目录
(博主温馨提示:点关注,不迷路。先赞后看,养成习惯。原创不易,支持一下呗。)
1 前言
接触到爬虫之后,我惊奇于几行代码既可以代替我畅游网络的世界。
我深刻的感受到技术改变了我的生活,每次想到自己编写的代码真的跟自己的生活息息相关都让我充满力量继续学习。
我学习了很多关于爬虫的知识也做了相关的练习,但是水平还很有限。
在此把我对爬虫的理解和我在学习过程当中的感受以及我所学习的内容作为一个教程的方式写出来,希望能够帮到大家,也希望能够和大家一起进步。
如有大佬偶然路过,但请轻喷且多指教。

2 爬虫究竟是什么?
首先我们来看百度百科对网络爬虫的定义:
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
然后是维基百科对爬虫的定义:
网络爬虫(英语:web crawler),也叫网络蜘蛛(spider),是一种用来自动浏览万维网的网络机器人。其目的一般为编纂网络索引。
网络搜索引擎等站点通过爬虫软件更新自身的网站内容或其对其他网站的索引。网络爬虫可以将自己所访问的页面保存下来,以便搜索引擎事后生成索引供用户搜索。
依旧是晦涩难懂的一种状态,相信各位朋友已经开始准备骂娘了。

根据我的理解,简单来讲,爬虫其实就是一个能够代替我们人类网上冲浪的获取信息的一种网络机器人。
比如你今天心情不错,打开熟悉的网站,上面出现了应接不暇的美丽小姐姐,于是你默默的保存下来准备慢慢欣赏......
结果很快昂,你就累了。因为网站上的小姐姐实在是太多了,你一个一个的点击保存实在是太累了,而且这个过程非常的机械且无聊。
所以你放下屠刀,立地成佛,不再拘泥于世间种种红尘准备开始借助网络爬虫帮你完成这个过程。

很快啊!你眼看着自己的磁盘嗖嗖嗖的被充满,且不断地出现小姐姐。
于是你惊呼:“我学编程不就是为了这个吗?
再比如说,爬虫可以帮你在很短的时间内下载一整部小说,自动登录某平台帮你完成整点秒杀或者抢票的工作等。
所以在学习过程中,你将会越学越上头,妈妈再也不用担心我的学习!

3 爬虫的流程是怎么样的?
爬虫行为本质上来讲是代替人类检索网络上的信息,所以一个爬虫的流程和人类访问一个网站获取信息是基本上是一致的。
首先我们来看当我们要检索网络上某些信息的示意图,如下图所示:

- 明确我们的目标URL(统一资源定位系统即网址)。
- 通过我们的点击,登录或者其他操作转到网站中我们感兴趣的页面。
- 通过我们的视听系统将我们感兴趣的信息获取到大脑,然后大脑进行分析。
- 通过某种方式储存,可能是记笔记、储存到计算机等。
然后我们来看网络爬虫的工作示意图,如下图所示:

- 明确我们的目标URL。
- 爬虫将会模拟用户使用浏览器访问页面的动作,直接向服务器发送请求。
- 通过代码中的解析部分,从获取到的页面源代码中提取到我们感兴趣的信息。
- 以某种方式直接存储到计算机上。
当然,上述过程都需要借助工具帮助我们完成。
接下来我们就步入正题聊一聊编写一个简单的爬虫需要了解哪些知识。

