目录
2)Forward Propagation in a Deep Network(重点)
3)Getting your matrix dimensions right
4)Building blocks of deep neural networks
5)Forward and Backward Propagation(重点)
6)Parameters vs Hyperparameters
以下笔记是吴恩达老师深度学习课程第一门课第四周的的学习笔记:Deep Neural Networks。笔记参考了黄海广博士的内容,在此表示感谢。
1)Deep L-layer neural network
目前为止我们学习了只有一个单隐藏层的神经网络的正向传播和反向传播,还有逻辑回归,并且你还学到了向量化,这在随机初始化权重时是很重要。本周所要做的是把这些概念集合起来,就可以实现你自己的深度神经网络。
复习下前三周的课的内容:
1.逻辑回归,结构如下图左边。一个隐藏层的神经网络,结构下图右边:
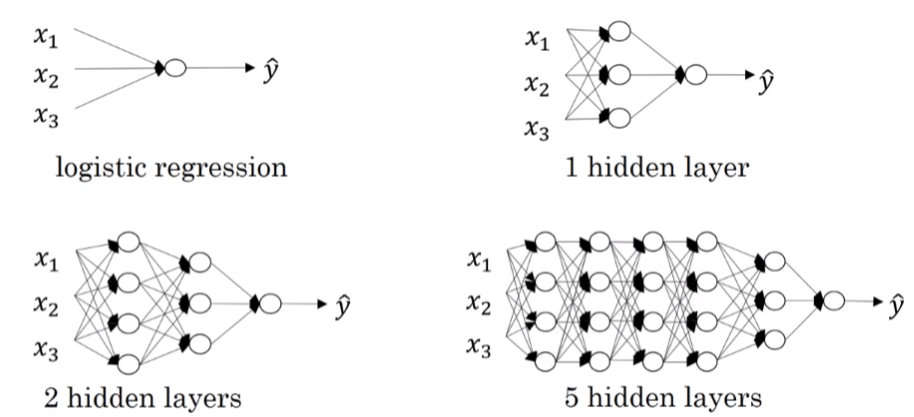
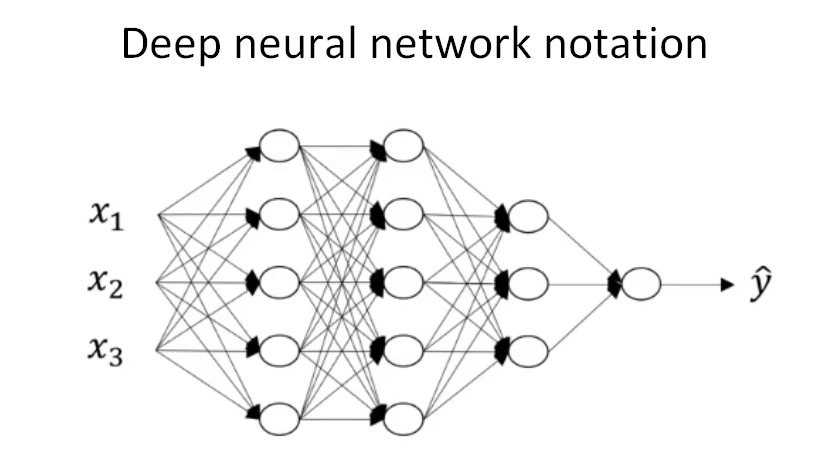
神经网络的层数是这么定义的:从左到右,由0开始定义。如上图:含有一个隐藏层的是2层神经网络,2个隐藏层的是3层神经网络,5个隐藏层的是6层神经网络。我们在这里再复习一下神经网络里常见的符号定义。如下图:
- 总层数L=4。输入层是第0层,输出层是第L层;
表示第l层包含的单元个数,
,下图中
,标识输入特征有3个。
;
- 第l层的输出用
表示,
,
表示l层上的权重;
2)Forward Propagation in a Deep Network(重点)
