目录
任务目标
1、爬取某博正文存储于txt文件中
2、爬取博文下的评论和回复,分别存储于两个表格中,并存储主码与外码,方便后续连接
解决方案
1、从开发者工具中的抓包工具中查看json格式数据,找到存储评论数据的json文件,及目标服务器地址
2、识别下滑产生的新评论数据包与就评论数据包之间的联系
3、根据2中联系的规则,循环爬取评论
4、对于每条评论中的回复,同样识别新旧回复数据包之间联系,并依规则循环爬取
解决过程
查看目标内容
以北京头条发布的一条新闻为例:https://weibo.com/1644948230/MCH47FjIg,该博文显示有1176条评论。


获取博文内容
爬取内容之前首先需要登录(为了获取cookies),从开发者工具的网络抓包工具中找到wb正文所在的json数据包,博文全文在longtext?id=MCH47FjIg中,其中id=MCH47FjIg是博文编号。
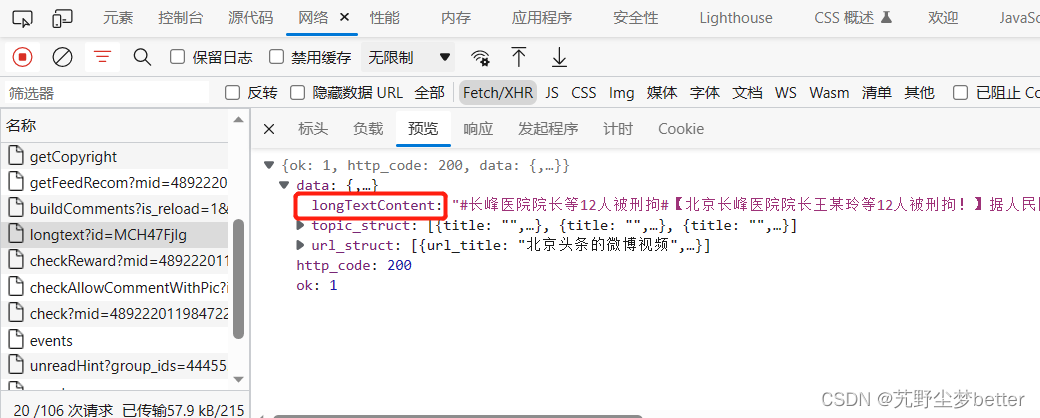
此微博由于内容长,因此全文文本放在longtext地址下,但正常博文如果不长,那么就没有longtext数据,应该从show地址中的textraw中寻找博文文本。
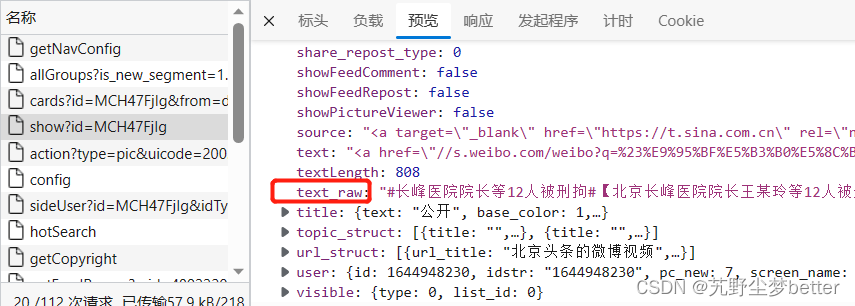
从标头headers中找到 爬取时需要构建的标头和cookies,从负载中找到需要传输的数据(可能用于作为网址中包含的参数),以下是爬取博文正文的python代码:
import requests
import json
import pandas as pd
import time
from requests.adapters import HTTPAdapter
cookies = {
"提示":"自己从网页上获取哦"
}
headers = {
#'authority': 'weibo.com',
#'method': 'GET',
#'path': '/ajax/statuses/buildComments?is_reload=1&id=4892220119847228&is_show_bulletin=2&is_mix=0&count=10&uid=1644948230&fetch_level=0',
#'scheme': 'https',
"accept": "application/json, text/plain, */*",
"accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"client-version": "v2.40.60",
"referer": "https://weibo.com/1644948230/MCH47FjIg",
"sec-ch-ua": "\"Microsoft Edge\";v=\"113\", \"Chromium\";v=\"113\", \"Not-A.Brand\";v=\"24\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"server-version": "v2023.06.02.2",
"traceparent": "00-642df2976cbf1de971f7f7c3bb7bde24-386cfa439c76373c-00",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.50",
"x-requested-with": "XMLHttpRequest",
"x-xsrf-token": "UhCx8FLK9vBWS8xrQkRQ9r56"
}
mblogid='MCH47FjIg'#博文编号
data={
'id': mblogid
}
#data = json.dumps(data)
url='https://weibo.com/ajax/statuses/show'
sessions=requests.session()
sessions.mount('https://', HTTPAdapter(max_retries=3))#最大重连次数
response =sessions.get(url,cookies=cookies, headers=headers,params=data)
#print(response.url)
blog=json.loads(response.text)['text_raw']
blog_id=json.loads(response.text)['id']#帖子编号
uid=json.loads(response.text)['user']['id']#发帖人id
blog={'正文':blog}
blog=pd.DataFrame(blog,index=[0])
print("正文爬取成功")
try:
url='https://weibo.com/ajax/statuses/longtext'
response =sessions.get(url,cookies=cookies, headers=headers,params=data)
blog_all=json.loads(response.text)['data']['longTextContent']
blog_all={'全文':blog_all}
blog_all=pd.DataFrame(blog_all,index=[0])
