
第一章
“const”关键字的用法
当使用 const 修饰变量、函数参数、成员函数以及指针时,以下是一些代码示例:
- 声明只读变量:
const int MAX_VALUE = 100;
const float PI = 3.14;
- 保护函数参数:
void printArray(const int arr[], int size) {
// 不会修改 arr[] 中的值
for (int i = 0; i < size; i++) {
cout << arr[i] << " ";
}
}
- 防止成员函数修改对象状态:
class MyClass {
public:
void display() const {
// 不会修改对象的数据成员
cout << "Value: " << value << endl;
}
private:
int value;
};
- 防止指针修改指向的值:
void printString(const char* str) {
// 不会修改 str 指向的字符数组
cout << str << endl;
}
int main() {
const char* message = "Hello, World!";
printString(message);
}
这些示例展示了如何使用 const 关键字来声明常量、保护函数参数、防止成员函数修改对象状态以及防止指针修改指向的值。通过在适当的位置使用 const,可以提高代码的可读性,并确保数据的不可修改性。
1) 定义常量
const int MAX_VAL = 23;
const string SCHOOL_NAME = "Peking University";
1) 定义常量指针
int n,m;
const int * p = & n;
* p = 5;
n = 4;
p = &m;
1) 定义常量指针
不可通过常量指针修改其指向的内容
int n,m;
const int * p = & n;
* p = 5; //编译出错
n = 4;
p = &m;
int n,m;
const int * p = & n;
* p = 5; //编译出错
n = 4; //ok
p = &m;
35
int n,m;
const int * p = & n;
* p = 5; //编译出错
n = 4; //ok
p = &m; //ok, 常量指针的指向可以变化
不能把常量指针赋值给非常量指针,反过来可以
const int * p1; int * p2;
p1 = p2; //ok
p2 = p1; //error
p2 = (int * ) p1; //ok,强制类型转换
函数参数为常量指针时,可避免函数内部不小心改变
参数指针所指地方的内容
void MyPrintf( const char * p )
{
strcpy( p,"this"); //编译出错
printf("%s",p); //ok
}
2) 定义常引用
不能通过常引用修改其引用的变量
int n;
const int & r = n;
r = 5; //error
n = 4; //ok
const和define比较
const 和 #define 是两种不同的方式来定义常量,它们有以下几个主要区别和比较点:
-
类型安全性:
const是 C++ 中的关键字,可以将常量定义为特定的数据类型。它提供了类型安全性,编译器可以检查类型是否匹配,避免意外的数据类型错误。#define是 C/C++ 预处理指令,它只是简单的文本替换。在使用#define定义常量时,没有类型检查,可能导致潜在的类型错误。
-
作用域:
const可以被限定在特定的作用域中,例如在函数内部、类中或命名空间中。这样可以控制常量的可见范围。#define定义的常量没有作用域,会在整个文件中进行替换,可能导致命名冲突和意外的替换错误。
-
编译时计算:
const可以包含编译时计算的表达式,例如const int MAX_VALUE = 10 * 5;。#define只能进行文本替换,不支持编译时计算。
-
调试和可读性:
- 使用
const关键字定义的常量具有调试符号表信息,可以在调试器中查看它们的值。 #define定义的常量不会出现在符号表中,调试时可能不容易追踪常量值。
- 使用
综上所述,建议在 C++ 中优先使用 const 关键字来定义常量。它提供了类型安全性、作用域控制、编译时计算以及更好的可读性和调试支持。#define 主要用于定义宏,而不是常量,应该谨慎使用,并更倾向于使用 const 来定义常量。
return的用法
return 是一个用于从函数中返回值或提前结束函数执行的关键字。它有以下几种用法:
-
返回值:
- 在函数声明和定义时,可以指定函数的返回类型,并在函数体中使用
return语句返回一个值。 - 例如,在函数中进行一些计算后,使用
return将计算结果返回给调用者。
int add(int a, int b) { return a + b; } - 在函数声明和定义时,可以指定函数的返回类型,并在函数体中使用
-
提前结束函数执行:
- 在函数执行过程中,可以使用
return来提前结束函数的执行,无论是否有返回值。 - 例如,在满足某个条件时,可以使用
return来立即退出函数。
void processArray(const int arr[], int size) { for (int i = 0; i < size; i++) { if (arr[i] == 0) { return; // 满足条件则提前结束函数执行 } // 继续处理数组元素... } } - 在函数执行过程中,可以使用
-
返回引用类型(C++):
- 在 C++ 中,除了返回基本数据类型和自定义类型的值外,还可以返回引用类型。
- 通过返回引用,可以将函数的返回值作为左值使用,并修改原始变量的值。
int& getValue(int& num) { return num; // 返回 num 的引用 } int main() { int x = 5; getValue(x) = 10; // 将返回的引用作为左值,修改 x 的值为 10 cout << x; // 输出:10 return 0; }
无论在何种情况下,return 关键字可用于结束函数的执行,并将控制权返回给调用者。在编写函数时,请确保符合函数定义的返回值类型,并根据需要使用 return 引导函数的流程。
当涉及到 return 关键字时,还有一些注意事项和用法需要了解:
-
在
void函数中的使用:void函数指的是没有返回值的函数。在这种情况下,return可以被用来显式地提前结束函数的执行,不带任何返回值。
void printMessage() { cout << "Hello, world!" << endl; return; // 提前结束函数执行 cout << "This line will not be executed."; } -
函数的多个返回点:
- 函数可以在多个位置使用
return关键字来返回不同的值。根据条件或逻辑需求,可以通过多个返回点来提高代码的可读性和灵活性。
int getMax(int a, int b) { if (a > b) { return a; } else { return b; } } - 函数可以在多个位置使用
-
返回数组或指针:
- 在函数中,可以使用
return关键字返回指向数组或指针的指针。但要注意,在返回指向局部变量的指针时,必须非常小心,以避免返回无效的指针。
int* createArray(int size) { int* arr = new int[size]; // 初始化数组... return arr; } void deleteArray(int* arr) { delete[] arr; } - 在函数中,可以使用
-
在循环中使用
return:- 在循环中使用
return可以提前结束循环并返回函数。 - 例如,在查找特定元素时,可以在找到元素后立即使用
return结束循环。
bool containsValue(const int arr[], int size, int value) { for (int i = 0; i < size; i++) { if (arr[i] == value) { return true; // 找到元素,提前结束循环 } } return false; // 循环结束,未找到元素 } - 在循环中使用
总之,return 关键字在函数中具有重要的作用,它可以用于返回值、提前结束函数执行、在不同位置返回不同的值,甚至返回指针或数组。合理和正确地使用 return 可以使函数代码更加清晰、灵活且易于维护。
函数重载
一个或多个函数,名字相同,然而参数个数或参数类型不相同,这叫做函数的重载。
以下三个函数是重载关系:
int Max(double f1,double f2) {
}
int Max(int n1,int n2) {
}
int Max(int n1,int n2,int n3) {
