原理
HTTP基本原理
HTTP的全称是Hyper Text Transfer Protocol, 中文译名为超文本传输协议,是TCP/IP协议族的一种协议。HTTP的基础知识可以查看菜鸟课堂或者搜索查阅图解HTTP了解详细内容。
网页基础
网页可以分为三大部分一HTML , CSS 和 JavaScript 。如果把网 页 比作一个人的话 ,HTML相当于骨架,JavaScript 相 当于肌 肉 , css 相 当于皮肤,三者结合起来才能形成一个完善的网页 。
网页的基本组成
HTML
HTML 是用来描述网页的一种语言。
- HTML 指的是
超文本标记语言(Hyper Text Markup Language) - HTML 不是一种编程语言,而是一种标记语言 (markup language)
- 标记语言是一套标记标签 (markup tag)
- HTML 使用标记标签来描述网页
HTML 标记标签通常被称为 HTML 标签 (HTML tag)。
- HTML 标签是由尖括号包围的关键词,比如
<html> - HTML 标签通常是成对出现的,比如
<b>和</b> - 标签对中的第一个标签是开始标签,第二个标签是结束标签
- 开始和结束标签也被称为开放标签和闭合标签
HTML 文档 = 网页
- HTML 文档描述网页
- HTML 文档包含 HTML 标签和纯文本
- HTML 文档也被称为网页
一个基于HTML5标准的HTML文档:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
<title>Examples</title>
<meta name="description" content="">
<meta name="keywords" content="">
<link href="" rel="stylesheet">
</head>
<body>
</body>
</html>
CSS
HTML 定义了网页的结构,但是只有 HTML 页面的布局并不美观,可能只是简单的节点元素的排列,为了让网页看起来更好看一些,这里借助了css 。
CSS 指层叠样式表 (Cascading Style Sheets)。“层叠”是指当在 HTML 中引用了数个样式文件,并且样式发生冲突时,浏览器能依据层叠顺序处理 。 “样式”指网页中文字大小 、 颜色 、元素间距、排列等格式 。
css 是目前唯一 的网页页面排版样式标准,有了它的帮助,页面才会变得更为美观。样式的基本语法:选择器 {属性1:值1, 属性2:值2,...}
p
{
color:red;
text-align:center;
}
在网页中,一般会统一定义整个网页的样式规则,并写人 css 文件中(其后缀为 css )。 在 HTML中,只需要用 link标签即可引人写好的 css 文件,这样整个页面就会变得美观 、优雅 。
JavaScript
JavaScript 是世界上最流行的脚本语言。JavaScript 是属于 web 的语言,它适用于 PC、笔记本电脑、平板电脑和移动电话。JavaScript 被设计为向 HTML 页面增加交互性。
如需在 HTML 页面中插入 JavaScript,请使用 <script>标签。<script> 和</script>会告诉 JavaScript 在何处开始和结束。

<script>
alert("My First JavaScript");
</script>
由上述可知,HTML 定义了网页的内容和结构,css 描述了网页的布局, JavaScript 定义了网页的行为 。
HTML DOM
DOM 是 W3C(万维网联盟)的标准,它定义了访问 HTML 和 XML 文档的标准:
“W3C 文档对象模型 (DOM) 是中立于平台和语言的接口,它允许程序和脚本动态地访问和更新文档的内容、结构和样式。”
W3C DOM 标准被分为 3 个不同的部分:
- 核心 DOM - 针对任何结构化文档的标准模型
- XML DOM - 针对 XML 文档的标准模型
- HTML DOM - 针对 HTML 文档的标准模型
