MobileNeXt:Rethinking Bottleneck Structure for Efficient Mobile Network Design(重新思考高效移动网络设计的瓶颈结构)
摘要
倒残差块是近年来移动网络体系结构设计的主流。它通过引入两个设计规则改变了传统的残差瓶颈:学习反向残差和使用线性瓶颈。
在本文中,我们重新思考了这种设计变更的必要性,并发现它可能会带来信息丢失和梯度混淆的风险。因此,我们建议翻转结构并提出一种新的瓶颈设计,称为沙漏块,它在更高的维度上执行身份映射和空间变换,从而有效地减少信息丢失和梯度混淆。大量的实验表明,与一般的看法不同,这种瓶颈结构比倒置的结构对移动网络更有利。在ImageNet分类中,通过简单地将倒置的残差块替换为我们的沙漏块,而无需增加参数和计算,分类精度可以比MobileNetV2提高1.7%以上。在Pascal VOC 2007测试集上,我们观察到目标检测也有0.9%的mAP改进。
code:https://github.com/zhoudaquan/rethinking_bottleneck_design
1 Introduction
总之,我们在本文中做出了以下贡献:
- 我们的研究结果倡导对移动网络设计的瓶颈结构进行重新思考。倒置残差似乎不像通常认为的那样优于瓶颈结构。
- 我们的研究表明,沿着高维特征空间构建快捷连接可以提高模型性能。此外,深度卷积应该在高维空间中进行,以学习更具表现力的特征,学习线性残差对于瓶颈结构也是至关重要的。
- 基于我们的研究,我们提出了一种新的sandglass block,它大大扩展了传统的瓶颈结构。
2 Related Work
3 Method
3.1 Preliminaries
具有Bottleneck的残差结构:
如图2(a)所示,由两个1×1卷积层组成,分别用于通道缩减和扩展,其中一个3×3卷积层用于空间信息编码。尽管这种传统的瓶颈结构在重量级网络设计中取得了成功,但由于其在标准3×3卷积层中的大量参数和计算成本,它不适合构建轻量级神经网络。
深度可分离卷积:
为了降低计算成本并提高网络效率,开发了深度可分离卷积来代替标准卷积。它由深度卷积和逐点卷积组成。由于逐点卷积和深度卷积的组合具有显著较少的参数和计算,因此在基本构造块中使用深度可分离卷积可以显著减少参数和计算成本。
我们提出的架构也采用了这种可分离卷积。
倒残差结构:
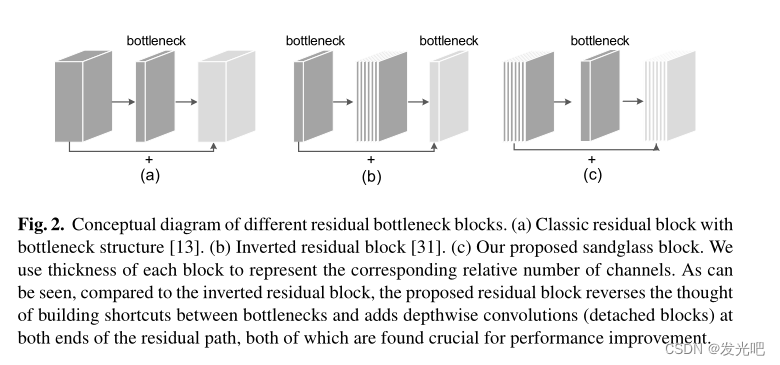
