一、目标整理
今天的目标是爬取小红书上指定笔记下的所有评论数据。
以某篇举例,有2千多条评论。
以下代码,截止2023-12-01 有效。
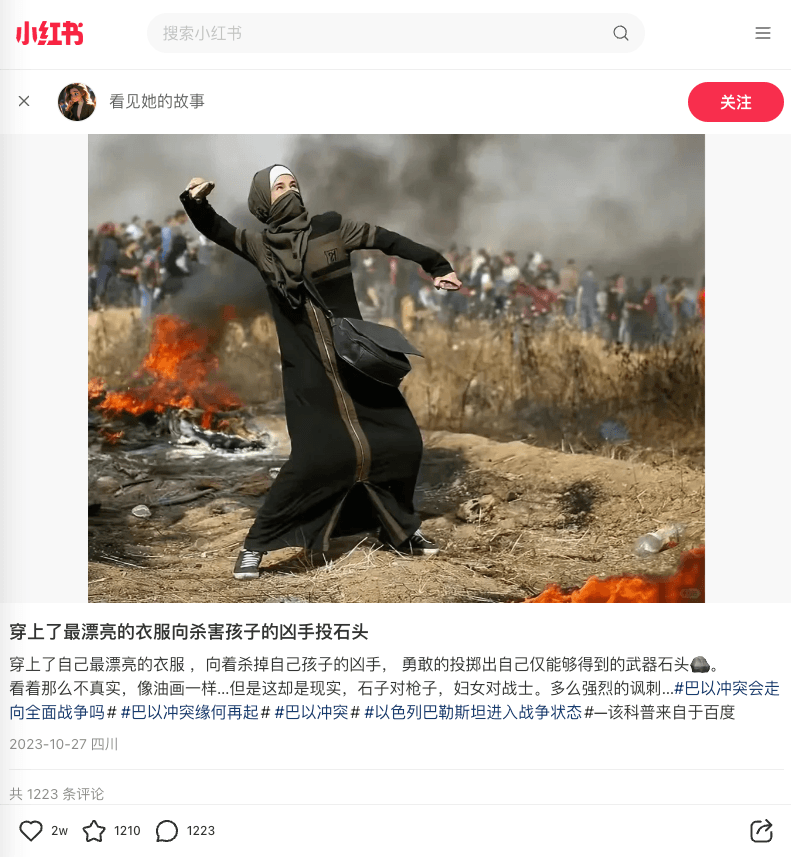
效果如下:
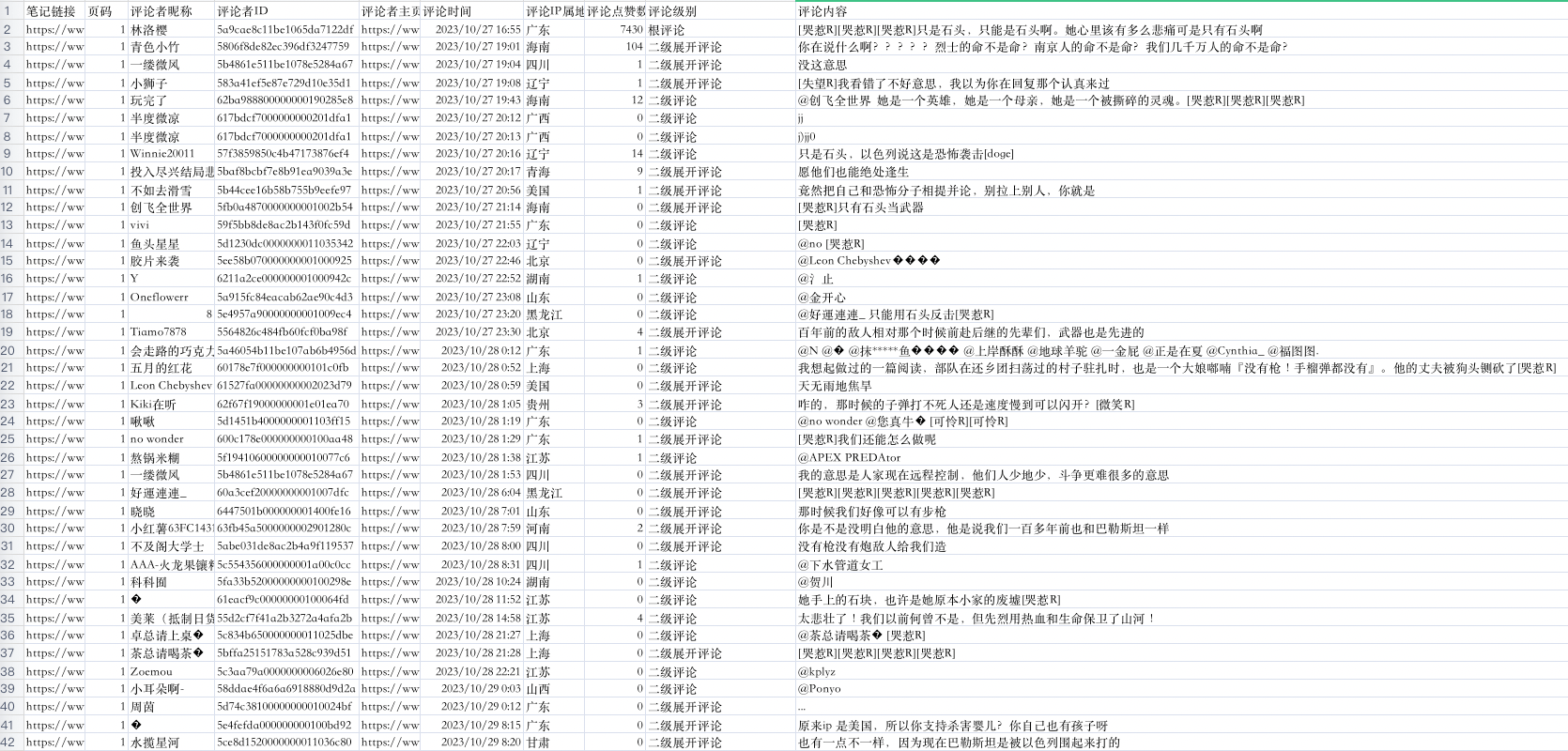
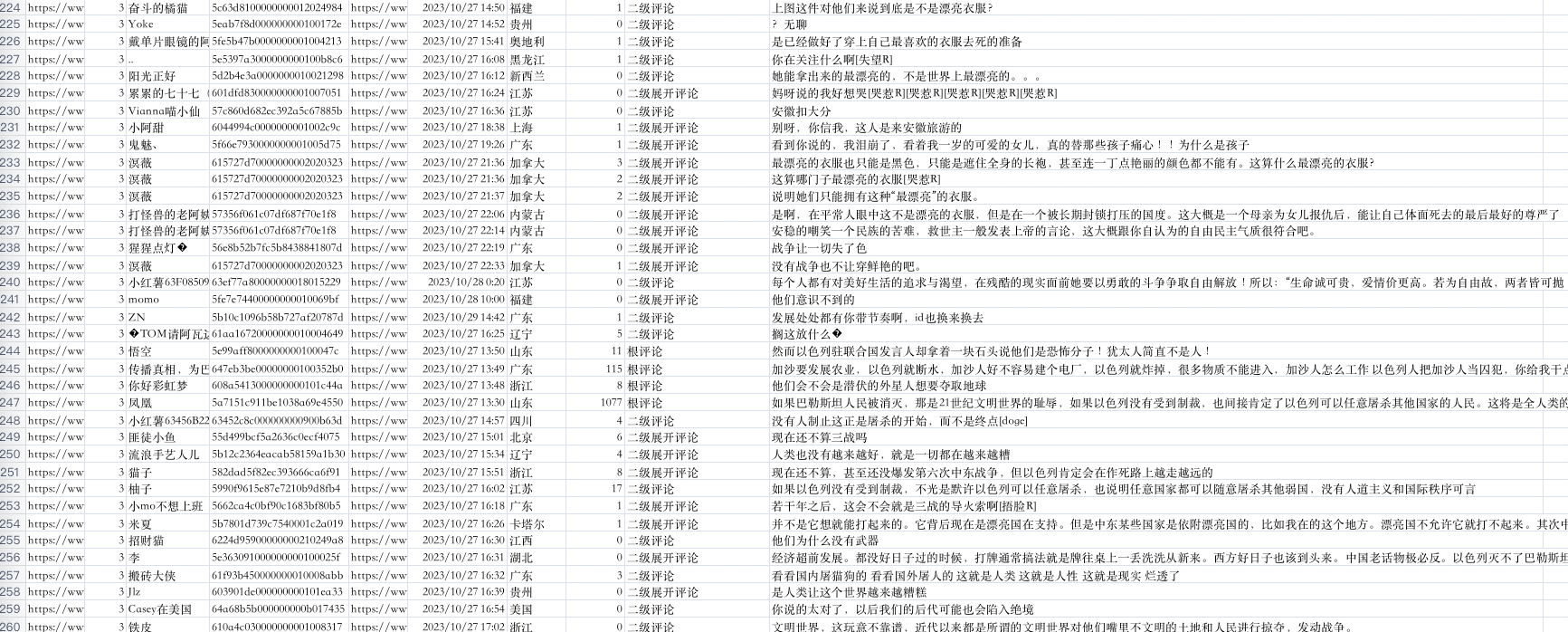
每条评论获取多个字段,
- 笔记链接
- 页码
- 评论者昵称