根据 W3C 的 HTML DOM 标准,HTML 文档中的所有内容都是节点:
- 整个文档是一个文档节点
- 每个 HTML 元素是元素节点
- HTML 元素内的文本是文本节点
- 每个 HTML 属性是属性节点
- 注释是注释节点
HTML DOM 定义了访问和操作 HTML 文档的标准方法。DOM 以树结构表达 HTML 文档:
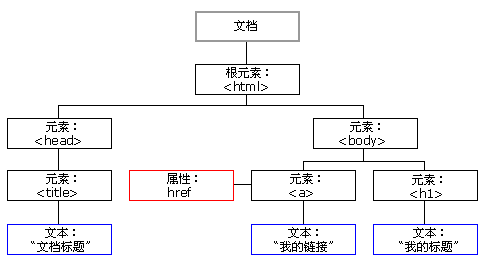
通过 HTML DOM,树中的所有节点均可通过 JavaScript 进行访问。所有 HTML 元素(节点)均可被修改,也可以创建或删除节点。
节点树中的节点彼此拥有层级关系。
父(parent)、子(child)和同胞(sibling)等术语用于描述这些关系。父节点拥有子节点。同级的子节点被称为同胞(兄弟或姐妹)。
- 在节点树中,顶端节点被称为根(root)
- 每个节点都有父节点、除了根(它没有父节点)
- 一个节点可拥有任意数量的子
- 同胞是拥有相同父节点的节点
下面的图片展示了节点树的一部分,以及节点之间的关系:
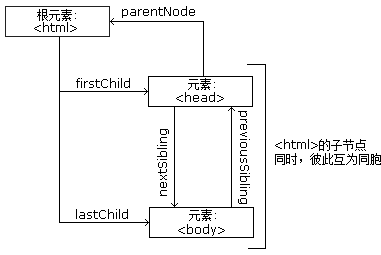
详细的HTML知识见W3school。
爬虫的基本原理
爬虫就是获取网页并提取和保存信息的自动化程序。
- 获取网页
爬虫首先要做的工作就是获取网页,这里就是获取网页的源代码。 源代码里包含了网页的部分有用信息 ,所以只要把源代码获取下来,就可以从中提取想要的信息了。向网站的服务器发送一个请求,返回的响应体便是网页源代码 。所以,最关键的部分就是构造一个请求并发送给服务器,然后接收到响应并将其解析出来。
Python 提供了许多库来帮助我们实现这个操作,如urllib、requests等 。 我们可以用这些库来帮助我们实现 HTTP 请求操作,请求和响应都可以用类库提供的数据结构来表示,得到响应之后只需要解析数据结构中的Body部分即可,即得到网页的源代码,这样我们可以用程序来实现获取网页的过程了 。 - 提取信息
获取网页源代码后,接下来就是分析网页源代码,从中提取我们想要的数据 。首先,最通用的方法便是采用正则表达式提取,这是一个万能的方法,但是在构造正则表达式时比较复杂且容易出错 。另外,由于网页的结构有一定的规则 ,所以还有一些根据 网 页节点属性、css 选择器或 XPath来提取网页信息的库,如Beautiful Soup、pyquery、lxml等 。使用这些库,我们可以高效快速地从中提取网页信息,如节点的属性 、文本值等 。 - 保存数据
提取信息后,我们一般会将提取到的数据保存到某处以便后续使用 。 这里保存形式有多种多样,如可以简单保存为 TXT 文本或 JSON 文本,也可以保存到数据库,如 MySQL 和 MongoDB 等,也可保存至远程服务器。 - 自动化程序
说到自动化程序,意思是说爬虫可以代替人来完成这些操作。首先,我们手工当然可以提取这些信息,但是当量特别大或者想快速获取大量数据的话,肯定还是要借助程序 。爬虫就是代替我们来完成这份爬取工作的自动化程序,它可以在抓取过程中进行各种异常处理、错误重试等操作 ,确保爬取持续高效地运行。
爬虫抓取的数据
在网页中我们能看到各种各样的信息,最常见的便是常规网页,它们对应着 HTML 代码,而最常抓取的便是 HTML 源代码 。另外,可能有些网页返回的不是HTML 代码,而是一个 JSON 字符串(其中 API 接口大多采用这样的形式) ,这种格式的数据方便传输和解析,它们同样可以抓取,而且数据提取更加方便 。
此外,我们还可以看到各种二进制数据,如图片 、视频和音频等 。利用爬虫,我们可以将这些二进制数据抓取下来,然后保存成对应的文件名 。
另外,还可以看到各种扩展名的文件,如 css 、JavaScript 和配置文件等,这些其实也是最普通的文件,只要在浏览器里面可以访问到,就可以将其抓取下来 。
上述内容其实都对应各自的 URL , 是基于 HTTP或HTTPS协议的,只要是这种数据,爬虫都可以抓取 。
JavaScript渲染的页面
