数据分析方法
趋势分析法、对比分析法、多维分解法、用户细查、漏斗分析、留存分析、AB测试法、4P理论、PESTEL理论、SWOT分析、5W2H理论、逻辑树理论、用户使用行为理论、AARRR模型
数据指标体系
1. 概述
指标,是反映某种事物或现象,描述在一定时间和条件下的规模、程度、比例、结构等概念,通常由指标名称和指标数值组成.
- 简单计数型指标: 指可通过重复加1这一数学行为而获得数值的指标,如UV(Unique Visit , 独立访客数)、PV(Page View,页面浏览量)
- 复合型指标: 由简单计数型指标经四则运算后得到的,如跳出率、购买转化率, MAU月活跃用户数,CTR=点击UV/曝光UV, 用户留存率=继续的用户/新增用户数,ARPU每用户平均收入
(1)按场景拆分成多个子指标的和
如:DAU日活跃用户 ≈ 日新增用户+留存用户+回流用户;
(2)按一定的关系拆分成多个子指标的积
1)依靠逻辑关系进行指标拆分。如:
- GMV (总消费额,Gross Merchandise Volume)≈ 用户数 x 购买频次 x 客单价;
- 销售额 ≈ 用户总量 x 付费率 x 客单价;
- LTV(生命周期总价值 ,life time value )=LT(生命周期 ,life time)x ARPU(每个用户的平均花费,Average Revenue Per Use)
- 投资回报率(ROI)=年利润或年均利润/投资总额×100%
2)依靠时间先后进行指标拆分。
如:渠道推荐效果 ≈ 展现次数 x 点击率 x 转化率
2. 各行业指标
2.1 广告收费指标:
- CPC:广告单次点击计费
- CPA:按行动(广告实际效果)付费
- CPM (Cost Per Mile)千次曝光成本:总消费/曝光量*1000
三者比较:
- CPM在第一步收取广告费用,即只需要将广告对受众进行了展示,广告主就要付费。
- CPC收取第二步费用,即当用户看到广告后并发生点击行为后,广告主就要付费。
- CPA收取第三步费用,即用户广告后点击了广告,通过进一步了解活动情况后完成某些特定行为,如填表、注册、下载、购买等,广告主就要付费。
2.2 游戏行业指标
ARPPU (Average Revenue Per Paying User) 每付费用户平均收益:
某时间段内平均每个付费用户为应用创造的收入


2.3 零售行业
动销率= 动销品种数 /仓库总品种数
客单价(per customer transaction)= 销售额 /成交顾客数
连带率= 销售总数量 ÷ 销售小票数量 = 平均单次消费的产品数量
售罄率 = 累计销售 ÷ 总进货
3. 指标标度
- Santy的1-9标度方法:两两判断相对重要性
4. 建立指标体系的方法

5. 制作报表
6. 数据报告
- 明确分析目的
- 拆解指标发现问题
- 拆解问题
- 拓展维度探究指标差异