print("全文爬取成功")
except:
print("博文短,无展开全文")获取评论和回复内容
下面我们查看了评论数据所在的json数据,位于buildComments地址下,并发现每个json数据包可能包含数量不等的评论,从先后两个评论数据包中可以看到,上一条评论数据中包含的max_id字段的值是获取下一个评论数据包需要传输的参数,根据这个规则,我们可以循环爬取每个评论数据包。

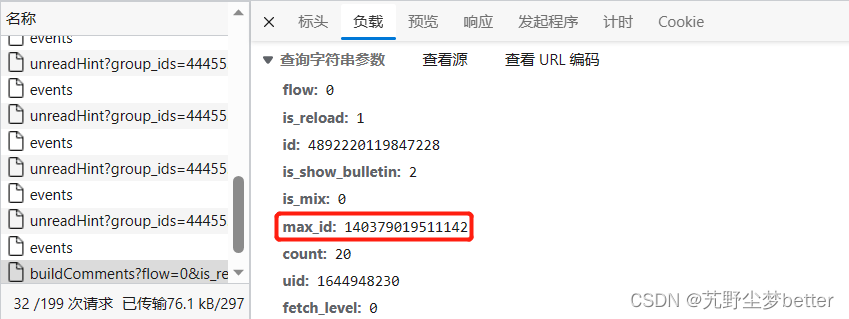
查看回复的数据,发现也位于buildComments地址下,只是需要传输的参数中包含了有一个fetch_level参数指定了层级。两个json数据包的联系和评论一样,可以从旧数据中构建新数据请求所需的参数。因此,嵌套爬取每条评论下的回复即可。
注意:
1、评论显示有1176条,但实际上并不一定有这么多,可能会被过滤掉一部分评论。
2、爬取一定数量的评论后,某博可能会将你的cookies封停一段时间,并向你报告400的错误,这段时间即使在浏览器上也刷新不出评论,因此需要暂停一段时间后继续。
3、每个博文都有自己唯一的数值型编号,每个评论和回复也有自己唯一的编号,且回复数据中包括所回复的评论的编号,保留好这些关键字段可以方便我们连接表格。
下面附上爬取评论和回复的代码:
data={
'is_reload': 1,
'id': blog_id,#帖子编号
'is_show_bulletin': 2,
'is_mix': 0,
'count': 10,
'uid': uid,
'fetch_level': 0,
}
url='https://weibo.com/ajax/statuses/buildComments'
comments_list=[]
replys_list=[]
while True:
response =sessions.get(url,cookies=cookies, headers=headers,params=data,timeout=30)
if response.status_code!=200:
print(response.status_code)
time.sleep(300)
sessions=requests.session()
response =sessions.get(url,cookies=cookies, headers=headers,params=data)
status = 1
else:
status=1
if status==1:
response=json.loads(response.text)
else:
break
comments=response['data']
total_number=response['total_number']
commentmax_id=response['max_id']
for i in range(len(comments)):
blog_ID=blog_id#帖子编号
comment_ID=comments[i]['id']#评论编号,关键属性
create_time=comments[i]['created_at']#评论创建时间
comment_like_counts=comments[i]['like_counts']#评论被赞数
comment_likedbyauthor=comments[i]['isLikedByMblogAuthor']#是否被评论作者点赞
commenter_id=comments[i]['user']['idstr']#评论者账号id
commenter_location=comments[i]['user']['location']#评论者家乡
commenter_name=comments[i]['user']['screen_name']#评论者昵称
commenter_gender=comments[i]['user']['gender']#评论者性别
commenter_ip=comments[i]['source'][2:]#评论者ip属地
#follow_me=comments[i]['user']['follow_me']#是否被作者关注
followers_count=comments[i]['user']['followers_count']#粉丝数
#following=comments[i]['user']['following']#是否关注作者
friends_count=comments[i]['user']['friends_count']#朋友数
#planet_video=comments[i]['user']['planet_video']#是否播放视频
comment_content=comments[i]['text_raw']#评论内容
reply_num=comments[i]['total_number']#回复数量
comments_list.append([blog_ID,comment_ID,create_time,comment_like_counts,comment_likedbyauthor,commenter_id,
commenter_location,commenter_name,commenter_gender,commenter_ip,
followers_count,friends_count,comment_content,reply_num])
