简介
论文:https://arxiv.org/pdf/2305.02103.pdf
充分渲染雾场景,并从参与媒体中分解无雾背景,提出了散射体和场景物体的解纠缠表示,并学习了基于物理启发损失的场景重建

贡献点:
- 提出了一种通过在体绘制过程中引入Koschmieder散射模型来学习参与介质的解纠缠表示的方法。
- 方法增加了一个用于模拟散射介质特性的MLP,并且不需要任何额外的采样或其他程序,使其在计算和内存消耗方面都成为轻量级框架。
- 学习了基于物理的场景表示,并能够控制其模糊外观。使用在受控和野外环境中捕获的真实数据来证实这一点。
实现流程

方法和两个参考NeRF模型沿两条投射射线的射线终止分布。DS-NeRF和mip-NeRF-360中提出的正则化方法将累计透射率T表示为阶跃函数,而ScatterNeRF则对散射过程进行建模
大的散射体积可以用Koschmieder模型来近似。
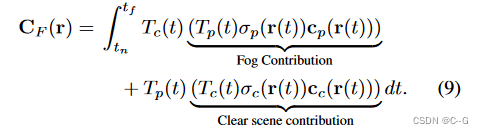
对于每个像素,建立了衰减模型,表示由于物体散射的直接光造成的损失强度,以及由于环境光散射到观察者而造成的空气光 c p c_p cp的贡献。
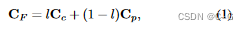
l 为透射, C F C_F CF对应观测到的像素值, C c C_c Cc为清晰场景
透射率 l 可由衰减系数 σ p σ_p σp和深度D计算得到

NeRF体渲染公式
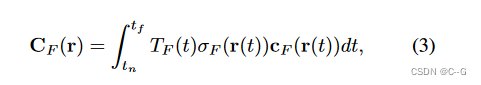

积分对象颜色 C c C_c Cc 定义为在位置 r 处发射的颜色 C c ( r ) C_c (r) Cc(r);
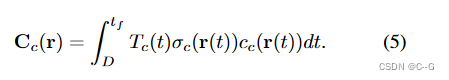
放宽对 σ p σ_p σp 和 c p c_p cp 的约束,允许它们近似任意值
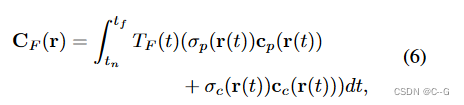
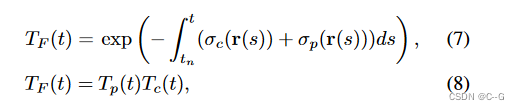
离散化表示为
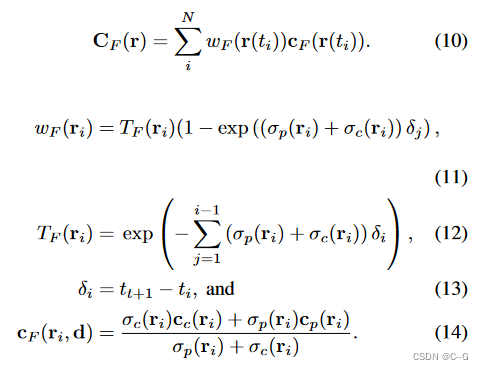
对于使用MLP得到的 σ i , c i i ∈ { c , p } \sigma_i,c_i \ i\in \{c,p\} σi,ci i∈{
c,p},可以表示为

通过缩放 σ p σ_p σp 来渲染不同雾密度的场景,甚至通过设置 σ p = 0 σ_p = 0 σp=0 来完全去雾化图像,当 σ p = 0 σ_p = 0 σp=0,渲染公式为:
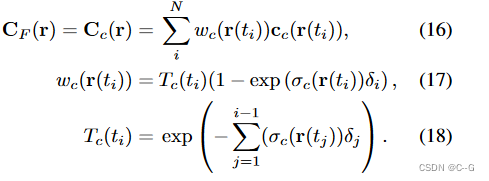
损失函数
rgb损失
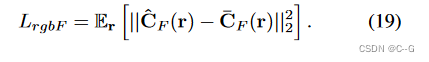
大气光颜色损失
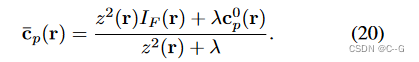
I F I_F IF 是模糊图像的相对亮度 I F ( r ) = ξ ⋅ l i n ( C ˉ F ( r ) ) I_F(r) = \xi \cdot lin(\bar{C}_F(r)) IF(r)=ξ⋅lin(CˉF(r))
c p 0 c^0_p cp0 是在暗信道先验条件下计算的初始全局恒定大气光估计值
z = 1 / ( l − 1 ) z = 1/(l-1) z=1/(l−1) λ \lambda λ 是加权因子
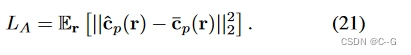
场景中投射的光线具有峰值单峰射线终止分布
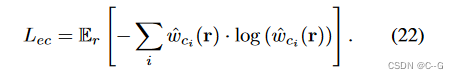
正则化散射介质 σ ^ p \hat{\sigma}_p σ^p的密度, σ ^ p \hat{\sigma}_p σ^p以半监督的方式拟合,能够模拟雾的不均匀性。应用基于熵的损失,允许网络 f p f_p fp 学习空间变化的介质密度
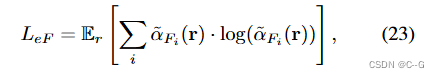
a ~ F i = a ^ F i ∑ j a ^ F j a ^ F i = 1 − e x p ( ( σ ^ p i + σ ^ c i ) δ i ) \tilde{a}_{F_i}=\frac{\hat{a}_{F_i}}{\sum_j\hat{a}_{F_j}} \hat{a}_{F_i}=1-exp((\hat{\sigma}_{p_i}+\hat{\sigma}_{c_i})\delta_i) a~Fi=∑ja^Fja^Fia^Fi=1−exp((σ^pi+σ^ci)δi)
熵最大化依赖于场景体积密度 σ ^ c \hat{σ}_c σ^c 来解开这两种分布,而不仅仅是在整个场景中分布雾体积密度 σ ^ F \hat{σ}_F σ^F。只对 σ p σ_p σp,而不是 σ c σ_c σc,最小化这个损失
深度损失
通过立体传感器设置估计的深度 D ˉ \bar{D} Dˉ来监督场景深度
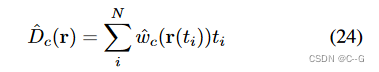
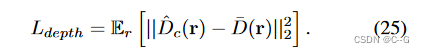
立体深度网络在大雾条件下具有鲁棒性,它们适合于直接监督场景NeRF
总损失
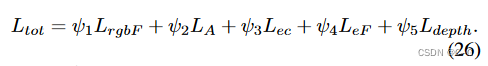
采样
由于 σ F σ_F σF在整个场景中被正则化为近似常数,重新采样过程不会使用场景权重 W F W_F WF 而是使用去雾后场景权重 W c W_c Wc
实验
使用NVIDIA RTX A6000 迭代250000次,批次大小为4096,使用Adamw优化器 β 1 = 0.9 , β 2 = 0.999 \beta_1=0.9,\beta_2=0.999 β1=0.9,β2=0.999,学习率为 5 ⋅ 1 0 − 4 5\cdot10^{-4} 5⋅10−4