倒残差块专门为移动设备量身定制,尤其是那些计算资源预算有限的设备。更具体地说,与图2(a)所示的经典瓶颈结构不同,为了节省计算,它将低维压缩后的tensor作为输入,并通过逐点卷积将其扩展到高维张量。然后,它将深度卷积应用于空间上下文编码,然后再进行逐点卷积以生成低维特征张量作为下一块的输入。倒残差块呈现了两种不同的架构设计,以获得效率而不会遭受太多性能下降:必要时,在低维瓶颈之间放置shortcut(如图2(b)所示);并且采用线性瓶颈。
尽管性能良好,倒在残差块中,由中间扩展层编码的特征图应首先投影到低维特征图,这可能由于信道压缩而无法保留足够的有用信息。此外,最近的研究表明,更宽的架构更有利于缓解梯度混淆,因此可以提高网络性能。
瓶颈之间的shortcut可以防止来自顶层的梯度在模型训练期间被成功地传播到底层,因为相邻倒残差块之间表示的低维性。
3.2 Sandglass Block
鉴于倒残差块的上述局限性,我们重新思考了其设计规则,并提出了一种可以通过翻转倒残差块的思想来解决上述问题的Sandglass Block。
我们的设计原则主要基于以下见解:
- 为了在过渡到顶层时保留底层的更多信息,并便于梯度在层之间传播,应将shortcut定位为连接高维表示。
- 具有较小核大小(例如,3×3)的深度卷积是轻量级的,因此我们可以适当地将两个深度卷积应用到更高维的特征上,从而可以对更丰富的空间信息进行编码,以生成更具表现力的表示。我们将在下面详细阐述这些设计考虑。
- 最初,倒残差块首先进行通道扩展=张,然后进行缩减。基于上述设计原则,为了确保快捷方式连接高维表示,我们建议首先反转两个逐点卷积的顺序。
让F∈ RDf×Df×M是输入张量,G∈ RDf×Df×M是输出张量。 目前我们不考虑深度卷积和激活层。
G = φe(φr(F)) + F
其中φe和φr分别表示用于通道扩张和缩减的两个逐点卷积。这样,我们可以将bottleneck保持在残差路径的中间,以节省参数和计算成本。更重要的是,这允许我们使用shortcut表示与大量通道而不是瓶颈通道连接起来。
- 高维shortcut不是将shortcut放在瓶颈之间,而是将shortcut放置在高维表示之间,如图3(b)所示。与倒残差块相比,“更宽”的shortcut将更多信息从输入F传递到输出G,并允许更多梯度跨多个层传播。
- 逐点卷积可以用于编码通道间信息,但无法捕获空间信息。在我们的构建块中,我们遵循先前的移动网络,采用深度卷积来编码空间信息。倒残差块在逐点卷积之间添加深度卷积,以学习表达空间上下文信息。
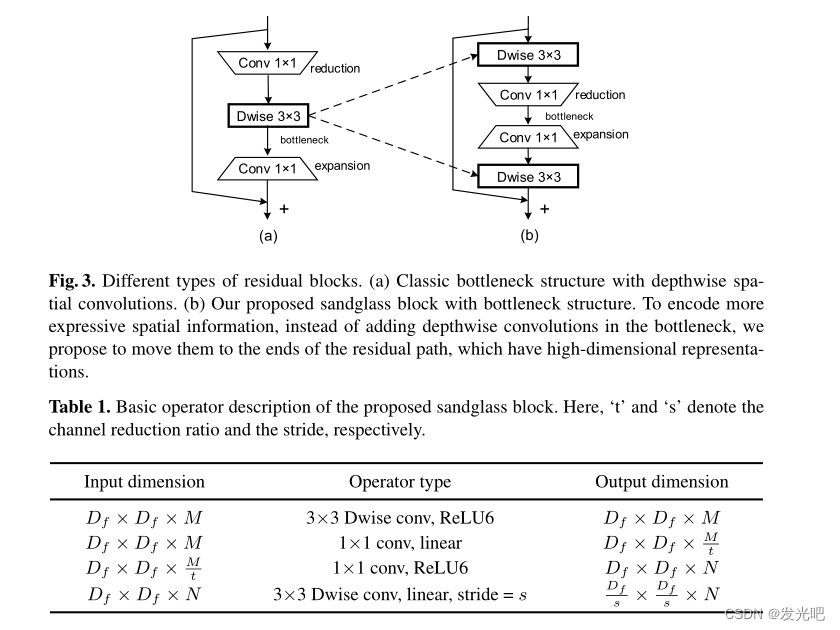