- 撰写报告及美化
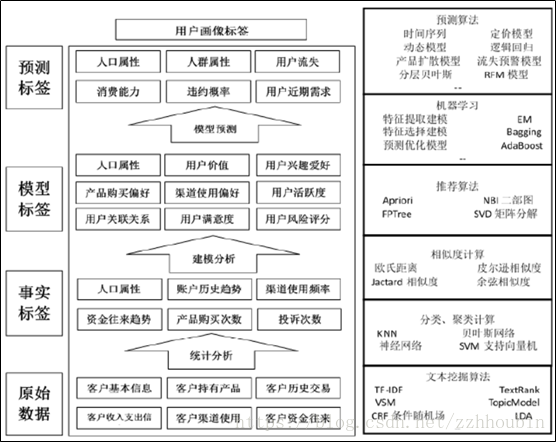
用户画像的指标分析
建立的用户标签按标签类型可以分为统计类、规则类和机器学习挖掘类。从建立的标签维度来看, 可以将其分为用户属性类、用户行为类、用户消费类和风险控制类等常见类型。
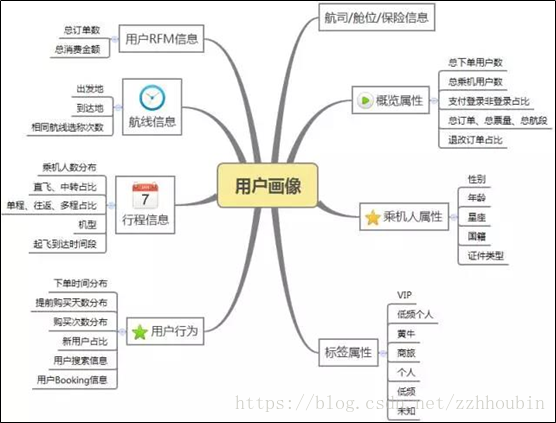
RFM模型
- R:最近一次消费(recency) 代表用户距离当前最后一次消费的时间 反向值 R越大 用户价值越低
- F:消费频次(frequency) 用户在一段时间内,在产品内的消费频次,重点是我们对一段时间的定义 正向值 F越大 用户价值越高
- M:消费金额(monetary) 代表用户的价值贡献 正向值 M越大 用户价值越高
留存分析
留存分析模型 =“留存规则”+“筛选条件”+“表格数据展示”+“可视化数据展示”+“操作”
目标拆解方法——把业务目标变成设计目标

1.行为路径分析法——研究用户行为数据
基于用户的行为路径(用户行为路径即将用户点击浏览的数据可视化而成)来拆解目标,找到设计可发力的环节从而达到目标。
这个方法的难点在于要对业务非常熟悉,需要详细的了解用户所有的路径,通常也可以采用“抓大放小”的方式,整理出用户主路径,对主路径进行研究,暂时放弃子路径。例如用户完成目标G可能需要经历A-B-C-D-E-F这些,整理出每个页面的UV,从而找到中间的漏损最严重的点进行优化。
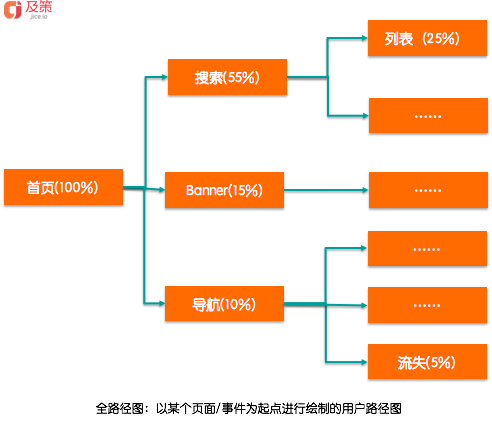
2.公式分析法——较为开放式的方法

3.数据分层法——较为发散式的方法
- 用户路径数据

- 用户画像数据

- 产品数据
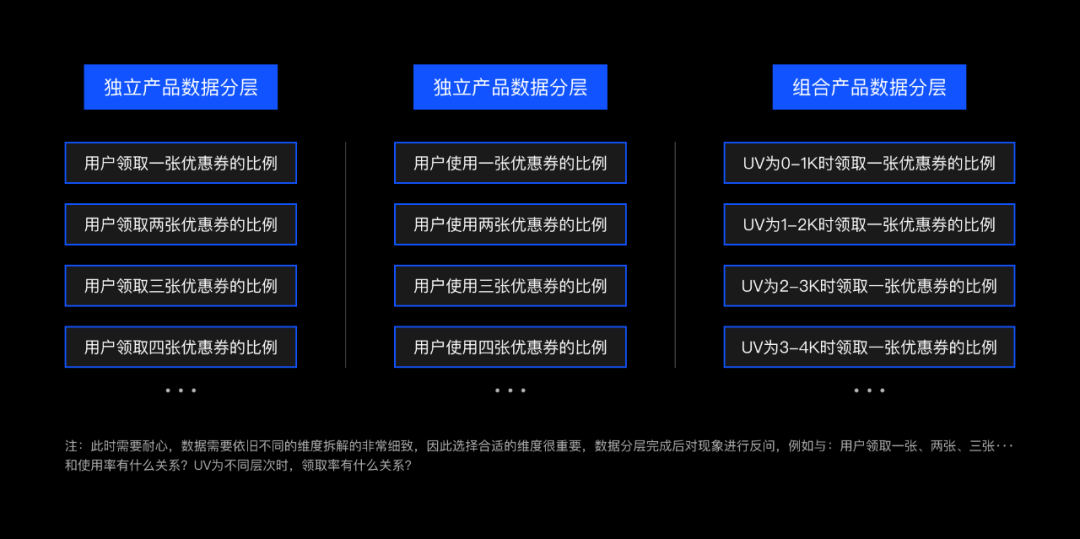
业务分析模型
1. 4P理论模型
Product(产品),Price(价格),Place(渠道)和Promotion(促销)
- 第一个P表示产品,就是说我们要注重产品的功能,要求产品有独特的卖点,把产品的功能诉求放在第一位;
- 第二个P表示价格,我们要根据不同的市场定位制定不同的价格策略,而产品的定价依据是企业的品牌;
- 第三个P表示渠道,强调企业并不直接面对消费者,而是注重经销商的培育和销售网络的建立;
- 第四个P表示宣传,宣传就是指促销活动,比如打折、买一送一等。
2. 波士顿矩阵 (市场增长率-相对市场份额矩阵)
通过销售增长率(反应市场吸引力的指标)和市场占有率(反应企业实力的指标)来分析决定企业的产品结构

企业运营模式
大客户模式、直销模式、分销模式、免费模式、会议营销模式、社群模式、体验营销模式,场景化营销模式,社区模式
分析模型
1. 漏斗分析
漏斗,简单来讲,就是抽象网站或APP中的某个流程,观察流程中每一步的转化与流失。
漏斗的三元素:
- 时间:
漏斗的转化周期,即为完成每一层漏斗所需时间的集合。通常来讲,一个漏斗的转化周期越短越好,尤其是在某些转化周期较长的行业,比如:在线教育行业,B2B电商行业。此外,单独查看每一层漏斗的时间,也能发现一些问题。举例来说,如果发现从某个渠道导入的流量,在某层漏斗的消耗时间惊人的一致,这说明该渠道的流量很可能有异常。 - 节点:
每一层漏斗,就是一个节点。而对于节点来说,最核心的指标就是转化率,公式如下: 转化率 = 通过该层的流量/到达该层的流量
整个漏斗的转化率以及每一层的转化率,可以帮助我们明确优化的方向:找到转化率低的节点,想办法提升它。 - 流量:
流量,也就是人群。不同人群在同一个漏斗下的表现情况一定是不一样的,比如淘宝的购物漏斗,男人和女人的转化率不一样,年轻人和老人的转化率也不一样。
通过人群分类,我们可以快速查看特定人群的转化率,更能清晰定位问题。
1.1 AARRR流量漏斗 又称海盗模型
指的是用户在使用产品前后的整个生命周期中的5个环节。
- 获取用户(Acquisition)
- 提高用户活跃度(Activation)
- 提高用户留存率(Retention)
- 获取收入(Revenue)
- 自传播(Refer)
不同阶段主要的关注指标:
- 日新增用户数
- 注册人数,新手教程完成量,至少用过一次产品的人数,订阅量
- 用户参与度,距上次登录的时间,日/月活跃使用量,流失率
- 客单价(ARPU),付费率(PR或PUR),活跃付费用户数(APA),平均每用户收入(ARPU),平均每付费用户收入(ARPPU)、产品生命周期价值(LTV)
- k因子 K=(每个用户向他的朋友们发出的邀请的数量)×(接收到邀请的人转化为新用户的转化率)
2. 归因模型
准确的描述其实是一种既定的规则,我们需要根据产品的实际需求,将达成目标(形成转化)之前的功劳根据设定的权重分配给每一个转化节点。产品形成一次转化,用户可能要经历很多个转化节点(转化并不一定只完成销售。一次注册也可以看作一次转化,一次访问也可以看作一次转化,要根据业务实际需求制定)。
- 首次归因:适用于品牌没有知名度的公司,关注能够带来客户的最初渠道,对于拓展市场很有帮助;
- 末次归因:适用于转化路径少,周期短的业务,末次归因和首次归因都属于单渠道归因模型;
- 线性归因:将回溯期内所有触点的功劳平均分配,优点是不用考虑不同渠道的权重,各个渠道一视同仁,缺点是有些质量高的渠道可能会被平均;适用于期望在整个销售周期内保持与客户的联系,并维持品牌认知度的公司,这种归因方式,使得各个渠道在顾客的考虑过程中都起到相同的促进作用;
- 时间衰减归因模型:对于统计时间点内的所有触点,距离转化越近的触点贡献越大,适用于客户决策周期短销售周期短的情况;
- 位置归因:该模型重视最初带来线索和最终促成成交的渠道,如果一个公司比较看重这两点,可选择此模型,综合了首次归因、末次归因、线性归因,将第一次和最后一次触点各记贡献40%,中间的所有触点平均剩下的20%贡献;