- 评论者ID
- 评论者主页链接
- 评论时间
- 评论IP属地
- 评论点赞数
- 评论级别
- 评论内容
而评论包含根级评论、二级评论和二级展开评论(评论回复)。
二、逻辑分析
接口分析
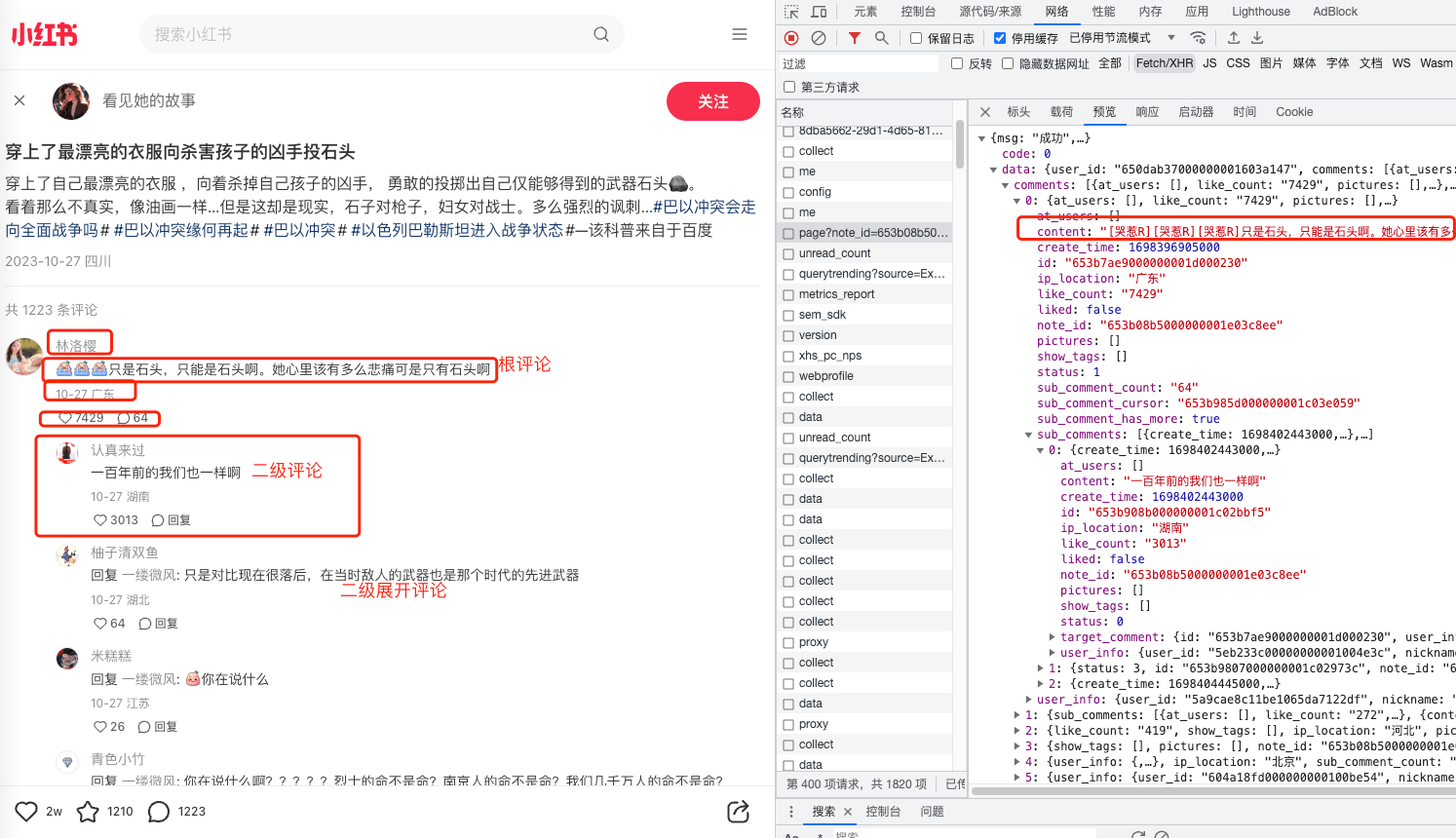
可以看到从这个接口中获取了我们想要的数据,左边是内容展示,右边是接口返回的相关字段。
请求头

# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36',
# cookie需定期更换
'Cookie': 'xxxxxx',
}
请求头这部分主要的就是UA和Cookie,其中Cookie需要定期更换,否则会出现响应数据为空的情况。
请求参数


简单说明一下这几个参数:
- note_id 这个是笔记的ID,为固定值
- cusor,获取第一页的时候可以为空,获取后面评论的时候需要使用,稍后再讲
- top_comment_id ,同样首次请求可以为空,之后才需要。
- image_scenes 固定值</