- 前言: …
0 Introduction

Normally, CNN now takes the form of backbone + functional head. The backbone can be replaced with each other.
1 Net Framework
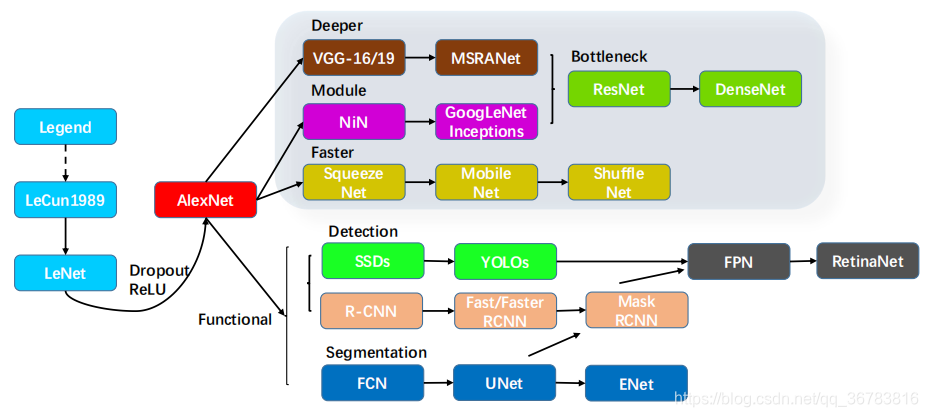

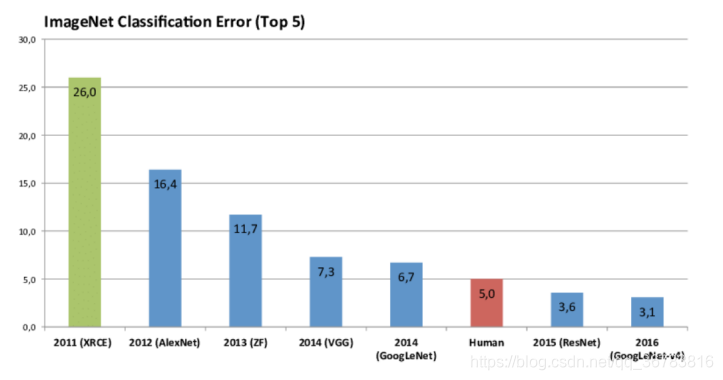
It is a very modern thing that CNN is used in CV.
In 1986, Geoffrey Hinton proposed BP algorithm. He is also the author of Dropout & Relu.
In 1989, BP algorithm was applied to Yann LeCun’s CNN network, and LeNet was proposed. Because of the lack of high-performance computing power, LeNet has not attracted people’s attention. This is also the originator of modern CNN.
In 2012, Alexnet achieved good results in the competition, so it began to be popular in the field of CV.
In 2015, ResNet was proposed, CNN times has come.
1.1 Traditional Classic Network Frameworks
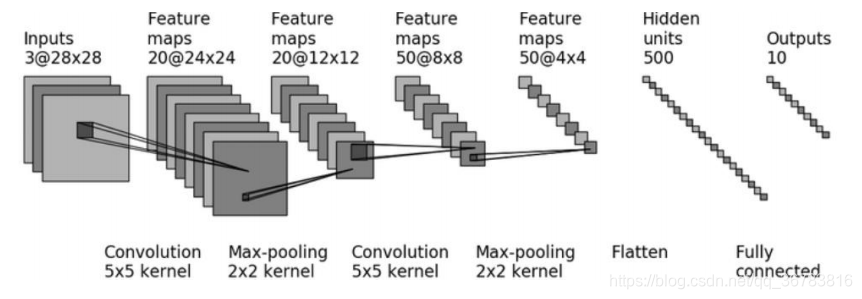
1.1.1 LeNet-5
1.1.2 AlexNet