3. Cohort分析(同期群分析)
Cohort Analysis又叫队列分析,群组分析,是数据分析中常用的一种方法。一般分析过程是将数据分成相同权重,连续的几个部分,然后对每部分数据做相同分析,最后做连续性讨论并得到结果。
举例子来说,分析70后、80后、90后在20岁、30岁、40岁、50岁的收入各是多少;分析每一天的新注册用户在之后N天的留存率等等。

- 商品同期群:商品LTV模型
- 用户同期群:用户留存率模型
- 渠道同期群:渠道质量分析模型
4. AHP层次分析法
层次分析法具有将复杂问题简单化且计算简单等优点,应用十分广泛,诸如在人员素质评估、 多方案比较、科技成果评比和工作成效评价等多领域多方面都有运用。它是多指标综合评价算法,一般有两个用途:
- 指标定权:对某一个决策,(主观)对其因素的重视程度不一,ahp可以实现在无需搜集数据的情况下,给这些指标制定权重
- 量化方案选择:层次分析法可以综合以上5个因素,给这些方案计算得出一个量化得分
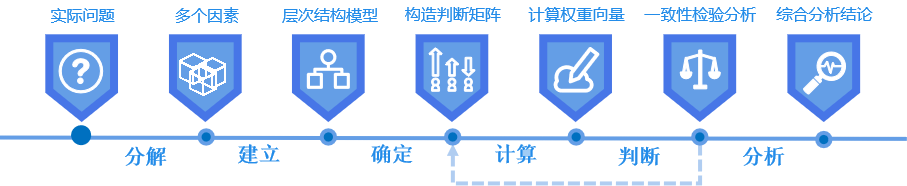

层次单排序核心思想大致分为两步
对判断矩阵计算其权重(权重向量):
- 方根法:每一行连乘后开根,得到的向量进行标准化后即为权重向量
- 和法:先将矩阵的每列进行标准化,然后各元素按行求和,求和结果进行标准化
进行一致性检验:
线代原理
定理1:若A为一致性矩阵,则A的最大特征值λ_max = n,其中n为矩阵A的阶,A的其余特征值均为0。
定理2:n阶正互反矩阵为一致性矩阵,当且仅当其最大特征值λ_max = n,并且当正互反矩阵非一致时,必有λ_max > n。
定义一致性指标 一致性指标CI越大,整个矩阵就越不一致
一致性指标CI越大,整个矩阵就越不一致
根据权重矩阵计算最大特征根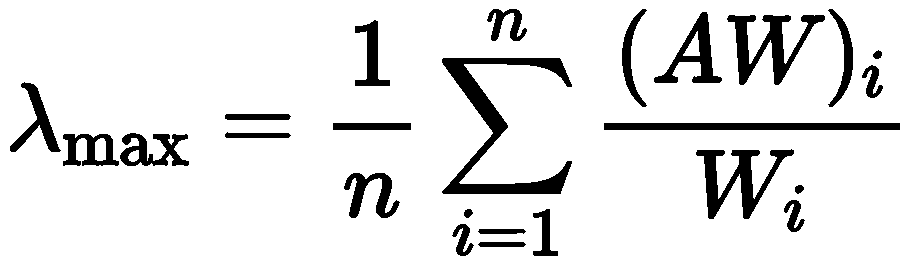 A为判断矩阵,W为标准化后的权重
A为判断矩阵,W为标准化后的权重
然后为了衡量的大小,引入随机一致性指标
,该指标的构建方法是随机构建1000个正互反矩阵,并计算一致性指标的平均值,查表即可

最后计算一致性比例 一般,当一致性比率
一般,当一致性比率时,通过一致性检验
对于层次总排序,

其一致性比例为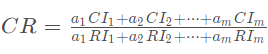
5. 时间序列模型
5.1 AR(p)模型
AR模型全称是Auto Regression,表示自回归,大家应该都知道普通的回归方程,都是用x去回归y,这里的x和y一般不是同一个东西。而我们这里的自回归顾名思义就是用自己回归自己,也就是x和y都是时间序列自己。具体的模型如下:
上面模型中,Xt表示t期的值,当期的值由前p期的值来决定,δ值是常数项,相当于普通回归中的截距项,μ是随机误差.