}
函数重载使得函数命名变得简单。
编译器根据调用语句的中的实参的个数和类型判断应该调用哪个函数。
下面是一个简单的示例,展示如何使用函数重载来实现不同数据类型的加法运算:
#include <iostream>
// 加法运算:两个整数相加
int sum(int a, int b)
{
return a + b;
}
// 加法运算:两个浮点数相加
double sum(double a, double b)
{
return a + b;
}
int main()
{
// 整数相加
int x = 5;
int y = 10;
std::cout << "sum of " << x << " and " << y << " is " << sum(x, y) << '\n';
// 浮点数相加
double d1 = 2.5;
double d2 = 3.7;
std::cout << "sum of " << d1 << " and " << d2 << " is " << sum(d1, d2) << '\n';
return 0;
}
在此示例中,我们定义了两个具有相同名称sum的函数,但是输入参数的类型不同。分别为整型和浮点型,这样就可以使用函数重载来实现对不同类型数据的处理和计算。
函数缺省参数
C++中,定义函数的时候可以让最右边的连续若干个参数有缺省值,那么调用函数的时候,若相应位置不写参数,参数就是缺省值
void func( int x1, int x2 = 2, int x3 = 3)
{
}
func(10 ) ; //等效于 func(10,2,3)
func(10,8) ; //等效于 func(10,8,3)
func(10, , 8) ; //不行,只能最右边的连续若干个参数缺省
函数参数可缺省的目的在于提高程序的可扩充性。
即如果某个写好的函数要添加新的参数,而原先那些调用该函数的语句,未必需要使用新增的参数,那么为了避免对原先那些函数调用语句的修改,就可以使用缺省参数。
内联函数
函数调用是有时间开销的。如果函数本身只有几条语句,执行非常快,而且函数被反复执行很多次,相比之下调用函数所产生的这个开销就会显得比较大。
为了减少函数调用的开销,引入了内联函数机制。编译器处理对内联函数的调用语句时,是将整个函数的代码插入到调用语句处,而不会产生调用函数的语句。
1.inline int Max(int a,int b)
{
if( a > b) return a;
return b;
}
2.下面是一个简单的示例,展示如何使用内联函数来计算两个整数之和:
```c++
#include <iostream>
inline int sum(int a, int b) // 定义内联函数
{
return a + b; // 直接返回两数之和
}
int main()
{
int x = 5;
int y = 10;
std::cout << "sum of " << x << " and " << y << " is " << sum(x, y) << '\n';
return 0;
}
在编译期间,编译器通过将`sum()`函数的代码插入到主程序中,来避免函数调用时发生额外的开销。此外,由于此函数的代码块非常简短,因此提高效率的作用更加明显。
1.1填空题
(1)一个完整的可运行程序中必须有一个名为main的函数。 (2)一条表达式语句必须以分号作为结束符。 (3)一个函数定义由函数头部和函数体两部分组成。 (5)C++语言头文件和源程序文件的扩展名分别.h CPP (7)当使用Void保留字作为函数类型时,该函数不返回任何值。 (8)当函数参数表用Void保留字表示时,表示该参数表为空。 (9)从一条函数原型语句“intfun1(void);”可知,该函数的返回类型为 13 烧丝,该函 数带有仪0个参数。 (10)在#include命令中所包含的头文件,可以是系统定义的头文件,也可以是住用户白 定义的头文件。 上与其他同 名函数有所不同。 (12)如果一个函数中有多个默认参数,则默认参数必须全部处在形参表的 部分。 (13)函数形参的作用域是该函数的在国范围函本 (14)当定义一个结构体变量时,系统分配给该变量的内存大小等于各成员所需内存大小 L 的总和 洗择顶
课后练习题(1)

访问对象 a 的公有成员变量 x 的格式是 a.x。
假设已定义类 A 具有公有成员变量 x,通过创建类 A 的对象 a,我们可以使用对象名 a 后面加上成员访问运算符 .,然后紧跟着成员变量名 x,来访问该成员变量。
示例代码如下所示:
class A {
public:
int x;
};
int main() {
A a;
a.x = 10; // 访问对象 a 的成员变量 x,并赋值为 10
return 0;
}
在上述示例中,我们定义了一个类 A,其中具有公有成员变量 x。在 main() 函数中,我们创建了类 A 的一个对象 a,然后通过 a.x 访问对象 a 的成员变量 x,并将其赋值为 10。
需要注意的是,访问对象的成员变量时,应确保该成员变量的访问修饰符允许在当前作用域中进行访问。如果成员变量 x 是私有的或受保护的,则不能直接通过对象名来访问,而需要通过公有的成员函数来间接访问。
类的构造函数是在定义该类的一个( 对象 )时自动调用的。
对于任意一个类,用户所能定义的构造函数的个数至多为( )。
对于任意一个类,用户所能定义的构造函数的个数至多为无限大。
在 C++ 中,类可以有多个构造函数,用户可以根据需要定义多个构造函数来初始化对象的不同属性。构造函数用于在创建对象时初始化对象的成员变量或执行其他必要的操作。用户定义的构造函数可以具有不同的参数列表,以允许在创建对象时提供不同的参数值。
例如,一个类可以有默认构造函数(无参数),带有一个参数的构造函数,带有多个参数的构造函数等等。这样,用户就可以根据不同的情况和需求选择合适的构造函数来创建对象。
以下是一个示例,展示了一个类 Person 具有多个构造函数的情况:
#include <iostream>
using namespace std;
class Person {
public:
string name;
int age;
// 默认构造函数
Person() {
name = "Unknown";
age = 0;
}
// 带参数的构造函数
Person(string n, int a) {
name = n;
age = a;
}
};
int main() {
Person p1; // 使用默认构造函数
cout << p1.name << endl; // 输出: Unknown
cout << p1.age << endl; // 输出: 0
Person p2("Alice", 25); // 使用带参数的构造函数
cout << p2.name << endl; // 输出: Alice
cout << p2.age << endl; // 输出: 25
return 0;
}
在上述示例中,类 Person 具有两个构造函数:一个是默认构造函数,另一个是带参数的构造函数。用户可以选择使用合适的构造函数来创建对象,并根据构造函数的定义来初始化对象的成员变量。
因此,对于任意一个类,用户可以定义多个构造函数,没有个数的限制。
当一个自动对象离开它的作用域时,系统自动调用该类的析构函数。
在 C++ 中,析构函数是一种特殊的成员函数,在对象被销毁时自动调用。它的作用是在对象生命周期结束时执行一些清理工作,如释放动态分配的内存、关闭文件等。析构函数的名称与类名相同,前面加上一个波浪号(~)作为前缀。
当自动对象离开其作用域时(例如,函数执行完毕、代码块结束),系统会自动调用该类的析构函数,以确保资源的正确释放和清理。
以下是一个示例,展示了一个类 Person 具有析构函数的情况:
#include <iostream>
using namespace std;
class Person {
public:
string name;
// 构造函数
Person(string n) {
name = n;
cout << "构造函数被调用 - " << name << endl;
}
// 析构函数
~Person() {
cout << "析构函数被调用 - " << name << endl;
}
};
int main() {
{
Person p1("Alice"); // 创建自动对象 p1
Person p2("Bob"); // 创建自动对象 p2
} // p1 和 p2 在这里离开作用域,调用析构函数
return 0;
}
在上述示例中,类 Person 具有构造函数和析构函数。在 main() 函数中的代码块内部,我们创建了两个自动对象 p1 和 p2,它们分别在作用域结束时离开作用域。当这两个对象离开作用域时,系统会自动调用它们对应的析构函数。在控制台输出中可以看到构造函数和析构函数被调用的顺序。
因此,当一个自动对象离开它的作用域时,系统会自动调用该类的析构函数,以完成资源的清理工作。
//析构函数destructors