1.1.3 ZFNet
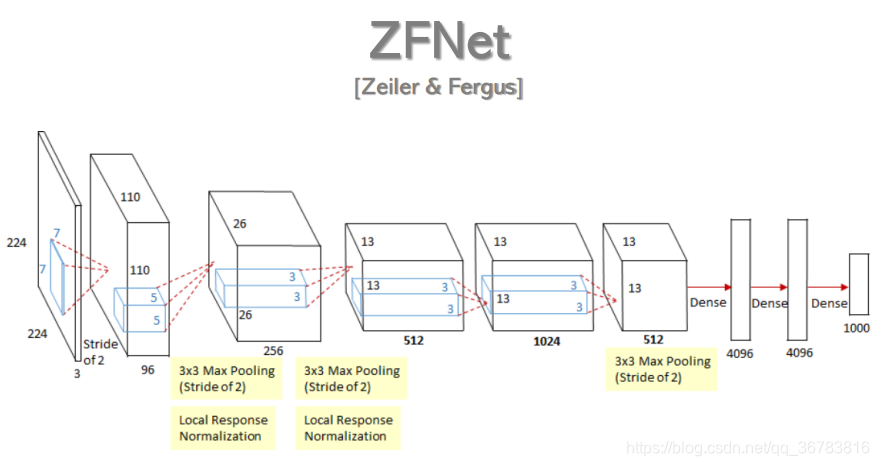
Empirrical Formula:
Input - n * (Conv - ReLU - MaxPool) - 1/2 * FC - Output
1.1.4 VggNet
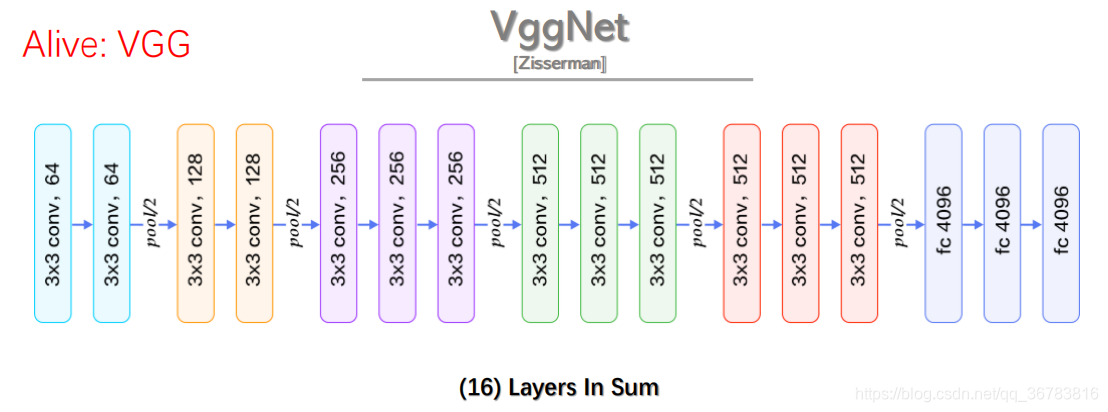
(1) Why kernel is 3*3 ?

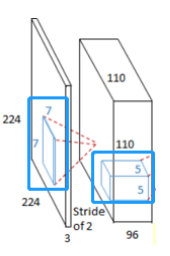
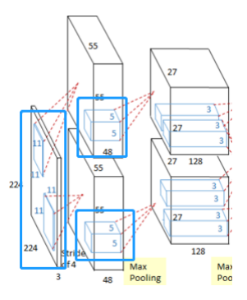
Receptive Field: The region of the input space that affects a particular unit of the network.
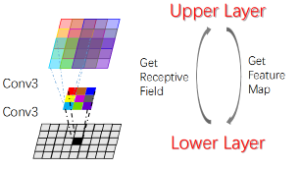