然而,在我们的例子中,两个逐点卷积之间的位置是瓶颈。如图3(a)所示,直接在瓶颈中添加深度卷积会使它们具有更少的卷积核,因此,可以编码的空间信息更少。我们通过实验发现,与MobileNetV2相比,这种结构大大降低了性能1%以上。
关于逐点卷积的位置,我们建议在剩余路径的末端添加深度卷积,而不是直接将深度卷积放在两个点卷积之间,如图3(b)所示。还应注意的是,尽管我们构建的输出是高维的,但我们根据经验发现,在最后一次卷积之后添加激活层会对分类性能产生负面影响。因此,激活层仅添加在第一个深度卷积层和最后一个点卷积层之后。我们将在这方面的实验中给出更多的解释。
Block structure
基于以上考虑,我们设计了一个新的倒残差块。表1给出了结构细节,图3(b)也给出了该图。请注意,当输入和输出具有不同的通道数时,不使用shortcut。对于深度卷积,我们总是使用核大小3×3。如果训练期间有必要,我们还利用BN和ReLU6激活函数。
Relation to the inverted and classic residual blocks
尽管这两种架构都利用了瓶颈,但设计直觉和内部结构却截然不同。我们的目标是证明,如经典瓶颈结构中那样,在高维表示之间建立shortcut的想法也适用于轻量级网络。据我们所知,这是第一次尝试研究经典瓶颈结构相对于倒残差块的优势,以实现高效网络设计。另一方面,我们还试图证明,在结构中的残差路径的末端添加深度卷积可以鼓励网络学习更多表达空间信息,从而获得更好的性能。在我们的实验部分,我们将展示更多的数值结果并提供详细的分析。
3.3 MobileNeXt Architecture
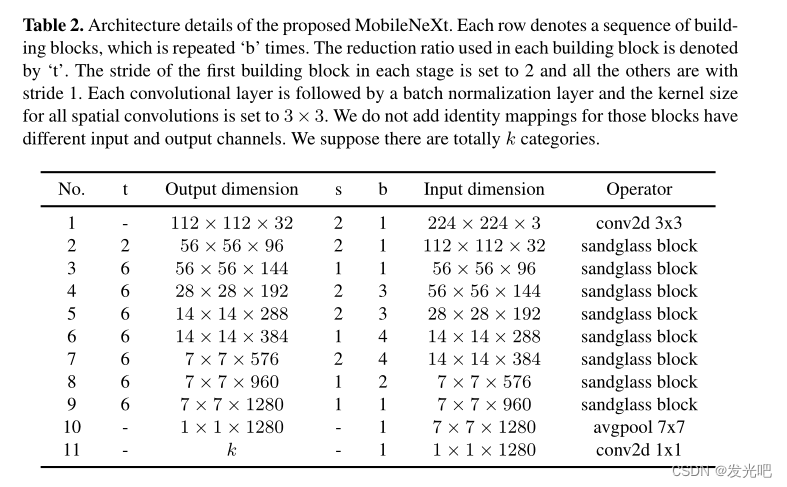
基于我们的Sandglass Block,我们开发了一个模块化架构,MobileNeXt。在我们网络的开始,有一个具有32个输出信道的卷积层。
在那之后,我们的Sandglass Block被堆叠在一起。有关网络架构的详细信息见表2。我们网络中使用的扩展率默认设置为6。最后一个构建块的输出之后是全局平均池层,以将2D特征映射转换为1D特征向量。最后添加一个全连接的层来预测每个类别的最终得分。
4 Experiments
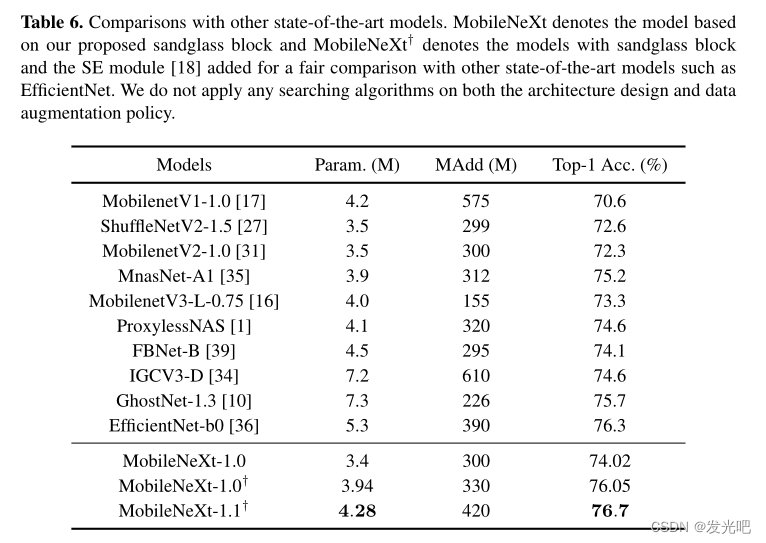
Comparisons with MobileNetV2
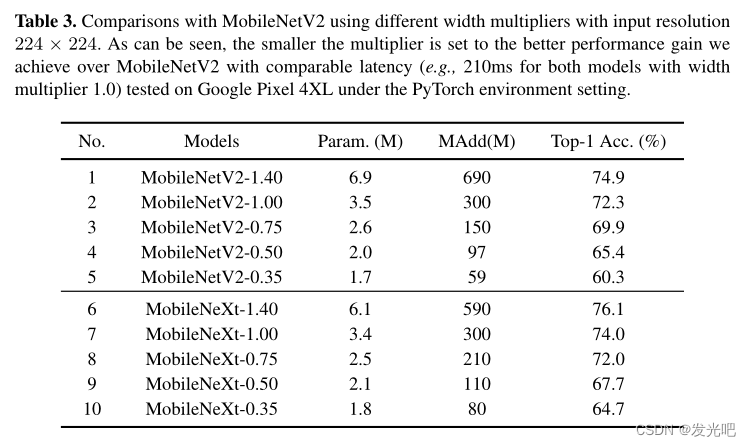
与最先进的网络相比