名字与类名相同,在前面加‘~’, 没有参数和返回值,一个类最多只能有一个析构函数。
析构函数对象消亡时即自动被调用。可以定义析构函数来在对象消亡前做善后工作,比如释放分配的空间等。
如果定义类时没写析构函数,则编译器生成缺省析构函数。缺省析构函数什么也不做。
如果定义了析构函数,则编译器不生成缺省析构函数。
析构函数是与构造函数相对应的一种特殊函数,主要用于在对象生命周期结束时清理对象占用的内存资源。
在C++中,每个类都可以定义自己的析构函数,它由一个波浪号~和类名组成,并且不需要参数或返回值。通常情况下,需要清理动态分配的内存、关闭打开的文件、释放网络连接等等操作都可以在析构函数中实现。
在下面的示例代码中,我们定义了一个名为Person的类,其中包含有两个成员变量name和age,我们在这个类中定义了一个简单的析构函数,用于在对象被销毁时输出一条消息:
#include<iostream>
using namespace std;
class Person {
public:
string name;
int age;
Person(string n, int a): name(n), age(a) {
// 构造函数
cout << "Object created." << endl;
}
~Person(){
// 析构函数
cout << "Object destroyed." << endl;
}
};
int main() {
Person p1("张三", 20);
return 0;
}
在上述代码中,我们定义了一个Person对象p1,并初始化了它的属性(姓名和年龄)。在main()函数结束后,程序运行完毕,也就是Person对象p1的生命周期结束时,会自动调用析构函数~Person()来释放占用的内存资源。在这个析构函数中,我们简单地输出了一条消息“Object destroyed.”。
总之,析构函数是类的一个特殊函数,在对象生命周期结束时自动调用(或者手动调用),它的主要作用就是清理对象所占用的资源,例如动态分配的内存、打开的文件等。借助析构函数,我们能够更好地控制程序使用内存资源的方式,并避免出现内存泄漏等问题。
为什么需要析构函数
在C++中,我们经常要使用动态内存分配来创建对象,例如使用new关键字来为一个对象分配内存空间。由于程序运行完毕后需要释放这部分动态分配的内存空间,因此我们需要使用delete关键字来释放这些内存空间。
如果我们没有合理地释放这些内存,在程序执行一段时间之后,就会耗尽机器物理内存,导致系统崩溃或程序运行效率下降。因此,为了避免出现内存泄漏等问题,我们可以使用析构函数来释放所占用的内存资源。
此外,析构函数的另一个重要作用是帮助我们管理类中的各种数据结构和状态。通常我们可以使用析构函数来释放资源但需要注意的是,在大多数情况下,析构函数在对象被销毁时自动调用,程序员无需手动调用。
综上所述,析构函数是为了解决程序中动态内存申请和管理的问题而存在的,它是一种特殊的函数,当对象生命周期结束时自动调用,主要用于清理对象所占用的资源、还原对象的状态等。使用析构函数能够有效地管理内存资源,防止内存泄漏以及其它相关问题的发生。

假定Student为一个类,则执行“Student *s = new Student(a, 20);”语句时得到一个动态对象为( *s )。
执行语句Student *s = new Student(a, 20);将得到一个动态对象,并且通过指针 s 可以访问和操作这个动态对象。
具体来说,new Student(a, 20) 这个表达式将调用类 Student 的构造函数,并传递参数 a 和 20。然后,它会在堆上分配内存以存储 Student 对象,并返回一个指向该对象的指针。这个指针被赋值给变量 s,因此 s 指向了创建的动态对象。
通过解引用指针 s,即使用 *s,可以获取动态对象本身,而不是指向它的指针。因此,*s 表示这个动态对象本身。
例如,可以通过 (*s).methodName() 来调用动态对象的方法,或者使用 (*s).memberVariable 来访问动态对象的成员变量。
需要注意的是,在不再需要这个动态对象时,应该使用 delete 运算符释放它所占用的内存。例如,可以使用 delete s; 来释放上述示例中创建的动态对象和相关内存。
所以,执行语句Student *s = new Student(a, 20);得到一个动态对象,可以通过 *s 来访问和操作这个动态对象。
下面程序的运行结果为( )。
#include <iostream.h>
void main(void)
{
int a(50), &b = a;
cout << "b=" << b << endl;
a+=50;
cout<<"b="<<b<<endl;
b+=80;
cout<<"a="<<a<<endl;
}
该程序存在一些问题,无法通过编译。主要问题在于使用了过时的头文件 <iostream.h>,正确的头文件应为 <iostream>。
另外,void main(void) 是一种不符合标准的 main 函数定义方式,应改为 int main()。
以下是修正后的程序:
#include <iostream>
int main()
{
int a(50), &b = a;
std::cout << "b=" << b << std::endl;
a += 50;
std::cout << "b=" << b << std::endl;
b += 80;
std::cout << "a=" << a << std::endl;
return 0;
}
修正后的程序输出结果为:
b=50
b=100
a=180
解释如下:
- 首先,将变量
a初始化为 50,并创建引用b,使其引用a。 - 输出
b的值为 50。 - 对
a进行加 50 的操作,a的值变为 100。 - 输出
b的值为 100,因为b是对a的引用,所以随着a的改变,b的值也会改变。 - 对
b进行加 80 的操作,a的值变为 180,同样的原因,b的值也会跟着改变。 - 输出
a的值为 180。
因此,程序的运行结果为:
b=50
b=100
a=180
假定要求下面程序的输出结果为“11/15”,其主函数中存在着三行语句错误,请指出错误语句行的行号。
#include <iostream.h>
class Franction {
int nume;
int deno;
public:
InitFranction() {
nume=0; deno=1;}
void InitFranction(int n, int d) {
nume=n; deno=d;}
void FranSimp();
Franction FranAdd(const Franction& x);
void FranOutput()
{
cout<<nume<<'/'<<deno<<endl;
}
};
void main()
{
Franction a,b,c; //1行
a.InitFranction(6,15); //2行
b.InitFranction(1); //3行
c=FranAdd(a,b); //4行
cout<<c.nume<<'/'<<c.deno<<endl; //5行
}
下面是对程序中的错误进行指出:
-
第 2 行:
#include <iostream.h>是错误的,应为#include <iostream>。正确的头文件应该是<iostream>。 -
第 13 行:
InitFranction()应改为Franction(),以匹配类名。函数名和类名应相同才能作为构造函数。 -
第 25 行:
void main()应改为int main()。主函数必须返回一个整型值。 -
第 32 行:
c = FranAdd(a, b);是错误的,应改为c = a.FranAdd(b);。FranAdd()是Franction类的成员函数,应通过对象调用。
修正后的代码如下:
#include <iostream>
class Franction {
int nume;
int deno;
public:
Franction() {
nume = 0; deno = 1; }
void InitFranction(int n, int d) {
nume = n; deno = d; }
void FranSimp();
Franction FranAdd(const Franction& x);
void FranOutput()
{
std::cout << nume << '/' << deno << std::endl;
}
};
int main()
{
Franction a, b, c;
a.InitFranction(6, 15);
b.InitFranction(1);
c = a.FranAdd(b);
std::cout << c.nume << '/' << c.deno << std::endl;
return 0;
}
此时,程序将会输出 11/15。
下面程序是有问题的,请指出需要修改哪三行?
