Python requests+BeautifulSoup 采集 美团_家装网_上海电话
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 美团_家装网_上海电话
# http://sh.meituan.com/jiazhuang/c20180/pn1/
# http://sh.meituan.com/jiazhuang/c20180/pn21/
# 返回请求 bsObj
def getHtmlbsObj(url):
#http请求头
Hostreferer = {
'Host':'www.meituan.com',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',
'X - Requested - With':'XMLHttpRequest'
}
# url = "https://sh.fang.anjuke.com/loupan/all/p" + str(page) + "/"
start_html = requests.get(url, headers=Hostreferer)
start_html.encoding = 'UTF-8'
bsObj = BeautifulSoup(start_html.text, "html.parser")
return bsObj
namephone = list()
def getTitleUrl(page):
url = "http://sh.meituan.com/jiazhuang/c20180/pn"+str(page)+"/"
bsObj = getHtmlbsObj(url)
# print(bsObj)
all_list_div = bsObj.find("div",{"class":"common-list-main"})
# print(all_list_div)
list_div = all_list_div.find_all("div",{"class":"abstract-desc"})
# print(list_div)
# http: // www.meituan.com / jiazhuang / 5561903 /
# // www.meituan.com / jiazhuang / 5561903 /
for item in list_div:
templist = list()
temps = item.find("a",{"class":"item-title"})
name = temps.get_text()
link = temps.get("href") #.replace('//', '')
phone = str(getUrlToPhone(link))
templist.append(name)
templist.append(link.replace('//', ''))
templist.append(phone)
namephone.append(templist)
print(name +":"+ link+":"+phone)
return namephone
def getUrlToPhone(url):
bsObj = getHtmlbsObj("http:"+url)
# print(bsObj)
phone_div = bsObj.find("div",{"class":"shop-contact telAndQQ"})
phone = 0
if phone_div != None:
phone_span = phone_div.span
if phone_span != None:
phone_span_strong = phone_span.strong
if phone_span_strong != None:
phone = phone_span_strong.get_text()
# print(phone)
else:
print("phone_span_strong is None")
else:
print("phone_span is None")
else:
print("phone_div is None")
return phone
if __name__ == '__main__':
# getTitleUrl(1)
# url = "www.meituan.com/jiazhuang/88970052/"
# getUrlToPhone(url)
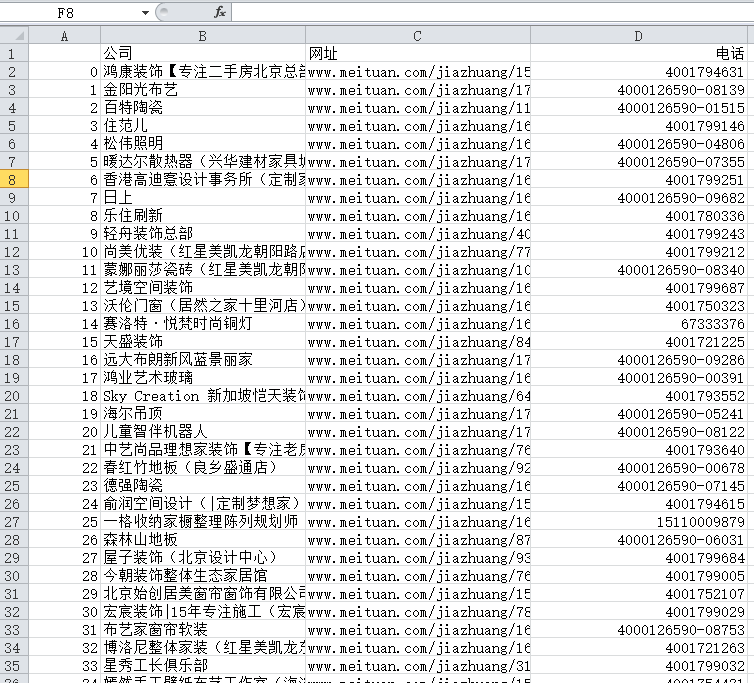
titles = ['公司', '网址', '电话']
fileName = "D:/美团_家装网_上海电话.csv"
for page in range(1, 25):
lists = getTitleUrl(page)
# print(lists)
print("写入cvs格式文件")
print(lists.__len__())
test = pd.DataFrame(columns=titles, data=lists)
test.to_csv(fileName)
print("写入cvs格式文件 成功!")