4 编写爬虫都需要熟悉哪些基础理论以及工具?
4.1 理论
(接下来我也会在博文中更新相关爬虫需要的零散理论知识整理,敬请期待...)
4.1.1 HTML
作为web前端开发最重要的一部分,在爬虫中我们也需要对其有或多或少的了解。
在爬虫的过程中,我们需要编写相关的解析函数来帮助我们解析获取到的源页面。这是我们就需要掌握一些相关的HTML知识来帮助我们快速获取到我们需要的信息。
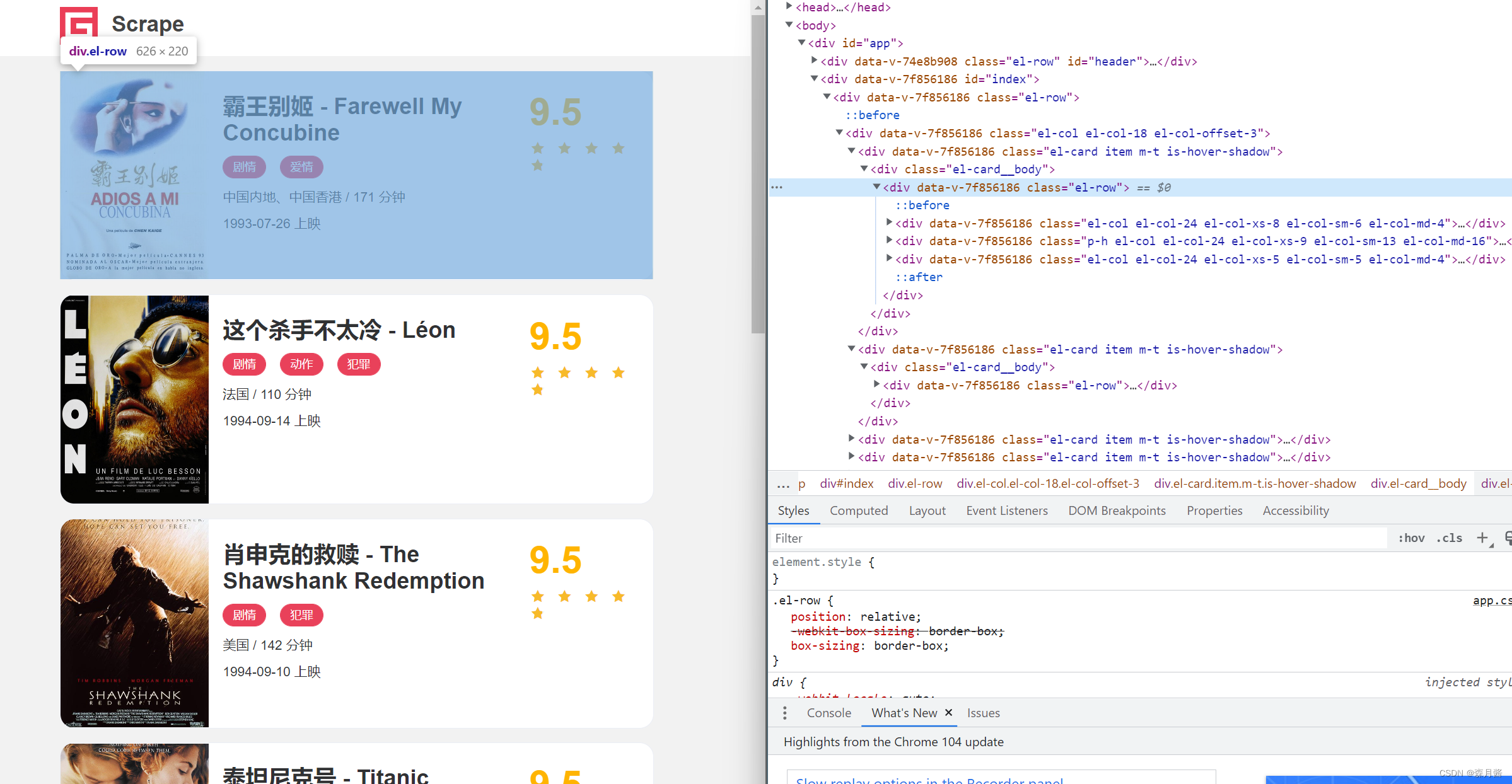
(上图节选自【建议收藏】python爬虫你能过几关?Scrape Center系列(一)
)
4.1.2 javascript
当我们需要进阶爬虫时,可能就会需要相关的javascript知识应对一些特殊的加密机制。
4.1.3 CSS
了解CSS能够更快的学习一些相关的解析库,能够帮我们更好的理解web网页的结构。4
4.1.4 数据库
当我们的爬取数据量达到一定的规模时,本地的存储已经不足以满足我们的要求。此时我们就需要一些相关数据库的知识来帮助我们存储我们的信息等。
待补充...
4.2 工具
4.2.1 抓包工具
上面说到爬虫本质上是模拟我们使用浏览器时对服务器发送请求,所以我们就需要一款抓包工具来帮助我们获取到真实的人与服务器交互的相关信息,帮助爬虫更好的模拟这个过程。
抓包工具有非常多种,例如Flidder,Hping等数不胜数。
但是不用担心,大部分的浏览器也内置了抓包的功能,虽然有时候不是那么好用,但是作为入门学习完全足够我们尽情冲浪。
在这里推荐使用谷歌浏览器进行抓包,原因是使用的人非常多,并且界面清晰简单。

4.2.2 Python相关
首先我们要掌握的就是python语言的使用,当然并不是只有python语言才能够编写爬虫。
Python上手快,语法简单,并且支持很多请求库以及解析库,所以我们选择Python作为我们编写爬虫的编程语言。
首先我们需要掌握Python的基本语法,这里给大家推荐两个学习Python的网站:
在了解了基础语法之后,我们还需要了解相关的库来帮助我们完成很多需求。
- 请求库:urllib、requests等
- 解析库:beautifulsoup、xpath、re等
- 其它:文件存储相关库,selenium、pyspider框架、Scrapy框架等
当然如果有特殊的需求我们还需要掌握一些下游的数据分析库,例如Pandas、numpy等数据分析库。
虽然写好一个爬虫需要掌握的知识很多很多,但是入门爬虫并不需要一下子完全都掌握,一步一个脚印慢慢学习,才能够达到我们最终的目标。
(接下来我也会在博文中更新相关爬虫需要的基础库的保姆级讲解,所以点关注不迷路吼!)
3 总结
工欲善其事,必先利其器。
我们本次总结了完成一个爬虫所需要的理论知识与工具,以及爬虫的基本概念。
在下一节中我将会直接和大家完成一个基础爬虫,更详细的了解这些流程在代码中的组成成分。
如果你有任何问题都可以在评论区交流或者私信我,我将会第一时间回复你。
如果觉得本文对你有帮助,希望你给我一个关注点赞或者收藏留言转发,这将是我最大的动力!

持续更新中...