#include <iostream.h>
class CE{
int a,b;
public:
int c;
void SetValue(int x1,int x2, int x3)
{
a=x1; b=x2; c=x3;
}
int GetMin(); //1行
};
int GetMin() //2行
{
return (a < b ? a : b); //3行
}
void main()
{
CE test; //4行
test.SetValue(1, 2, 3); //5行
c = GetMin(); //6行
cout<<c<<endl; //7行
}
-
第 6 行:
int c;是错误的位置,应将其放在类定义内部的public访问标识之后。 -
在
CE类内部,应将GetMin()函数的声明从注释的地方移到正确的位置,即在SetValue()函数声明之后。 -
在
CE类外部,GetMin()函数的定义应改为成员函数形式,在函数名前加上类名CE::。
修正后的代码如下:
#include <iostream>
class CE {
int a, b;
public:
int c;
void SetValue(int x1, int x2, int x3)
{
a = x1; b = x2; c = x3;
}
int GetMin();
};
int CE::GetMin()
{
return (a < b ? a : b);
}
int main()
{
CE test;
test.SetValue(1, 2, 3);
int c = test.GetMin();
std::cout << c << std::endl;
return 0;
}
此时,程序将会输出 1。
函数重载是指在同一个作用域内,可以定义多个具有相同函数名但参数列表不同的函数。这样做的目的是为了提供更灵活的函数调用方式,以适应不同的参数类型或参数个数的情况。
函数重载的特点包括:
- 函数名称相同:重载函数具有相同的函数名。
- 参数列表不同:重载函数的参数列表必须不同,可以是参数类型不同、参数个数不同或参数顺序不同。
- 返回值类型不作为重载的条件:重载函数的返回值类型可以相同也可以不同。
- 在同一个作用域内:重载函数必须在同一个作用域内定义。
函数重载允许我们定义具有相似功能但参数类型或参数个数不同的函数,使得代码更加简洁、可读性更高,并且提供了更好的灵活性和易用性。
** int function(char*x) char p=x;while(p++);return(p-x-1);
返回结果为求字符串的长度
根据您提供的代码,int function(char *x) 函数的实现如下:
int function(char *x) {
char *p = x;
while (*p++) ;
return (p - x - 1);
}
这个函数将接受一个名为 x 的字符指针作为参数。它首先将 x 赋值给指针变量 p,然后通过一个 while 循环遍历指针 p 所指向的字符数组,直到达到字符串的结尾(即空字符 \0)。在循环结束后,该函数将返回字符串的长度,即最后指针 p 指向的位置减去起始指针 x 的位置,并减去 1(因为要排除结尾的空字符)。
请注意,这个函数假设传入的字符指针 x 是以空字符结尾的有效字符串。如果传入的参数不满足该条件,可能会导致意想不到的结果或错误。在使用该函数时,请确保传入正确的参数。
重载函数的作用
函数重载的作用主要有以下几个方面:
-
提供更灵活的函数调用方式:通过函数重载,可以为相同的操作提供不同的参数类型或参数个数的函数版本。这样,调用者可以根据需要选择最合适的函数进行调用,而无需记住多个不同的函数名。
-
增强代码可读性和可维护性:通过命名相同但参数列表不同的函数,可以使代码更加清晰和易懂。函数重载可以用于表示功能相似但操作对象或参数类型不同的情况,从而提高代码的可读性和可维护性。
-
避免函数命名冲突:当需要实现类似功能的函数时,由于函数名是唯一标识符,使用不同的函数名可能会导致冲突。通过函数重载,可以在同一个作用域内使用相同的函数名,并通过参数列表的不同来区分它们,避免了命名冲突。
-
减少相似功能代码的重复:当功能相似的操作需要实现多次时,通过函数重载,可以将这些操作整合到同一个函数名下。这样可以减少重复的代码,并提高代码的复用性和可维护性。
总而言之,函数重载可以提供更灵活的函数调用方式,增强代码的可读性和可维护性,避免函数命名冲突,并减少重复代码的存在。通过适当使用函数重载,可以使代码更加简洁、灵活和易于理解。
#include
#include
void f(int *p, int n) {
for (int i = 0; i < n; i++) {
(*p)++;
}
}
int main() {
int i, a[] = {0, 1, 2, 3, 4};
int *p = &a[0];
f(p, 2);
for (i = 0; i < 5; i++) {
std::cout << a[i];
}
return 0;
}
当执行该代码时,会按照以下步骤执行:
-
在
main函数开始处,定义了整型变量i、整型数组a和指向数组a的整型指针p。数组a初始化为{0, 1, 2, 3, 4},指针p指向数组a的第一个元素。 -
调用函数
f(p, 2),将指针p和参数值2传递给函数f。 -
进入函数
f,在函数内部定义了整型变量i,并使用for循环对数组a的前n个元素进行自增操作。在本例中,由于n的值为2,所以循环迭代两次,对数组a的第一个元素执行(*p)++操作,即将指针p所指向的值自增 1。因此,数组a变为{2, 1, 2, 3, 4}。 -
函数
f执行完毕后,返回到main函数。 -
在
main函数中,使用for循环遍历数组a的所有元素,并使用std::cout输出每个元素的值。因此,输出结果为11234。 -
最后,
main函数结束,返回值为0,程序执行完毕。
最终结果21234
函数的定义不可以嵌套,函数的调用可以嵌套
new delete 用法
new 和 delete 是 C++ 中用于动态分配和释放内存的关键字。
new 用于动态创建单个对象或一块连续的内存空间,并返回该对象或内存块的指针。它的语法如下:
T* pointer = new T;
T* array = new T[size];
其中,T 是要分配的对象的类型,pointer 是指向新分配的单个对象的指针,array 是指向新分配的连续对象数组的指针,size 是数组的大小。
示例:
int* p = new int; // 动态分配一个 int 类型的对象,返回指向该对象的指针
int* arr = new int[5]; // 动态分配一个包含 5 个 int 类型对象的数组,返回指向数组的指针
在使用 new 分配内存后,可以通过指针来访问和操作分配的对象或数组。
相应地,delete 用于释放通过 new 分配的内存空间,以便将其返回给系统。它的语法如下:
delete pointer;
delete[] array;
其中,pointer 是要释放的单个对象的指针,array 是要释放的对象数组的指针。请注意,如果是通过 new[] 分配了一个数组,则必须使用 delete[] 进行释放。
示例:
int* p = new int; // 使用 new 分配内存
delete p; // 释放分配的内存
int* arr = new int[5]; // 使用 new[] 分配数组内存
delete[] arr; // 释放分配的数组内存
注意,使用 new 分配的内存必须通过对应的 delete 进行释放,以避免出现内存泄漏。
总结起来,new 和 delete 是 C++ 中的动态内存分配和释放操作符,用于在运行时分配和释放对象或数组所需的内存空间。
第二章 类与对象
什么是类?
在面向对象编程 (OOP) 中,类(Class)是一种用于创建对象的蓝图或模板。它是一种抽象数据类型,用于定义对象的属性(数据成员)和行为(成员函数)。
类可以看作是一种用户自定义的数据类型,它封装了数据和操作数据的方法。通过定义类,可以创建多个相同类型的对象,每个对象都具有相同的属性和行为。类提供了一种组织和管理相关数据和功能的方式,使得代码更易读、可维护和可扩展。
类由数据成员和成员函数组成。数据成员是类中的变量,用于保存对象的状态和属性;成员函数是类中的函数,用于操作和处理对象的数据。
类的定义通常包括类名、数据成员和成员函数的声明。通过实例化类(创建对象),可以使用类中定义的数据成员和成员函数来完成特定的任务。
举个简单的例子,假设我们要创建一个表示矩形的类,可以定义一个名为 Rectangle 的类。该类可以拥有数据成员(例如矩形的宽度和高度)和成员函数(例如计算矩形的面积和周长)。然后,我们可以根据这个类创建多个矩形对象,并使用类提供的方法来操作和访问这些对象的属性。
总而言之,类是面向对象编程中的核心概念,通过封装数据和函数来创建可重用的代码模块,实现了代码的抽象、封装和继承等特性。
面向对象的程序设计
面向对象的程序设计方法,能够较好解决上述问题。
面向对象的程序 = 类 + 类 + …+ 类
设计程序的过程,就是设计类的过程。
面向对象的程序设计方法:
将某类客观事物共同特点(属性)归纳出来,形成一个数据
