在卷积神经网络中,我们经常会碰到池化操作,而池化层往往在卷积层后面,通过池化来降低卷积层输出的特征向量,同时改善结果(不易出现过拟合)。
为什么可以通过降低维度呢?
因为图像具有一种“静态性”的属性,这也就意味着在一个图像区域有用的特征极有可能在另一个区域同样适用。因此,为了描述大的图像,一个很自然的想法就是对不同位置的特征进行聚合统计,例如,人们可以计算图像一个区域上的某个特定特征的平均值 (或最大值)来代表这个区域的特征。[1]
1. 一般池化(General Pooling)
池化作用于图像中不重合的区域(这与卷积操作不同),过程如下图。
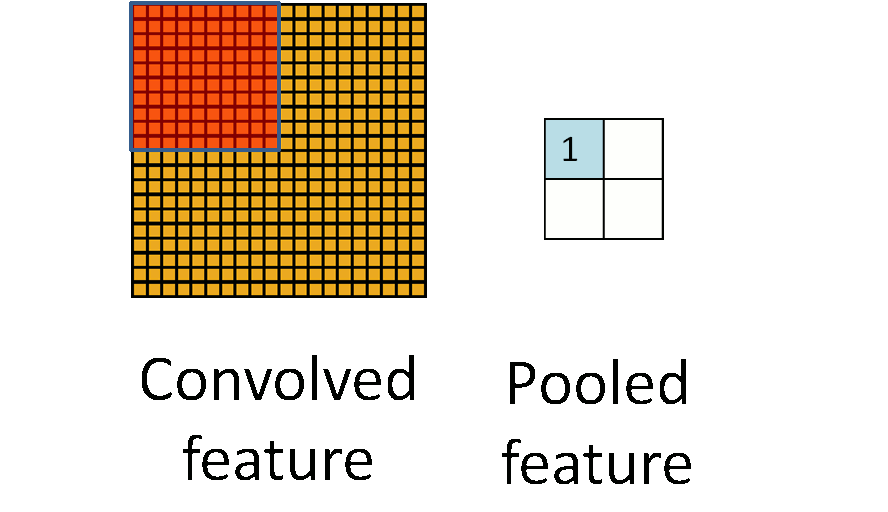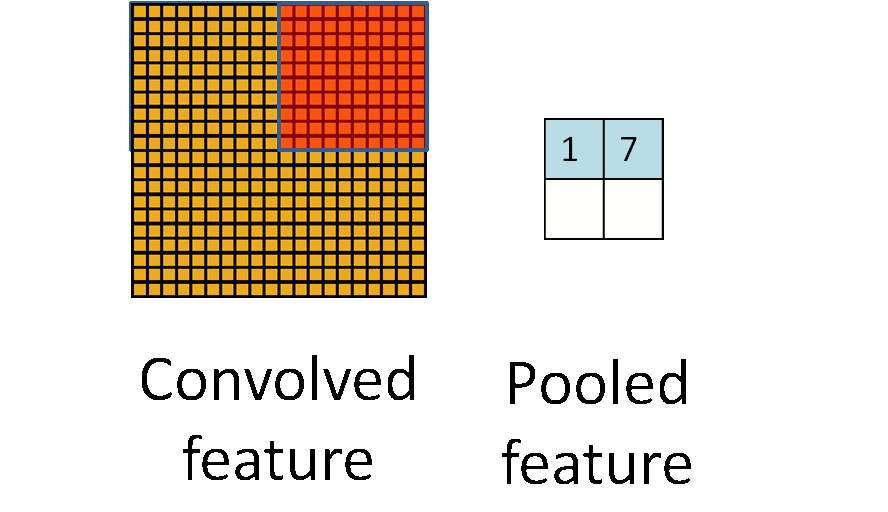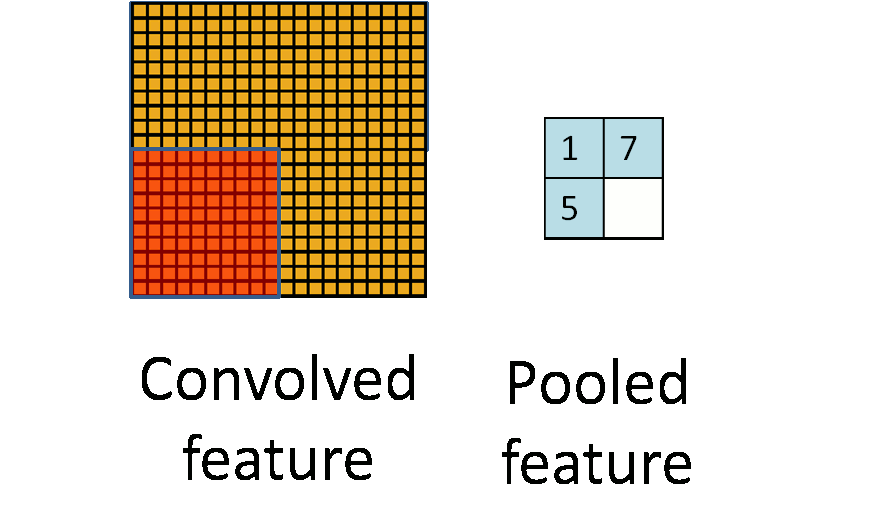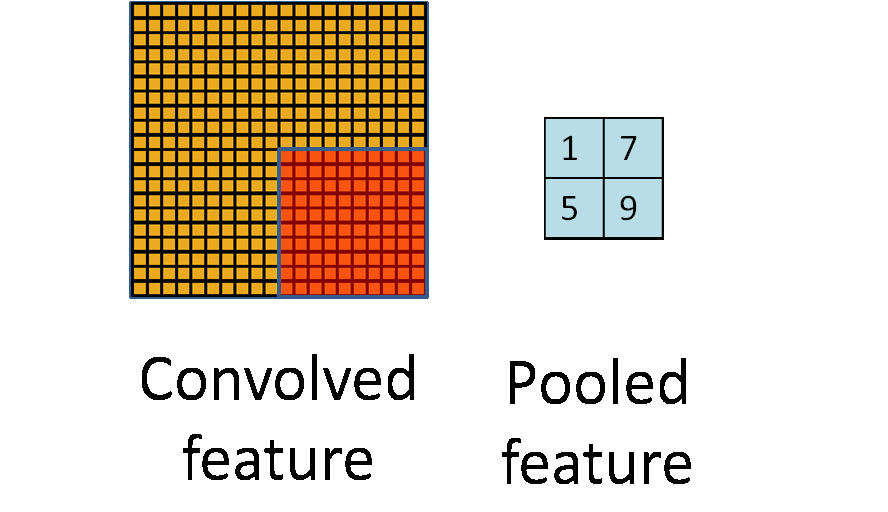
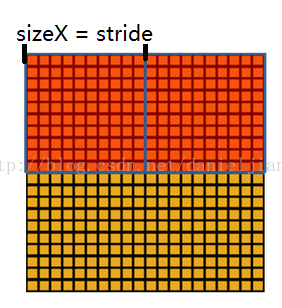
我们定义池化窗口的大小为sizeX,即下图中红色正方形的边长,定义两个相邻池化窗口的水平位移/竖直位移为stride。一般池化由于每一池化窗口都是不重复的,所以sizeX=stride。
最常见的池化操作为平均池化mean pooling和最大池化max pooling:
平均池化:计算图像区域的平均值作为该区域池化后的值。
最大池化:选图像区域的最大值作为该区域池化后的值。
2. 重叠池化(OverlappingPooling)[2]
重叠池化正如其名字所说的,相邻池化窗口之间会有重叠区域,此时sizeX>stride。论文中[2]中,作者使用了重叠池化,其他的设置都不变的情况下, top-1和top-5 的错误率分别减少了0.4% 和0.3%。
3. 空金字塔池化(Spatial Pyramid Pooling)[3]
空间金字塔池化可以把任何尺度的图像的卷积特征转化成相同维度,这不仅可以让CNN处理任意尺度的图像,还能避免cropping和warping操作,导致一些信息的丢失,具有非常重要的意义。
一般的CNN都需要输入图像的大小是固定的,这是因为全连接层的输入需要固定输入维度,但在卷积操作是没有对图像尺度有限制,所有作者提出了空间金字塔池化,先让图像进行卷积操作,然后转化成维度相同的特征输入到全连接层,这个可以把CNN扩展到任意大小的图像。