if reply_num>0:#有回复
reply_n=1
data={
'is_reload': 1,
'id': comment_ID,#评论编号
'is_show_bulletin': 2,
'is_mix': 1,
'fetch_level': 1,
'max_id':0,
'count': 20,
'uid': uid,
}
while True:
response =sessions.get(url,cookies=cookies, headers=headers,params=data)
response=json.loads(response.text)
try:
replys=response['data']
except:
break
reply_number=response['total_number']#回复数量
replymax_id=response['max_id']
for i in range(len(replys)):
blog_ID=blog_id#帖子编号
comment_ID=replys[i]['rootid']#评论编号
reply_object_ID=replys[i]['reply_comment']['id']#回复对象编号
reply_ID=replys[i]['id']#回复编号,关键属性
create_time=replys[i]['created_at']#reply创建时间
reply_like_counts=replys[i]['like_counts']#reply被赞数
replyer_id=replys[i]['user']['idstr']#reply者账号id
replyer_location=replys[i]['user']['location']#reply者家乡
replyer_name=replys[i]['user']['screen_name']#reply者昵称
replyer_gender=replys[i]['user']['gender']#reply者性别
replyer_ip=replys[i]['source'][2:]#reply者ip属地
#follow_me=comments[i]['user']['follow_me']#是否被作者关注
followers_count=replys[i]['user']['followers_count']#粉丝数
#following=comments[i]['user']['following']#是否关注作者
friends_count=replys[i]['user']['friends_count']#朋友数
#planet_video=comments[i]['user']['planet_video']#是否播放视频
reply_content=replys[i]['text_raw']#reply内容
replys_list.append([blog_ID,comment_ID,reply_object_ID,reply_ID,create_time,reply_like_counts,replyer_id,
replyer_location,replyer_name,replyer_gender,replyer_ip,
followers_count,friends_count,reply_content])
reply_n+=1
if replymax_id<=100:
print("回复爬取完毕共{}条".format(reply_n))
break
data = {
'flow':0,
'is_reload': 1,
'id':comment_ID,#评论编号
'is_show_bulletin': 2,
'is_mix': 0,
'fetch_level': 1,
'max_id':replymax_id,
'count': 20,
'uid': uid,
}
print("爬到{}条评论了".format(len(comments_list)))
if len(comments_list)%50==0:
print("休息一会")
#time.sleep(5)
if commentmax_id<=100:
break
data = {
'flow':0,
'is_reload': 1,
'id':blog_id ,#帖子编号
'is_show_bulletin': 2,
'is_mix': 0,
'max_id':commentmax_id,
'count': 20,
'uid': uid,
'fetch_level': 0,
}
comments_data=pd.DataFrame(comments_list,columns=['博文编号','评论编号','评论创建时间','评论被赞数','是否被评论作者点赞',
'评论者账号id','评论者家乡','评论者昵称','评论者性别','评论者ip属地',
'粉丝数','朋友数','评论内容','回复数量'])
replys_data=pd.DataFrame(replys_list,columns=['博文编号','评论编号','回复对象编号','回复编号','回复创建时间','回复被赞数',
'回复者账号id','回复者家乡','回复者昵称','回复者性别','回复者ip属地',
'粉丝数','朋友数','回复内容'])