结构(可以用多个变量描述事物的属性);将这类事物所能进行的行为也归纳出来,形成一个个函数,这些函数可以用来操作数据结构(这一步叫“抽象”)。然后,通过某种语法形式,将数据结构和操作该数据结构的函数“捆绑”在一起,形成一个“类”,从而使得数据结构和操作该数据结构的算法呈现出显而易见的紧密关系,这就是“封装”。
面向对象的程序设计具有“抽象”,“封装”“继承”“多态”四个基本特点。
类和对象
在C++中,类(Class)是一种面向对象的概念,它描述了一个包含数据和方法(函数)的抽象实体,用来定义某个对象的属性和行为。类只是模板或蓝图,在创建对象时依据其定义,用于声明一个具有特定属性和功能的新数据类型。
而对象(Object)则是通过实例化一个类(可以理解为从类中生成一个具体的实例)而得到的一个真实存在的事物,拥有类所描述的属性和行为。通过操作对象的属性和行为,我们可以完成各种任务和操作。
例如,我们可以定义一个名为Rectangle的类来描述矩形,如下所示:
class Rectangle
{
public:
double width;
double height;
double area()
{
return width * height;
}
};
该类中包含属性width和height,表示矩形的长和宽,并定义了一个成员函数area()用于计算矩形的面积。现在我们可以通过实例化这个类来创建一个真正的矩形对象,如下所示:
Rectangle r; // 创建一个矩形对象
r.width = 2.5; // 设置矩形的宽度
r.height = 3.7; // 设置矩形的高度
double a = r.area(); // 调用矩形的成员函数计算矩形的面积
这里的r就是一个矩形对象,它包含了类Rectangle中定义的属性和行为(成员函数),我们可以通过直接操作这些属性来进行计算,而不必关心具体的实现方式。
C++中的类和对象提供了一种抽象和封装的机制,帮助程序员更好地管理和组织代码,并以更高效、更安全的方式进行编程和设计。
抽象(Abstraction)、封装(Encapsulation)、多态(Polymorphism)和继承(Inheritance)是面向对象编程的四个核心概念
抽象(Abstraction)、封装(Encapsulation)、多态(Polymorphism)和继承(Inheritance)是面向对象编程的四个核心概念。它们有助于组织和设计代码,提高代码的可复用性、可维护性和可扩展性。
-
抽象(Abstraction):抽象是将复杂的现实世界问题简化为程序中的对象和类的过程。它关注于对象的本质特征和行为,隐藏了不必要的细节,并提供了一种清晰、简洁的方式来描述对象。可以通过类的定义来实现抽象。
-
封装(Encapsulation):封装是将数据和处理数据的函数(方法)包装在一个单元(类)中的机制。它通过将相关的数据和函数捆绑在一起,形成一个独立的、可控的单元,从而实现了信息隐藏和访问控制。只有类内部定义的方法可以直接访问类的私有成员变量,对外部来说只能通过类的公有接口进行访问。
-
多态(Polymorphism):多态是同一个接口可以有多种实现方式的能力。在多态中,可以使用基类的指针或引用来引用派生类对象,并根据实际对象的类型来调用相应的方法。多态性允许同一个方法具有不同的行为,提供了一种灵活且可扩展的设计方式。
-
继承(Inheritance):继承是一种从已有类派生出新类的机制,新类(派生类)继承了已有类(基类)的属性和方法。通过继承,派生类可以重用基类的代码,并在此基础上进行扩展或修改。继承可以形成类之间的层次结构,增强了代码的组织和复用性。
这四个概念相互关联,相互作用,共同构建了面向对象编程的基础。抽象和封装提供了良好的代码设计和封装性,多态和继承支持了代码的灵活性和可扩展性。通过合理应用这些概念,可以创建高质量、可维护和可扩展的面向对象程序。
当涉及到抽象、封装、多态和继承的概念时,以下是一个简单的示例代码来说明这些概念在实践中的应用:
#include <iostream>
using namespace std;
// 1. 抽象和封装
class Shape {
public:
// 纯虚函数,用于定义接口
virtual double calculateArea() = 0;
virtual void display() = 0;
};
// 2. 多态
class Rectangle : public Shape {
private:
double length;
double width;
public:
Rectangle(double l, double w) : length(l), width(w) {
}
double calculateArea() override {
return length * width;
}
void display() override {
cout << "Rectangle: Length = " << length << ", Width = " << width << endl;
}
};
class Circle : public Shape {
private:
double radius;
public:
Circle(double r) : radius(r) {
}
double calculateArea() override {
return 3.14159 * radius * radius;
}
void display() override {
cout << "Circle: Radius = " << radius << endl;
}
};
// 3. 继承
class Square : public Rectangle {
public:
Square(double s) : Rectangle(s, s) {
}
// 可以覆盖基类的方法
double calculateArea() override {
return Rectangle::calculateArea();
}
// 可以使用基类的方法
void display() override {
Rectangle::display();
}
};
int main() {
// 使用抽象类的指针来实现多态
Shape* shape1 = new Rectangle(5, 3);
Shape* shape2 = new Circle(2);
Shape* shape3 = new Square(4);
// 通过多态调用各自的方法
shape1->display();
cout << "Area: " << shape1->calculateArea() << endl;
shape2->display();
cout << "Area: " << shape2->calculateArea() << endl;
shape3->display();
cout << "Area: " << shape3->calculateArea() << endl;
// 释放内存
delete shape1;
delete shape2;
delete shape3;
return 0;
}
在上述代码中,我们定义了一个抽象类 Shape。Shape 类有两个纯虚函数 calculateArea() 和 display(),这些函数没有具体的实现。然后,我们派生了两个具体的形状类 Rectangle 和 Circle,它们分别实现了 Shape 类的纯虚函数,并提供了自己的具体实现。同时,我们还演示了继承的概念,创建了一个 Square 类作为 Rectangle 类的派生类,重用了 Rectangle 类的代码。
在 main() 函数中,我们使用抽象类 Shape 的指针来实现多态性。通过多态性,我们可以使用基类的指针来引用不同的派生类对象,并调用相应的方法。这样,我们可以通过统一的接口来处理不同的形状对象。
该示例代码展示了抽象、封装、多态和继承的主要概念,并简单说明了它们在实践中的用法。通过这些概念,我们可以更好地组织和设计代码,实现面向对象编程的优势。
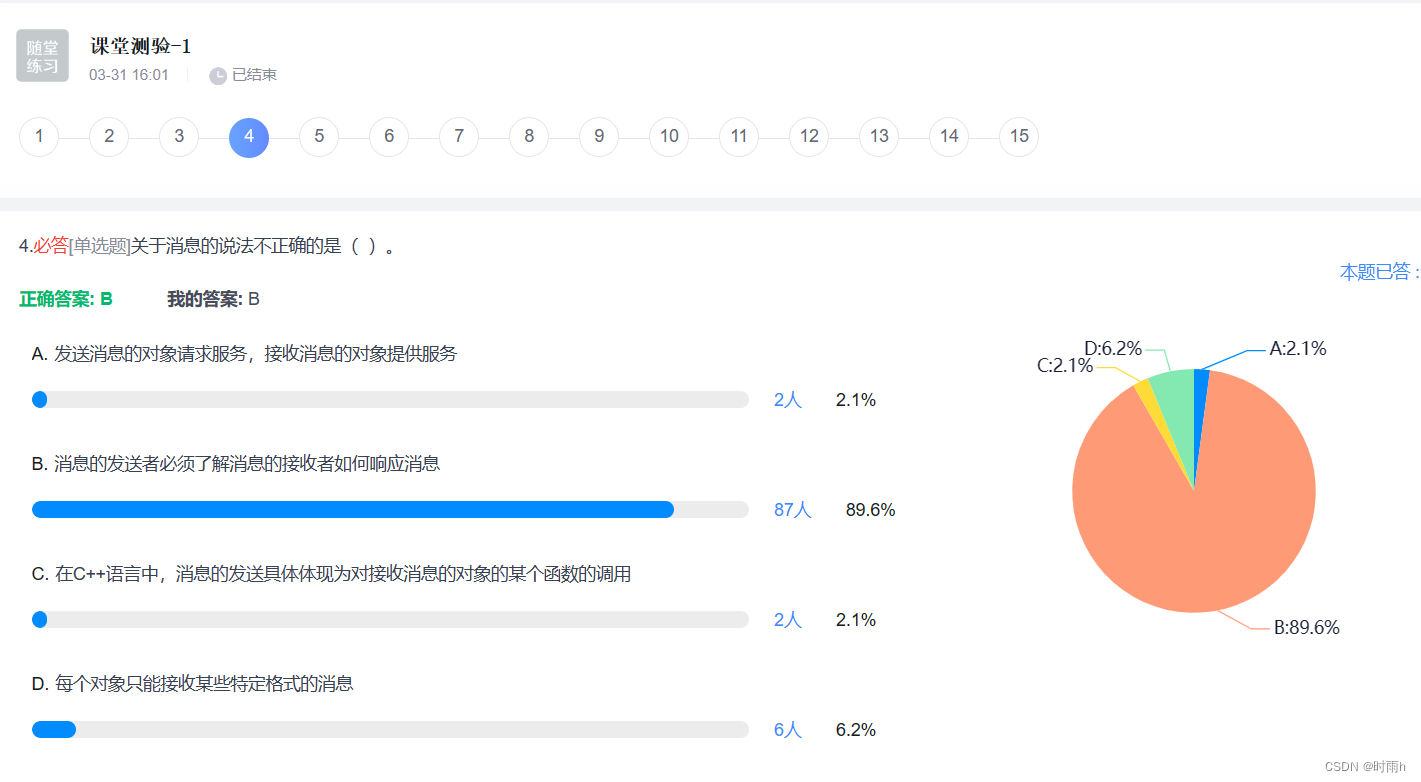
课后练习题(2)
2.7 消息是面向对象编程中的一个概念,它表示在对象之间传递的一种通信方式。消息可以看作是对象之间进行交互的一种方式,一个对象可以向另一个对象发送消息,并期望接收者执行相应的操作。
事件是指程序运行过程中发生的某些事情或状态的变化。事件可以是用户的操作、系统的内部状态变化等。在面向对象编程中,事件常常用于触发特定的操作或通知其他对象。
2.9 多态性有三种:静态多态、动态多态和参数多态。
- 静态多态(也称为编译时多态):通过函数重载和运算符重载实现,编译器在编译时根据函数参数和运算符类型来决定调用哪个函数。
- 动态多态(也称为运行时多态):通过继承和虚函数实现,运行时根据对象的实际类型来决定调用哪个函数,实现了多态的特性。
- 参数多态:通过模板技术实现,在编译时根据模板参数的不同生成不同的函数代码,提高代码的灵活性和复用性。
这些多态性的定义和实现机制不同,但都能够实现代码的灵活性和可扩展性。
2.12 面向对象分析阶段是软件开发过程中的一部分,其目标是理解问题领域中的需求,并将其转化为面向对象的概念模型。在这个阶段,需要完成以下工作:
- 理解和收集用户需求,明确系统应具备的功能和性能要求。
- 分析问题领域中的实体、行为和关系,识别潜在的对象和类。
- 定义对象的属性和方法,建立类的初步设计。