有时候,我们在用urllib或requests抓取网页时,得到的源代码实际和浏览器中看到的不一样 。这是一个非常常见的问题 ,现在网页越来越多地采用 Ajax 、前端模块化工具构建,整个网页可能都是由 JavaScript 渲染出来的。在用使用urllib或 requests等库请求当前页面时,我们得到的只是这个 HTML 代码,它不会帮助。
我们去继续加载这个JavaScript 文件,这样也就看不到浏览器中的内容了。对于这样的情况,我们可以分析其后台 Ajax 接口,也可使用 Selenium 、 Splash这样的库来实现模拟 JavaScript 渲染。
会话和Cookies
静态网页和动态网页
上面提到的标准的HTML文档:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
<title>Examples</title>
<meta name="description" content="">
<meta name="keywords" content="">
<link href="" rel="stylesheet">
</head>
<body>
</body>
</html>
这是最基本的 HTML代码,我们将其保存为一个 .html文件,然后把它放在某台具有固定公网 IP的主机上, 主机上装上 Apache 或 Nginx 等服务器,这样这台主机就可以作为服务器了,其他人便可以通过访问服务器看到这个页面,这就搭建了一个最简单的网站 。这种网页的内容是 HTML 代码编写的,文字、图片等内容均通过写好的 HTML 代码来指定 , 这种页面叫作静态网页。它加载速度快,编写简单,但是存在很大的缺陷,可维护性差 ,不能根据URL 灵活多变地显示内容等 。例如,我们想要给这个网页的 URL 传入一个 name 参数,让其在网页中显示出来,是无法做到的。
因此,动态网页应运而生,它可以动态解析 URL 中参数的变化,关联数据库并动态呈现不同的页面内容,非常灵活多变 。我们现在遇到的大多数网站都是动态网站,它们不再是一个简单的 HTML,而是可能由 JSP、PHP、Python 等语言编写的,其功能比静态网页强大和丰富太多了 。
此外,动态网站还可以实现用户登录和注册的功能。这里就使用到了会话和Cookies。
HTTP是不保存状态的协议
HTTP 是一种不保存状态,即无状态(stateless)协议。HTTP 协议自身不对请求和响应之间的通信状态进行保存。也就是说在 HTTP 这个级别,协议对于发送过的请求或响应都不做持久化处理。

随着 Web 的不断发展,因无状态而导致业务处理变得棘手的情况增多了。比如,用户登录到一家购物网站,即使他跳转到该站的其他页面后,也需要能继续保持登录状态。针对这个实例,网站为了能够掌握是谁送出的请求,需要保存用户的状态。
这时两个用于保持 HTTP 连接状态的技术就出现了。它们分别是会话和 Cookies 。 会话在服务端,也就是网站的服务器,用来保存用户的会话信息;Cookies 在客户端,也可以理解为浏览器端,有了Cookies,浏览器在下次访问网页时会自动附带上它发送给服务器,服务器通过识别 Cookies 并鉴定出是哪个用户,然后再判断用户是否是登录状态,然后返回对应的响应 。
我们可以理解为 Cookies 里面保存了登录的凭证,有了它,只需要在下次请求携带 Cookies 发送请求而不必重新输入用户名、密码等信息重新登录了 。
因此在爬虫中,有时候处理需要登录才能访问的页面时,我们一般会直接将登录成功后获取的Cookies 放在请求头里面直接请求,而不必重新模拟登录。
会话
会话,其本来的含义是指有始有终的一系列动作/消息 。比如,打电话时,从拿起电话拨号到挂断电话这中间的一系列过程可以称为一个会话 。
而在 Web 中,会话对象用来存储特定用户会话所需的属性及配置信息。这样,当用户在应用程序的 Web 页之间跳转时,存储在会话对象中的变量将不会丢失,而是在整个用户会话中一直存在下去 。当用户请求来自应用程序的Web页时如果该用户还没有会话,则Web服务器将自动创建一个会话对象 。当会话过期或被放弃后,服务器将终止该会话 。
会话何时结束
关闭浏览器,并不意味着会话消失。除非程序通知服务器删除一个会话,否则服务器会一直保留 。比如,程序一般
