环境
python:3.7.4
python库:requests-html(该库集成了requests和html解析的相关库,还加入了js渲染)
requests-html教程: https://www.jianshu.com/p/72a1f57b333a
requests-html官方文档: https://cncert.github.io/requests-html-doc-cn/
IDE:pycharm2019.3版本(社区版也可以,可能跟我的教程图片有出入)
浏览器:Chrome最新版
抓包工具:Fiddler最新版
教程
注:第一篇教程主要是了解一下需要哪些环境,环境方面的知识会比较啰嗦一点
一、开发工具准备
首先pycharm创建一个项目

接着创建一个python文件名字为Crawler.py
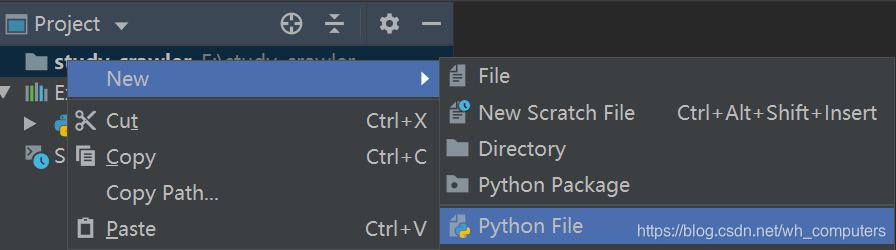
下载需要的requests-html库,pycharm选择左上角的 File->Settings,选择Project Interpreter(我的已经安装过了,所以会显示很多库,正常安装完python只有两个库)

先点击右上角的 "+" 下载requests-html库,下载之前先设置一下镜像源,加快下载速度

点击Manage Repositories,我这里设置了阿里和清华两个镜像源
阿里源:http://mirrors.aliyun.com/pypi/simple/
清华源:https://pypi.tuna.tsinghua.edu.cn/simple/
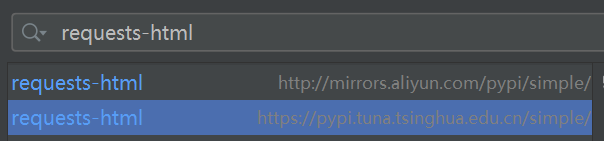
下面搜索并安装requests-html,点击左下角的Install Package,如果下载失败需要手动安装
二、Chrome调试工具准备
F12就可以进入chrome开发者模式
网址是 https://movie.douban.com/chart
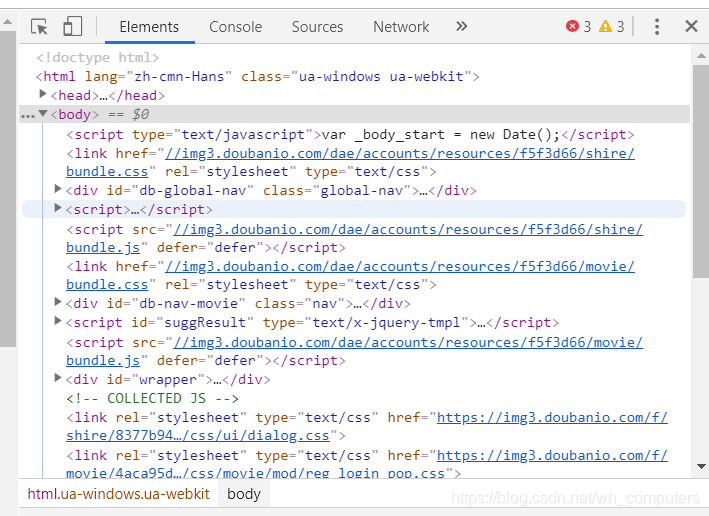
左上角的小箭头点击然后点击页面就可以看到对应地方的html代码
Elements是页面的HTML代码
Sources是加载页面各个部分的源码
Network可以查看页面的http请求
一般常用的就是Elements和Network
chrome开发者模式详解: https://www.cnblogs.com/xiaowenshu/p/10450848.html
三、Fiddler使用说明
首先下载安装Fiddler最新版
注: 使用Fiddler抓包的时候不能使用浏览器代理,不然会抓不到包
打开Fiddler后需要设置一下才能抓HTTP包
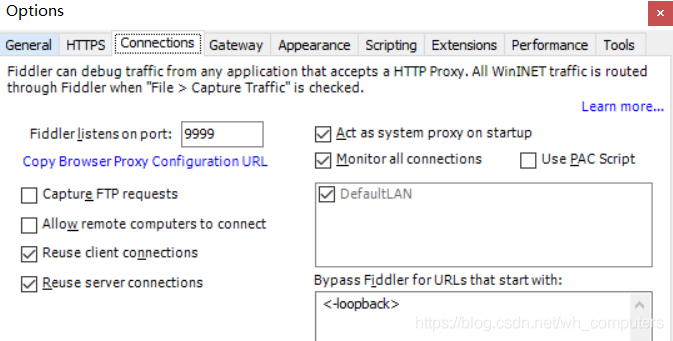
打开Tools->Options->HTTPS

选择Decrypt HTTPS traffic时会弹出安装证书的提示框,选择yes即可
最后设置一下Fiddler的端口,不要和已有的应用冲突即可,默认是8888
设置完了需要重启Fiddler,访问浏览器的时候就可以看到左边的抓取的HTTP数据包
以上只是介绍一下以后会用到的工具,不需要特别学习,后面用到的时候自然会明白怎么用的
下一节开始学习简单的爬虫