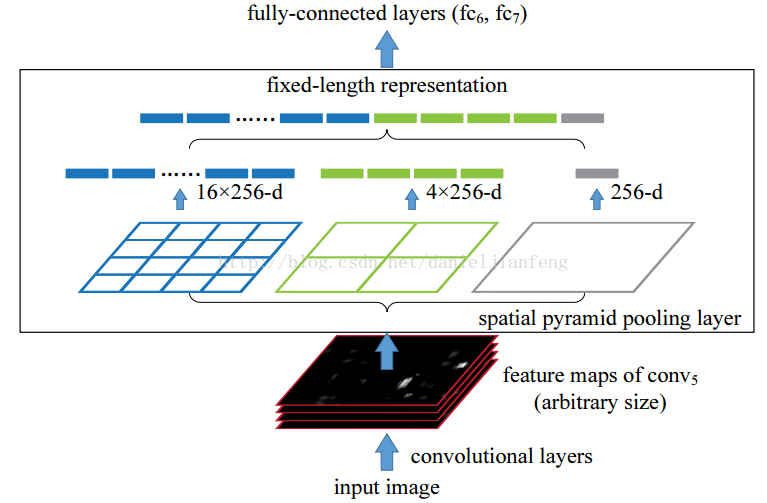
空间金字塔池化的思想来自于Spatial Pyramid Model,它一个pooling变成了多个scale的pooling。用不同大小池化窗口作用于卷积特征,我们可以得到1X1,2X2,4X4的池化结果,由于conv5中共有256个过滤器,所以得到1个256维的特征,4个256个特征,以及16个256维的特征,然后把这21个256维特征链接起来输入全连接层,通过这种方式把不同大小的图像转化成相同维度的特征。
对于不同的图像要得到相同大小的pooling结果,就需要根据图像的大小动态的计算池化窗口的大小和步长。假设conv5输出的大小为a*a,需要得到n*n大小的池化结果,可以让窗口大小sizeX为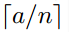
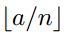

疑问:如果conv5输出的大小为14*14,[pool1*1]的sizeX=stride=14,[pool2*2]的sizeX=stride=7,这些都没有问题,但是,[pool4*4]的sizeX=5,stride=4,最后一列和最后一行特征没有被池化操作计算在内。
SPP其实就是一种多个scale的pooling,可以获取图像中的多尺度信息;在CNN中加入SPP后,可以让CNN处理任意大小的输入,这让模型变得更加的flexible。
4. Reference
[1] UFLDL_Tutorial
[2] Krizhevsky, I. Sutskever, andG. Hinton, “Imagenet classification with deep convolutional neural networks,”in NIPS,2012.
[3] Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Su,Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition,LSVRC-2014 contest