5.2 MA(q)模型
MA的全称是Moving Average,表示移动平均。具体模型如下:
上面模型中,Xt表示t期的值,当期的值由前q期的误差值来决定,μ值是常数项,相当于普通回归中的截距项,ut是当期的随机误差。MA模型的核心思想是每一期的随机误差都会影响当期值,把前q期的所有误差加起来就是对t期值的影响。
5.3 ARMA(p,q)模型
ARMA模型其实就是把上面两个模型进行合并,就是认为t期值不仅与前p期的x值有关,而且还与前q期对应的每一期的误差有关,这两部分共同决定了目前t期的值,具体的模型如下:
5.4 ARIMA(p,d,q)模型
ARIMA模型是在ARMA模型的基础上进行改造的,ARMA模型是针对t期值进行建模的,而ARIMA是针对t期与t-d期之间差值进行建模,我们把这种不同期之间做差称为差分,这里的d是几就是几阶差分。ARIMA的的具体模型如下:
上面公式中的wt表示t期经过d阶差分以后的结果。我们可以看到ARIMA模型的形式基本与ARMA的形式是一致的,只不过把X换成了w。
当数据是平稳时间序列时可以使用前面的三个模型,当数据是非平稳时间序列时,可以使用最后一个,通过差分的方式将非平稳时间时间序列转化为平稳时间序列。
5.5 ARIMA的步骤
1,对时间序列数据进行绘图,检验数据的平稳性,对非平稳时间序列数据,要先进行差分,直到时间序列为平稳时间序列。
2,对平稳后的数据进行白噪声检验,白噪声是指零均值常方差的随机平稳序列。
3,如果是平稳非白噪声序列就计算ACF(自相关系数)、PACF(偏自相关系数),进行ARIMA模型识别。
4,对识别好的模型,确定模型参数,进行时间序列进行预测,并对模型结果进行评价。
6. 因子分析
主成分分析旨在用变量的线性组合生成同等个数的主成分,然后选择合适的线性组合数量,尽可能保持尽可能多的总体信息;而因子分析旨在根据变量之间的联系,找到共同影响变量的因子,将具有复杂关系的变量转化为少数几个因子从而再现原始变量之间的内在联系,这里的因子是假象的、不可观测的随机变量。
探索性因子分析是先不假定一堆自变量背后到底有几个因子以及关系,而是我们通过这个方法去寻找因子及关系。
验证性因子分析是假设一堆自变量背后有几个因子,试图验证这种假设是否正确。
6.1 步骤
- 将原始数据标准化处理 X
- 计算相关矩阵C的特征值 r 和特征向量 U
- 确定公共因子个数k
- 构造初始因子载荷矩阵,其中U为r的特征向量
- 建立因子模型
- 对初始因子载荷矩阵A进行旋转变换,旋转变换是使初始因子载荷矩阵结构简化,关系明确,使得因子变量更具有可解释性,如果初始因子不相关,可以用方差极大正交旋转,如果初始因子间相关,可以用斜交旋转,进过旋转后得到比较理想的新的因子载荷矩阵A'.
- 将因子表示成变量的线性组合,其中的系数可以通过最小二乘法得到.
- 计算因子得分.