都是在我们做注销操作时才去删除会话
Cookies
Cookies指某些网站为了辨别用户身份 、 进行会话跟踪而存储在用户本地终端上的数据 。
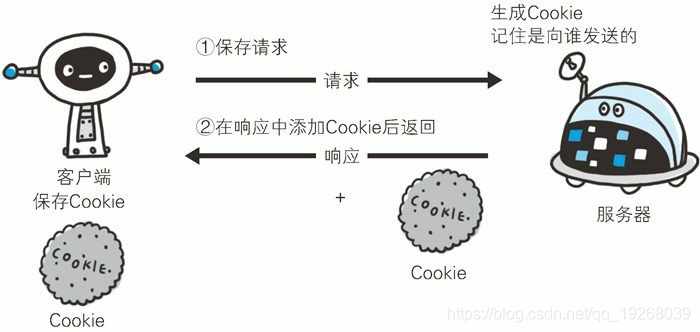
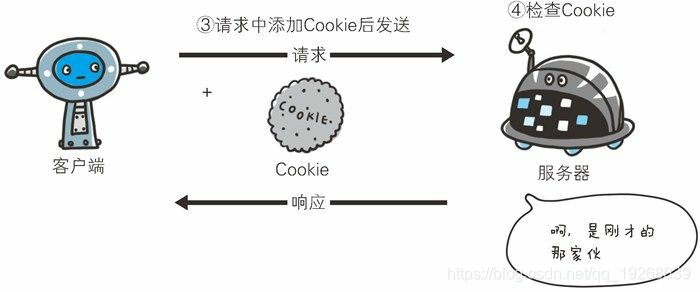
Cookie会根据从服务器端发送的响应报文内的一个叫做 Set-Cookie的首部字段信息,通知客户端保存 Cookie。当下次客户端再往该服务器发送请求时,客户端会自动在请求报文中加入 Cookie 值后发送出去。
服务器端发现客户端发送过来的 Cookie后,会去检查究竟是从哪一个客户端发来的连接请求,然后对比服务器上的记录,最后得到之前的状态信息。
-
没有Cookie下的请求:
-
第 2 次以后(存有 Cookie 信息状态)的请求:
cookie的内容
下面的表格列举了 Set-Cookie 的字段值
| 属性 | 说明 |
|---|---|
| NAME=VALUE | 赋予 Cookie 的名称和其值(必需项) |
| expires=DATE | Cookie 的有效期(若不明确指定则默认为浏览器关闭前为止) |
| path=PATH | 将服务器上的文件目录作为Cookie的适用对象(若不指定则默认为文档所在的文件目录) |
| domain=域名 | 作为 Cookie 适用对象的域名 (若不指定则默认为创建 Cookie的服务器的域名) |
| Secure | 仅在 HTTPS 安全通信时才会发送 Cookie |
| HttpOnly | 加以限制,使 Cookie 不能被 JavaScript 脚本访问 |
会话Cookie和持久Cookie
从表面意思来说。会话Cookie就是把 Cookie放在浏览器内存里,浏览器在关闭之后该 Cookie 即失效 ; 持久 Cookie 则会保存到客户端的硬盘中,下次还可以继续使用,用于长久保持用户登录状态 。
其实严格来说 ,没有会话 Cookie 和持久 Cookie 之分,只是由 Cookie的Max Age或Expires字段决定了过期的时间 。
因此,一些持久化登录的网站其实就是把 Cookie 的有效时间和会话有效期设置得比较长,下次再访问页面时仍然携带之前的Cookie,就可以直接保持登录状态。
代理
我们在做爬虫的过程中经常会遇到这样的情况 , 最初爬虫正常运行,正常抓取数据,一切看起来都是那么美好,然而一杯茶的功夫可能就会 出现错误,比如 403 Forbidden, 这时候打开网页一看 ,可能会看到“您的 IP 访问频 率太高”这样 的提示 。 出现这种现象的原因是网站采取了 一些反爬虫措施 。
比如,服务器会检测某个 IP 在单位时间内的请求次数,如果超过了这个阈值,就会直接拒绝服务,返问一些错误信息,这种情况可以称为封 IP 。
既然服务会检测的是某个 IP 单位时间的请求次数,那么借助某种方式来伪装我们的 IP ,让服务器识别不出是由我们本机发起 的请求,不就可以成功防止封 IP了吗 ?一种有效的方式就是使用代理。
代理的基本原理
代理实际上指的就是代理服务器(proxy server),是一种有转发功能的应用程序,它扮演了位于服务器和客户端中间人的角色,接收由客户端发送的请求并转发给服务器,同时也接收服务器返回的响应并转发给客户端。
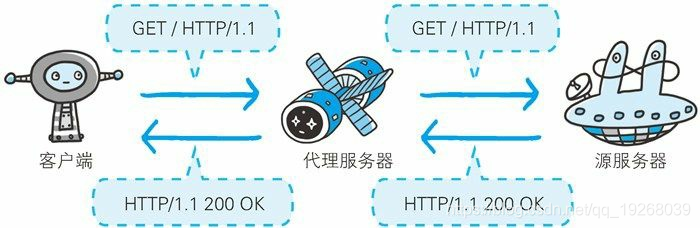
代理的作用
那么,代理有什么作用呢?我们可以简单列举如下 :
- 突破自身IP访问限制,访问一些平时不能访问的站点 。
- 访问一些单位或团体内部资源 :比如使用教育网内地址段免费代理服务器,就可以用于对教育网开放的各类 FTP 下载上传,以及各类资料查询共享等服务 。
- 提高访问速度:通常代理服务器都设置一个较大的硬盘缓冲区,当有外界的信息通过时,同时也将其保存到缓冲区中,当其他用户再访问相同的信息时,则直接由缓冲区中取出信息,传给用户,以提高访问速度 。
- 隐藏真实 IP : 上网者也可以通过这种方法隐藏向己的IP,免受攻击。对于爬虫来说,我们用代理就是为了隐藏自身的IP,防止自身的IP被封锁。