- 创建用例图、类图等模型,描述系统的功能和类之间的关系。
2.13 面向对象设计阶段是在面向对象分析阶段的基础上,进一步细化和完善概念模型,并进行系统的架构设计。在这个阶段,需要完成以下工作:
- 根据需求分析结果,进行类的详细设计,确定每个类的属性、方法、关系等细节。
- 设计系统的模块结构,确定各个模块之间的关系和接口。
- 确定系统的架构风格和设计模式,选择适当的设计策略和技术。
- 创建类图、时序图等模型,描述系统的结构和行为。
2.14 面向对象实现阶段是将面向对象设计阶段的设计转化为可执行的代码阶段。在这个阶段,需要完成以下工作:
- 根据设计阶段的类图和时序图,编写类的具体实现代码。
- 实现类之间的关系和接口,确保类之间的协同工作。
- 编写测试代码,对实现的类进行单元测试和集成测试。
- 进行性能优化和调试,确保系统的功能正确性和性能满足要求。
2.15 面向对象程序设计的优点包括:
- 可重用性:面向对象的代码结构更加模块化和可扩展,可以更好地复用已有的代码,减少重复开发。
- 灵活性:面向对象的程序设计使得代码更加灵活和可维护,可以方便地修改和扩展功能。
- 可读性:使用面向对象的设计原则和规范,使代码更容易理解和阅读,降低了代码的复杂性。
- 易于维护:面向对象的程序设计使得问题域与代码的映射更加紧密,改动某一部分不会影响其他部分,便于程序的维护和迭代。
- 抽象和封装:面向对象的设计可以将数据和处理操作封装在对象中,并通过接口隐藏内部细节,增强了安全性和代码的可靠性。
- 多态性:面向对象的编程语言支持多态性,通过继承和虚函数机制,可以在运行时确定对象的实际类型,提高了代码的灵活性和可扩展性。
第三章 类和对象
课时4.类与对象
类与对象的认识
C+是一门面向对像的编程语言,
理解C+,首先要理解类(Class)
和对象(Object)两个概念.
类是结构体一种升级,是一种复杂数据类型的声明,不占用内存空间,
对象是类这种数据类型的一个变量,所以占用内存空间
类的作用及概念:
1、c++通过类来实现封装,类是由用户定义的数据类型,
目的是让使用类和使用基本数据类型一样简单;
2、面向对像程序设计的三个特征:封装性、多态性和继承性,
多态性是指具有不同功能的函数可以使用相同的函数名,也称为函数重载
3、在类体内不能对数据成员进行初始化(因为没定义对象)
例:Class A[private:int data:=2;}->错误

对象间的运算
和结构变量一样,对象之间可以用 “=”进行赋值,但是不能用 “==”,“!=”,“>”,“<”“>=”“<=”进行比较,除非这些运算符经过了“重载”。
用法1:对象名.成员名
CRectangle r1,r2;
r1.w = 5;
r2.Init(5,4); //Init函数作用在 r2 上,即Init函数执行期间访问的
//w 和 h是属于 r2 这个对象的, 执行r2.Init 不会影响到 r1。
用法2. 指针->成员名
CRectangle r1,r2;
CRectangle * p1 = & r1;
CRectangle * p2 = & r2;
p1->w = 5;
p2->Init(5,4); //Init作用在p2指向的对象上
用法3:引用名.成员名
CRectangle r2;
CRectangle & rr = r2;
rr.w = 5;
rr.Init(5,4); //rr的值变了,r2的值也变
void PrintRectangle(CRectangle & r)
{
cout << r.Area() << ","<< r.Perimeter(); }
CRectangle r3;
r3.Init(5,4);
PrintRectangle(r3);
类成员的可访问范围
在类的定义中,用下列访问范围关键字来说明类成员可被访问的范围:
– private: 私有成员,只能在成员函数内访问
– public : 公有成员,可以在任何地方访问
– protected: 保护成员,以后再说
以上三种关键字出现的次数和先后次序都没有限制。
定义一个类
class className {
private:
私有属性和函数//说明类成员的可访问范围
public:
公有属性和函数//说明类成员的可访问范围
protected:
保护属性和函数//说明类成员的可访问范围
};
如果某个成员前面没有上述关键字,则缺省地被认为
是私有成员。
利用类与对象实现复数类相加减
可以通过创建一个名为Complex的类来实现复数的相加和相减操作。下面是一个简单的示例代码:
class Complex:
def __init__(self, real, imaginary):
self.real = real
self.imaginary = imaginary
def add(self, other):
real_part = self.real + other.real
imag_part = self.imaginary + other.imaginary
return Complex(real_part, imag_part)
def subtract(self, other):
real_part = self.real - other.real
imag_part = self.imaginary - other.imaginary
return Complex(real_part, imag_part)
在上面的代码中,我们定义了一个Complex类,它有两个属性:real(实部)和imaginary(虚部)。构造函数__init__用于初始化复数对象。
类中还实现了两个方法:add和subtract。这两个方法分别用于实现复数的相加和相减操作。在这些方法中,我们将输入的两个复数的实部和虚部进行相应的运算,并创建一个新的Complex对象来表示运算结果。
下面是一个简单的示例演示如何使用这个Complex类:
# 创建两个复数对象
comp1 = Complex(3, 4)
comp2 = Complex(1, 2)
# 相加操作
result_add = comp1.add(comp2)
print("相加结果:", result_add.real, "+", result_add.imaginary, "i")
# 相减操作
result_subtract = comp1.subtract(comp2)
print("相减结果:", result_subtract.real, "+", result_subtract.imaginary, "i")
运行上述代码,输出将是:
相加结果: 4 + 6 i
相减结果: 2 + 2 i
这样,我们就利用类和对象实现了复数的相加和相减操作。
构造函数(constructor)
基本概念
成员函数的一种
名字与类名相同,可以有参数,不能有返回值(void也不行)
作用是对对象进行初始化,如给成员变量赋初值
如果定义类时没写构造函数,则编译器生成一个默认的无参数的构造函数
•默认构造函数无参数,不做任何操作
如果定义了构造函数,则编译器不生成默认的无参数的构造函数对象生成时构造函数自动被调用。对象一旦生成,就再也不能在其上执行构造函数一个类可以有多个构造函数
为什么需要构造函数:
- 构造函数执行必要的初始化工作,有了构造函数,就不必专门再写初始化函数,也不用担心忘记调用初始化函数。
- 有时对象没被初始化就使用,会导致程序出错。
class Complex {
private:
double real, imag;
public:
void Set( double r, double i);
}; //编译器自动生成默认构造函数
Complex c1; //默认构造函数被调用
Complex * pc = new Complex; //默认构造函数被调用
class Complex {
private :
double real, imag;
public:
Complex( double r, double i = 0);
};
Complex::Complex( double r, double i) {
real = r; imag = i;
}
Complex c1; // error, 缺少构造函数的参数
Complex * pc = new Complex; // error, 没有参数
Complex c1(2); // OK
Complex c1(2,4), c2(3,5);
Complex * pc = new Complex(3,4);
可以有多个构造函数,参数个数或类型不同
class Complex {
private :
double real, imag;
public:
void Set( double r, double i );
Complex(double r, double i );
Complex (double r );
Complex (Complex c1, Complex c2);
};
Complex::Complex(double r, double i)
{
real = r; imag = i;
}
Complex::Complex(double r)
{
real = r; imag = 0;
}
Complex::Complex (Complex c1, Complex c2);
{
real = c1.real+c2.real;
imag = c1.imag+c2.imag;