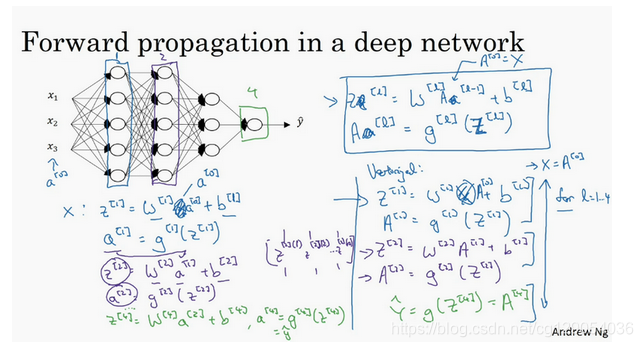
现在我们来推导四层神经网络的输出,我们之前已经推导了2层神经网络的前向传播,四层神经网路只是在计算上多重复了几次。跟往常一样,我们先来看对其中一个训练样本如何应用前向传播,之后讨论向量化的版本。
第一层:
第二层:
以此类推,第四层:
向量化实现过程可以写成:
3)Getting your matrix dimensions right
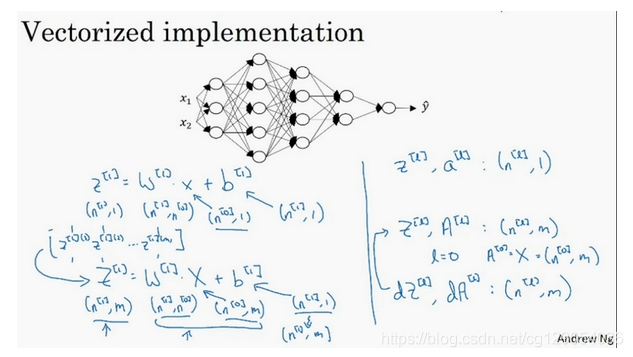
当实现深度神经网络的时候,其中一个我(这里指的是吴恩达老师)常用的检查代码是否有错的方法就是拿出一张纸过一遍算法中矩阵的维数。 对于单个训练样本:
的维度是 :
;
的维度是:
;
其中,
分别表示
层所包含单元个数。
同时,维度相同,
维度相同。且
向量化维度不变 ;但
的维度会向量化后发生变化。
对于m个训练样本,输入矩阵X的维度是,向量化后
的维度变为:
。下图中
的维度也发生了变化,不过这是因为在计算中由于Python的广播性质而变化的。
4)Building blocks of deep neural networks
这周的前几个视频和之前几周的视频里,你已经看到过前向反向传播的基础组成部分了,它们也是深度神经网络的重要组成部分,现在我们来用它们建一个深度神经网络。 如下图所示,对于第层来说:
前向传播:
输入:
;
输出
;
参数:
;缓存变量:
反向传播:
输入:
;
输出
;
参数:
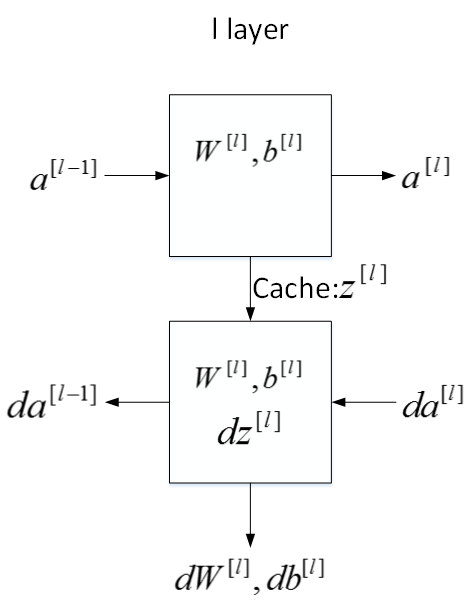
刚才这是第l层的流程块图,对于神经网络所有层,整体的流程块图正向传播过程和反向传播过程如下所示:
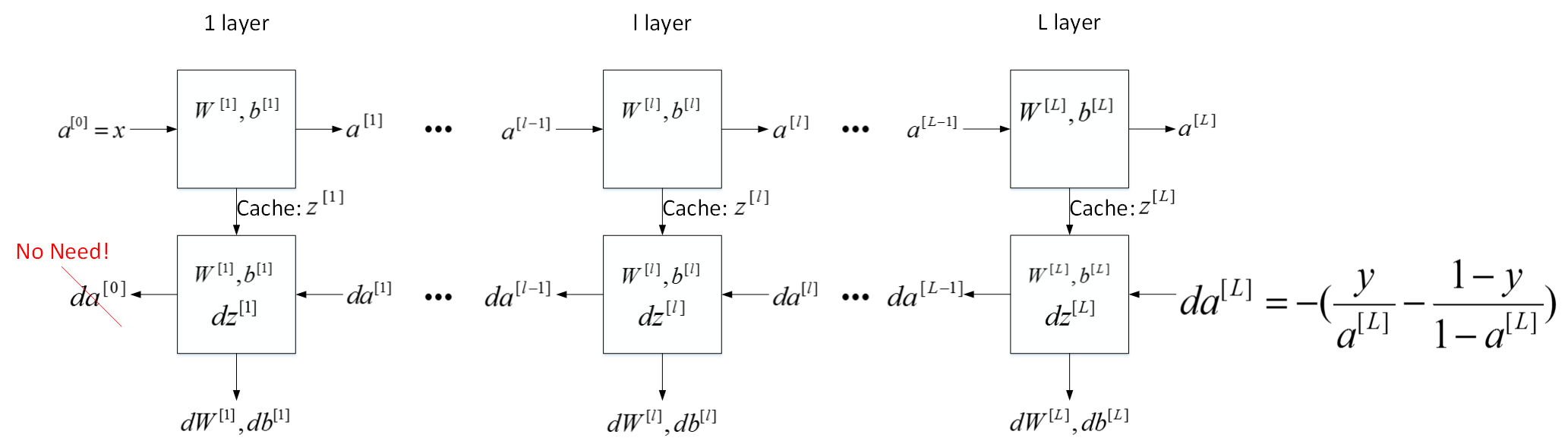
5)Forward and Backward Propagation(重点)
前面我们学习了构成深度神经网络的基本模块,比如每一层都有前向传播步骤以及一个相反的反向传播步骤,这次视频我们讲讲如何实现这些步骤。

先讲前向传播,输入,输出是
,缓存为
; 前向传播的步骤可以写成 :
向量化实现过程可以写成:
下面讲反向传播的步骤:

式子(5)由式子(4)带入式子(1)得到,前四个式子就可实现反向函数。
向量化实现过程可以写成:
6)Parameters vs Hyperparameters
该部分介绍神经网络中的参数(parameters)和超参数(hyperparameters)的概念。神经网络中的参数就是我们熟悉的
和。而超参数则是例如学习速率α,训练迭代次数N,神经网络层数L,各层神经元个数
,激活函数g(z)等。之所以叫做超参数的原因是它们决定了参数
和
的值。在后面的第二门课我们还将学习其它的超参数,这里先不讨论。
如何设置最优的超参数是一个比较困难的、需要经验知识的问题。通常的做法是选择超参数一定范围内的值,分别代入神经网络进行训练,测试cost function随着迭代次数增加的变化,根据结果选择cost function最小时对应的超参数值。这类似于validation的方法
7)Summary
本节课主要介绍了深层神经网络,是上一节浅层神经网络的拓展和归纳。
- 首先,我们介绍了建立神经网络模型一些常用的标准的标记符号。
- 然后,用流程块图的方式详细推导正向传播过程和反向传播过程的输入输出和参数表达式。
- 接着,我们介绍了超参数的概念,解释了超参数与参数的区别。
至此,吴恩达老师深度学习专项课程第一门课《神经网络与深度学习》学习结束。