7. 对应分析
7.1 简介
在因子分析中,Q型、R型分析针对的对象不同,R型因子分析研究变量(指标)之间的相关关系,Q型因子分析研究样本之间的相关关系,这两种分析方法往往是相互对立的,必须分别对样本和变量进行处理。(变量是一列,样本是一行)因此,不能同时进行 R型因子分析和 Q型因子分析,这是因子分析的一大局限。
对应分析也称为关联分析、R-Q型因子分析,它克服了因子分析的缺点,综合R型和Q型因子分析的优点,同时对交叉列联表中的行与列进行处理。
利用降维的思想达到简化数据结构的目,寻求以低维图形表示数据表中行与列之间的关系,是特别适合于多分类属性变量研究的一种多元统计分析方法。(广泛应用于市场分析、产品定位、广告研究、社会学等)
8. 杜邦分析 (财务)
杜邦分析(也称为杜邦恒等式或杜邦模型)用于分解股本回报率 (ROE) 的不同驱动因素。使投资者能够单独关注财务业绩的关键指标,以识别优势和劣势。
杜邦分析是一个扩展的股本回报率公式,通过将净利润率乘以资产周转率乘以股本乘数计算得出
推动股本回报率 (ROE) 的三大财务指标:运营效率、资产使用效率和财务杠杆。运营效率以净利润率或净利润除以总销售额或收入来表示。资产使用效率以资产周转率衡量。杠杆以权益乘数衡量,等于平均资产除以平均权益。
杜邦分析法在企业实际财务报表中的应用:
- 首先,企业销售净利率可以反映企业盈利能力的高低。
- 其次,资产周转次数可以反映企业营运能力的高低。
- 再者,权益乘数反映企业偿债能力的高低。
分析工具
1. 热图分析
通过记录用户的鼠标行为,并以直观的效果呈现,从而帮助使用者优化网站布局。
- Mouse Move Heatmap(鼠标移动热图)
- Mouse Click Heatmap(鼠标点击热图)
- Mouse Scroll Heatmap(鼠标滚动热图)
- Link Heatmap(链接热图)
*分析结果检验
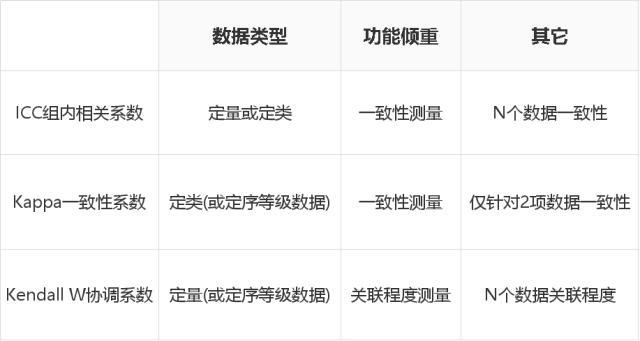
1. 一致性检验
- Kappa检验
- ICC组内相关系数
- Kendall W协调系数
面试题
Ⅰ.数字规律

Ⅱ.使用AB Test评估算法效果(业务题)
1)需求
某个购物APP最近优化了“猜你喜欢”模块的推荐算法,希望进一步提升推荐的精准度,进而提升销售额。现在需要通过AB Test(50%用户保留原先推荐算法的为控制组,50%用户使用新的推荐算法为实验组)来对新的推荐效果进行评估。假设你是此次实验的数据分析师,请问你会如何评估控制组和实验组的表现?请按重要性列出最重要的三个指标并给出你的分析过程。
2)解题思路
指标:推荐商品的销售额、推荐商品点击率、推荐商品的转化率
分析过程:
- 设原假设为使用新的推荐算法后上述指标降低或不变,备择假设为使用新的推荐算法后上述指标增加。
- 选择显著性水平临界值为5%,并根据指标的预期提升确定样本量和试验周期。
- 样本合理分流,AB测试上线,采集数据。
- 使用T检验,计算P值,进行效果验证。
- 分析结论,如果P值小于5%,那么原假设不成立,备择假设成立,即使用新算法后指标提升。反之无法推翻原假设,不能证明使用新算法后指标提升.