(2) Small kernel always better?
We’ll answer this in ResNet.
1.1.5 GoogLeNet
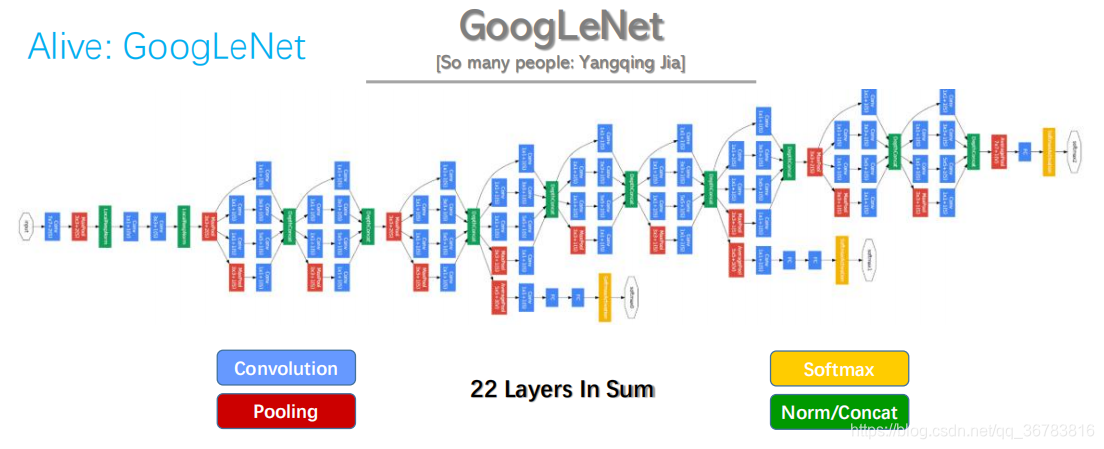
Yangqing Jia is also the author of Caffe.
GooLeNet Features:
(1) 1*1 Conv:
reduce dimensin/channel
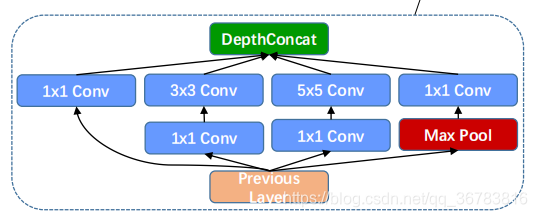
(2) Inception Module:
multiple resolution

