,2】矩阵 x = tf.constant([[0.7,0.9]]) #通过前向传播算法得到输出y h = tf.nn.relu( tf.matmul(x,w1)+bias1) y =tf.nn.relu( tf.matmul(h,w2)+bias2)
二 损失函数的定义
神经网络的模型的效果及优化的目标是通过损失函数来定义的。
通过神经网络解决多分类问题最常用的方法就是设置n个输出节点,n为类别的个数。神经网络可以得到一个n维数组作为结果输出。数组中的每一个维度对应一个类别。理想情况,如果一个样本属于类别k,那么这个节点对应的维度为1,其他维度为0.如何判断一个输出向量和期望向量有多接近?可以用交叉熵来判断。