}
Complex c1(3) , c2 (1,0), c3(c1,c2);
// c1 = {3, 0}, c2 = {1, 0}, c3 = {4, 0};
构造函数最好是public的,private构造函数
不能直接用来初始化对象
class CSample{
private:
CSample() {
}
};
int main(){
CSample Obj; //err. 唯一构造函数是private
return 0;
}
在C++中,构造函数(Constructor)是一种特殊的成员函数,它用于在对象创建时初始化类的成员变量。通常,每个类都至少有一个构造函数。
构造函数的名称必须与类的名称相同,没有返回类型(void、int等),并且不能手动调用。构造函数的作用是在创建对象时为成员变量赋初值,如下所示:
class Rectangle
{
public:
double width;
double height;
// 构造函数
Rectangle()
{
width = 0;
height = 0;
}
};
上述代码定义了一个Rectangle类,并在其中定义了一个构造函数,该构造函数将宽度和高度初始化为空值。
构造函数在对象被创建时自动执行,可以根据不同需求重载多个不同的构造函数。比如,在构造函数中使用参数列表为成员变量赋值:
class Rectangle
{
public:
double width;
double height;
// 构造函数 #1
Rectangle(double w, double h)
{
width = w;
height = h;
}
// 构造函数 #2
Rectangle()
{
width = 0;
height = 0;
}
};
上述代码中定义了两个构造函数,第一个构造函数用来传入实际的宽度和高度进行初始化,而第二个构造函数不需要任何参数,则按照预设值将其初始化为0。
通过构造函数,在创建对象时就可以有效地进行成员变量的初始化,提高了代码的效率和可读性。需要注意的是,在一个类中只能有一个析构函数(Destructor),它与构造函数类似但在对象被销毁时启动执行。
c++中利用const来设计一个复数类的加减乘除
在C++中,可以使用const关键字来设计一个复数类,并使用成员函数的const限定符来确保不修改对象的状态。下面是一个使用const来设计复数类并实现加减乘除操作的示例代码:
#include <iostream>
class Complex {
public:
Complex(double real, double imaginary) : real_(real), imaginary_(imaginary) {
}
double getReal() const {
return real_;
}
double getImaginary() const {
return imaginary_;
}
Complex add(const Complex& other) const {
double real_part = real_ + other.getReal();
double imag_part = imaginary_ + other.getImaginary();
return Complex(real_part, imag_part);
}
Complex subtract(const Complex& other) const {
double real_part = real_ - other.getReal();
double imag_part = imaginary_ - other.getImaginary();
return Complex(real_part, imag_part);
}
Complex multiply(const Complex& other) const {
double real_part = real_ * other.getReal() - imaginary_ * other.getImaginary();
double imag_part = real_ * other.getImaginary() + imaginary_ * other.getReal();
return Complex(real_part, imag_part);
}
Complex divide(const Complex& other) const {
double denominator = other.getReal() * other.getReal() + other.getImaginary() * other.getImaginary();
double real_part = (real_ * other.getReal() + imaginary_ * other.getImaginary()) / denominator;
double imag_part = (imaginary_ * other.getReal() - real_ * other.getImaginary()) / denominator;
return Complex(real_part, imag_part);
}
private:
double real_;
double imaginary_;
};
int main() {
// 创建两个复数对象
Complex comp1(3, 4);
Complex comp2(1, 2);
// 相加操作
Complex result_add = comp1.add(comp2);
std::cout << "相加结果: " << result_add.getReal() << " + " << result_add.getImaginary() << "i" << std::endl;
// 相减操作
Complex result_subtract = comp1.subtract(comp2);
std::cout << "相减结果: " << result_subtract.getReal() << " + " << result_subtract.getImaginary() << "i" << std::endl;
// 相乘操作
Complex result_multiply = comp1.multiply(comp2);
std::cout << "相乘结果: " << result_multiply.getReal() << " + " << result_multiply.getImaginary() << "i" << std::endl;
// 相除操作
Complex result_divide = comp1.divide(comp2);
std::cout << "相除结果: " << result_divide.getReal() << " + " << result_divide.getImaginary() << "i" << std::endl;
return 0;
}
在上述代码中,我们定义了一个Complex类,其中real_和imaginary_私有成员变量用于表示复数的实部和虚部。
类中定义了getReal()和getImaginary()函数来获取复数的实部和虚部值,并将这些函数声明为const,以确保它们不会修改类的状态。
然后,类中定义了add()、subtract()、multiply()和divide()函数,这些函数接受一个常量引用参数,并返回一个新的Complex对象来表示操作的结果。
在主函数中,我们创建了两个复数对象并进行加减乘除操作,然后打印出结果。
运行上述代码,输出将是:
相加结果: 4 + 6i
相减结果: 2 + 2i
相乘结果: -5 + 10i
相除结果: 2.2 + -0.4i
这样,我们利用了const关键字来确保复数类的成员函数不修改对象的状态,并实现了复数的加减乘除操作。
函数和数组
思考:1.函数如何使用指针来处理数组
答:C++中数组名代表着数组第一个元素的地址
cookies =&cookies[0]
上述代码中函数的调用:
cookies是数组名,代表其第一个元素的地址,因此函数传递的是地址
由于数组是int型,所以参数类型必须是int指针,
即int*,因此函数头还可以写成int sum arr(intarr,intn)
只有在函数头或函数原型中,intarr才和int arr[]等价,它们都意味着
arr是一个int型指针。
2.将数组作为参数意味着什么
上述程序中函数的调用部分,将cookies数组的第一个元素的地址和数组元素
个数传递给了sum arr()函数,
而下一步sum arr()函数又把cookies的地址赋值给arr指针,把Arsizel赋
值给int型变量n,
即,整个程序并没有把数组的内容传递给函数,
而是把数组的地址,元素的数据类型,以及元素的个数提交给了函数
3.指针和const
将consti关键字用于指针有两种方式:
1是让指针指向一个常量对像,可防止使用该指针来修改所指向的值;
2是将指针本身声明为常量,这样可以防止改变指针所指向的位置
例:int age=18;
const int *p &age;
/*该声明说明,p指向一个const
int型变量,
因此不能使用p来修改这个值,
即不能进行以下两种操作:*p+=1;cin>>p;/
思考:以下操作对吗?