(3) Global Ave Pool:
better result than FC
get feature vector too
replace FC
(4) Auxiliary Softmax:
weighted assemble loss
less overfit
1.1.6 ResNet-Link
1.1.7 DenseNet
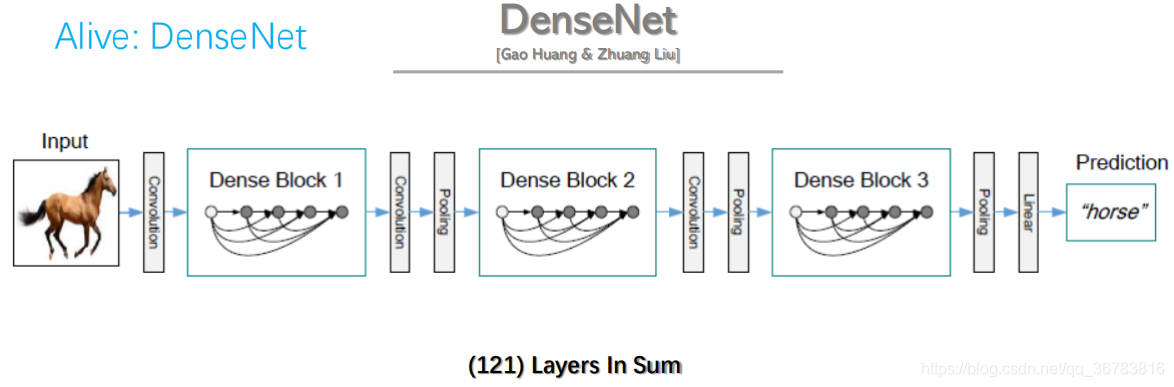
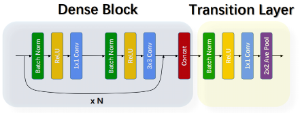
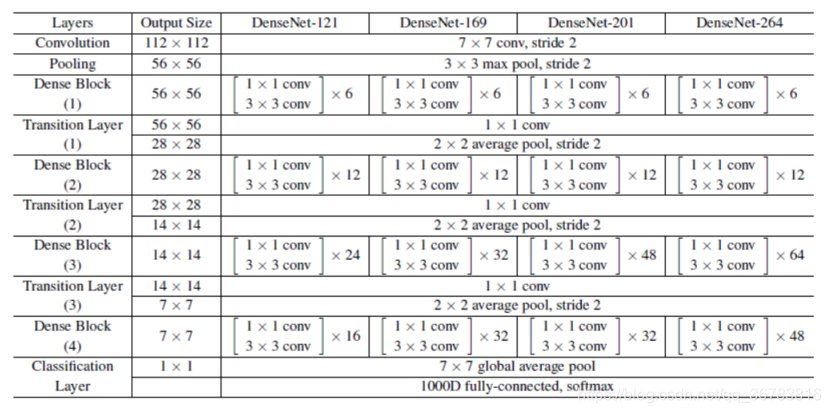
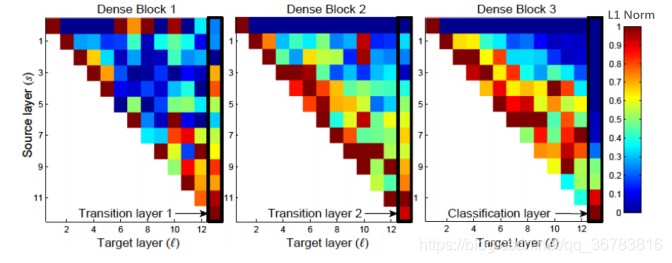
The closer the previous layer is,
The more import the layer will be,
The more uses the layer wil have.
Pros & Cons
Deeper
Fewer params
Better results
Much more memories needed
(better not try on your own devices)
[BP needs all layers output]
1.2 Light Frameworks
Problems: Too big(Memory), Too slow(Speed)
Features: Much less parameters, Much faster, Focus on end devices(i.e. no GPU, mobile phones, FPGA…)
How: Shrink the model, Change the structure

Ideas forr acceleration:
(1) Optimize net framework: Shuffle Net
(2) Decrease of parameters: Squeeze Net
(3) Optimize Conv: Order of computation: Mobile Net; Method of computation: Winograd
(4) Delete FC: Squeeze Net, LightCNN
1.2.1 SqueezeNet
Ideas(from GogLeNet):
1 Use more 11 kernel, LESS AMOUNT of 33 kernels. 1*1 can reduce the channel while maintaining the size
2 LESS CHANNEL NUMBER of 3*3 kernels. Redeuce parameters’ number directly
3 Delay to down sample(delay to use pooling). Increase visual field to get more info. A tradeoff for the less amount of parameters.
Structure-Fire Module:
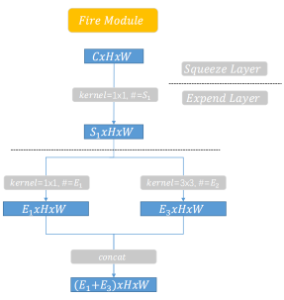
Some Details:

Sturcture-Macro:
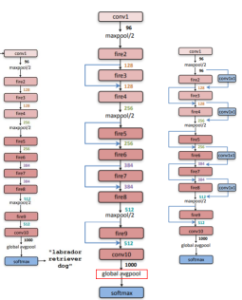
Bottleneck structure is better!
SqueezeNet accuracy and model size using different microarchitecture configurations