产品分析
产品需求文档(PRD)
PRD是对产品需求以实际可落地方式进行细化描述的文档
包含:业务流程图、功能结构图、功能细节描述、界面原型等
竞品分析
通过分析竞争对手的产品,发现痛点,更好地发掘并满足用户需求。
步骤:竞品基础数据管理、竞品流程管理、竞品分析、竞品展示
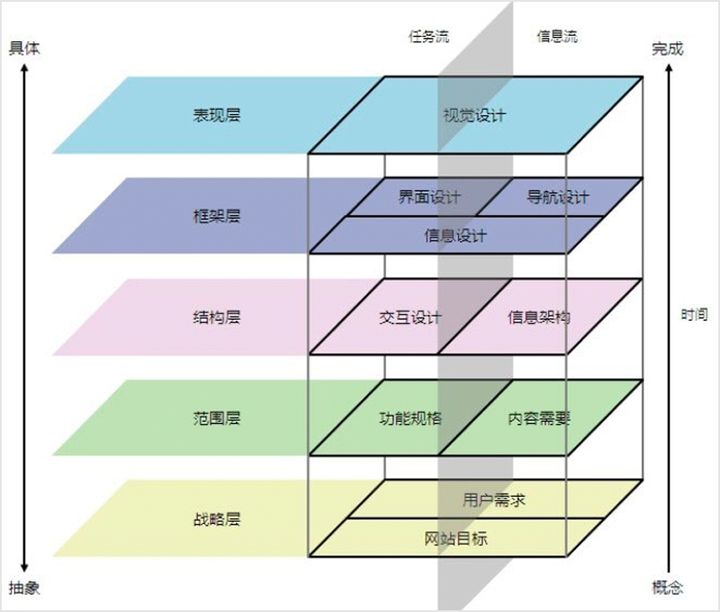
用户体验五要素
ToB和ToC产品区别
| 区别 | ToB | ToC |
| 商业模式 | 基本是签合同,卖产品付费模式 | 免费试用,基本是流量间接变现模式 |
| 使用场景 | 使用场景比较简单,大多数是在办公场景下 | 使用场景多且复杂,利用碎片化和随机性 |
| 业务形态 | 大多数是偏平化功能,可以单独拆分出来售卖 | 一个核心功能为主,产品多维度延伸 |
| 更换成本、用户黏性 | 更换成本高,定制部署周期长,用户粘性较高 | 如果易用性差,体验做不好,用户粘性较低 |
| 产品能力 | 更侧重业务流程逻辑和谈判协调能力 | 更侧重用户模型、交易模型等 |
| 数据分析 | 关注产品市场占有率、服务商户数、续费率等 | 关注产品活跃用户数、用户增长率、转化率等 |
| 与销售团队关系 | 与销售的有强关联,需配合销售 | 没有直接的销售团队,一般是运营团队 |
| 可扩展性 | 可拓展性偏弱,只能实现以点带点 | 可拓展性较强,可以实现以点带面 |
数据采集
代码埋点:APP或网站加载的时候,初始化第三方服务商数据分析的SDK,然后在某个事件发生时就调用SDK里面相应的数据发送接口发送数据。 灵活性强,但人力成本大
可视化埋点:框架化埋点,利用可视化交互手段,业务人员都可以直接在页面上进行简单圈选,以追踪用户的行为(定义事件)。 人力成本小,但灵活性不强。
无埋点(全埋点):开发人员集成采集 SDK 后,SDK 便直接开始捕捉和监测用户在应用里的所有行为,并全部上报,不需要开发人员添加额外代码。 采集的是全量数据。
运营相关
渠道运营:通过一切可以利用的资源和流量为你的产品带来新增的的手段;其中包括免费、付费、换量、人脉积攒、产品的吸引力、圈内人的推荐、策划活动、内容营销、用户口碑等手段都可以是渠道运营的的方向。
References
层次分析法(AHP)原理以及应用_fanstuck的博客-CSDN博客_ahp层次分析法的优缺点
用人话讲明白AHP层次分析法(非常详细原理+简单工具实现)_Halosec_Wei的博客-CSDN博客_ahp层次分析法