*p=30;【错】
age=30;【对】
将常规变量的地址赋值给const:指针,【对】
将const变量的地址赋值给const指针【对】
将const?变量的地址赋值给常规指针【错】
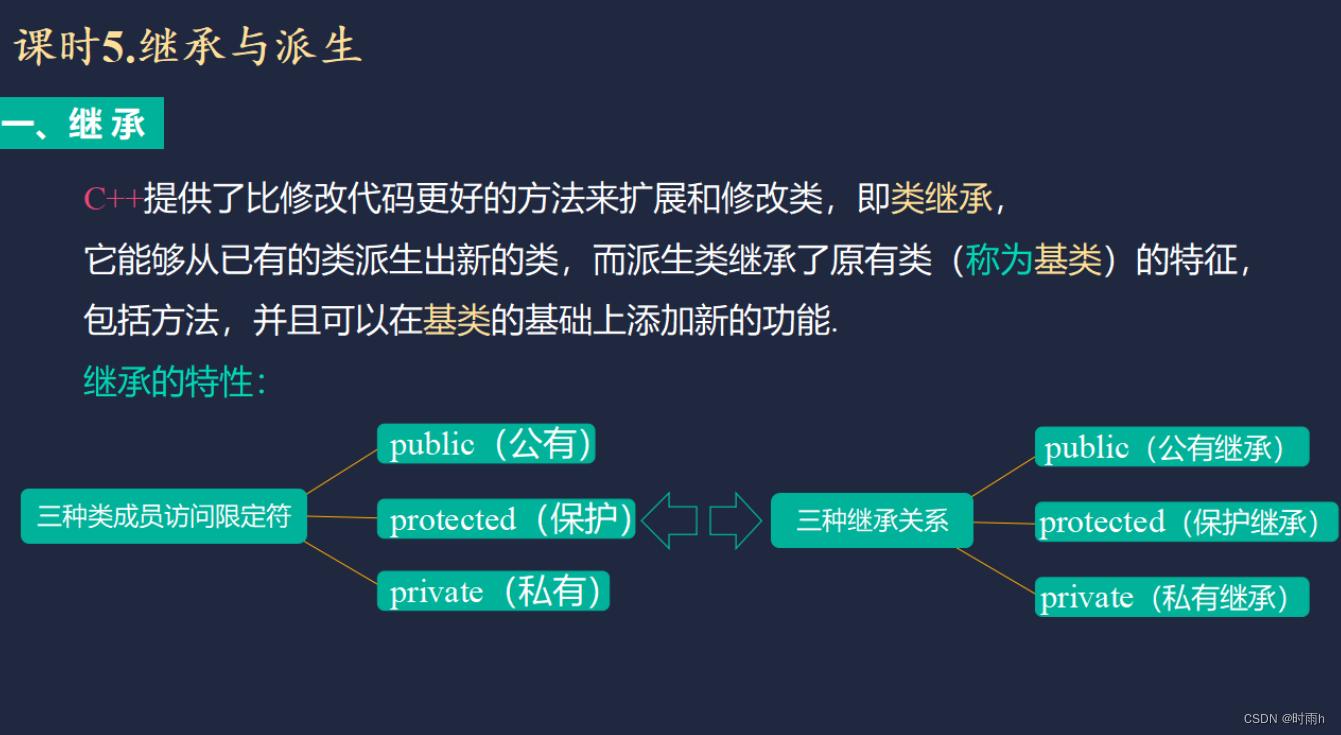
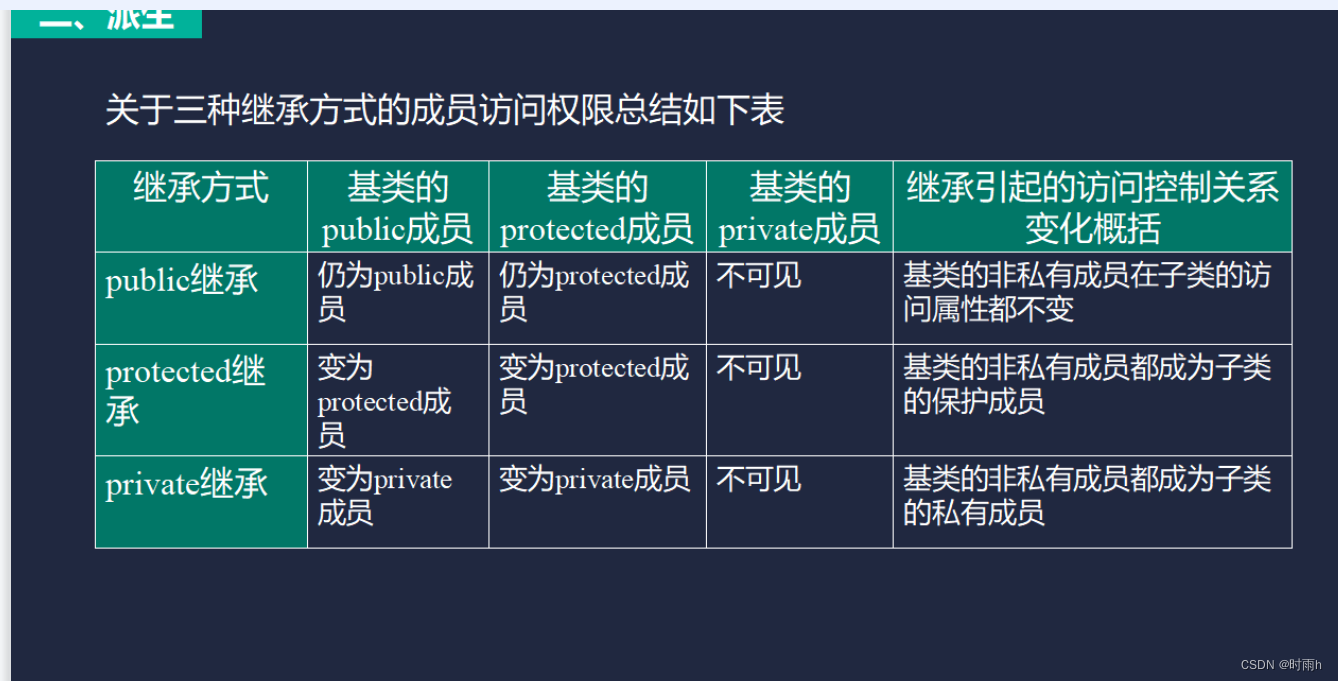
类与继承



课时6.多态性
编译时的多态:函数重载、运算符重载
运行时的多态:虚函数
函数重载和运算符重载
1.相关概念
C++允许在同一作用域中的某个函数和运算符指定多个定义,
分别称为函数重载和运算符重载:
重载声明是指一个与之前已经在该作用域内声明过的函数或方法具有相同名称的声明,
但是它们的参数列表和定义(实现)不相同。



课后练习题(3)
#include <iostream>
using namespace std;
class point {
private:
int x;
static int y;
public:
point(int px = 10) {
x = px;
y++;
}
static int getpx(point a) {
return (a.x);
}
static int getpy() {
return (y);
}
void setx(int c) {
x = c;
}
};
int point::y = 0;
int main() {
point p[5];
for (int i = 0; i < 5; i++) {
p[i].setx(i);
}
for (int i = 0; i < 5; i++) {
cout << point::getpx(p[i]) << '\t';
cout << point::getpy() << '\t';
}
return 0;
}
这段代码定义了一个名为point的类,该类具有私有成员变量x和静态成员变量y。point类还具有构造函数、静态成员函数和非静态成员函数。
构造函数:
- 构造函数带有一个默认参数
px,用于初始化x成员变量。 - 在构造函数中,将
px赋值给x,然后自增静态成员变量y。
静态成员变量y:
- 静态成员变量属于类本身,而不是类的实例。它在类的所有实例之间共享相同的值。
int point::y = 0;语句定义并初始化静态成员变量y为0。
静态成员函数getpx:
getpx是一个静态成员函数,接受一个point对象作为参数,并返回对象的x值。- 在函数体内,通过访问参数对象的
x成员变量来获取其值。
静态成员函数getpy:
getpy是一个静态成员函数,返回静态成员变量y的值。
非静态成员函数setx:
setx是一个非静态成员函数,用于设置x成员变量的值。- 函数接受一个整数参数
c,将其赋值给x成员变量。
在main函数中:
- 创建了一个长度为5的
point类型数组p。 - 使用
for循环,依次将数组p中每个元素的x值设置为对应的下标值。 - 再次使用
for循环,依次输出数组p中每个元素的x值和静态成员变量y的值。 - 输出结果使用制表符分隔。
- 最后,
main函数返回0,程序结束。