目录
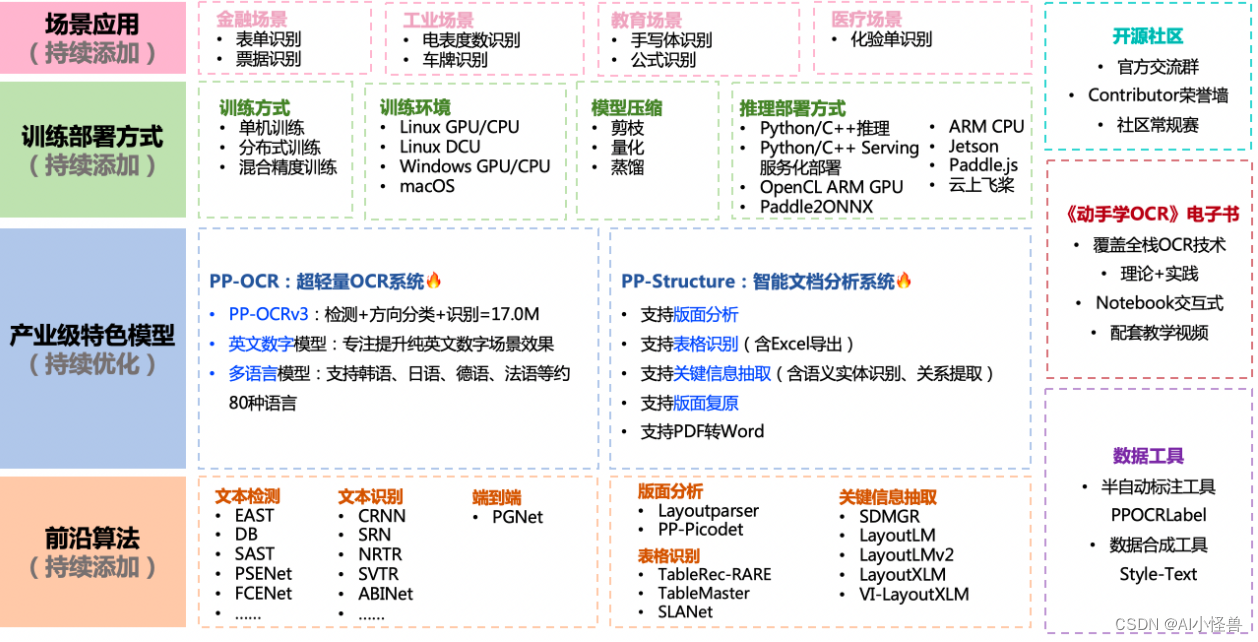
1.PaddleOCR 介绍
PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力开发者训练出更好的模型,并应用落地。

支持多种OCR相关前沿算法,在此基础上打造产业级特色模型PP-OCR和PP-Structure,并打通数据生产、模型训练、压缩、预测部署全流程
1.2 PaddleOCR支持模型介绍

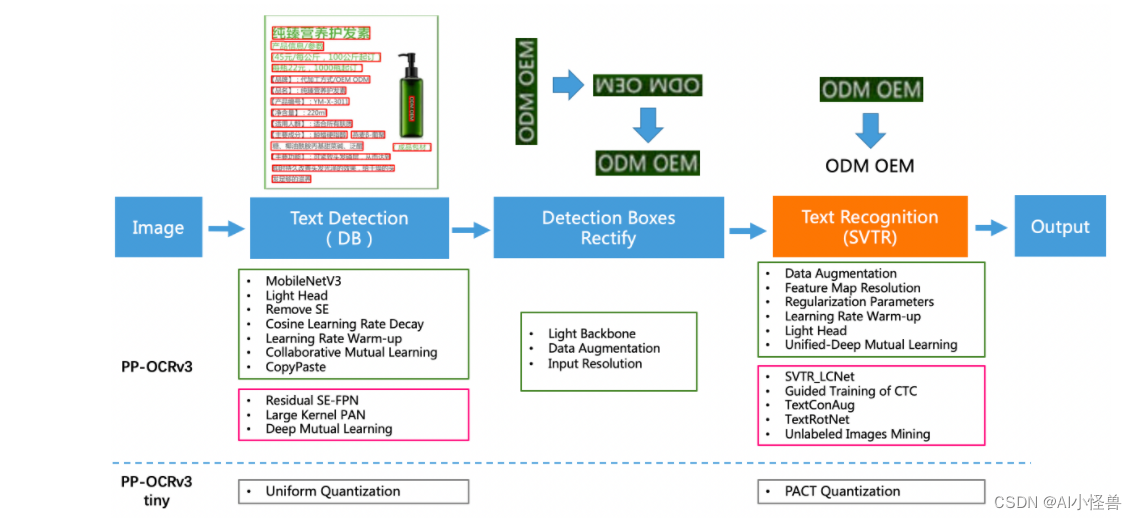
PP-OCRv3在PP-OCRv2的基础上,针对检测模型和识别模型,进行了共计9个方面的升级:
-
PP-OCRv3检测模型对PP-OCRv2中的CML协同互学习文本检测蒸馏策略进行了升级,分别针对教师模型和学生模型进行进一步效果优化。其中,在对教师模型优化时,提出了大感受野的PAN结构LK-PAN和引入了DML蒸馏策略;在对学生模型优化时,提出了残差注意力机制的FPN结构RSE-FPN。
-
PP-OCRv3的识别模块是基于文本识别算法SVTR优化。SVTR不再采用RNN结构,通过引入Transformers结构更加有效地挖掘文本行图像的上下文信息,从而提升文本识别能力。PP-OCRv3通过轻量级文本识别网络SVTR_LCNet、Attention损失指导CTC损失训练策略、挖掘文字上下文信息的数据增广策略TextConAug、TextRotNet自监督预训练模型、UDML联合互学习策略、UIM无标注数据挖掘方案,6个方面进行模型加速和效果提升。
PP-OCRv3系统pipeline如下:
- 超轻量PP-OCRv3系列:检测(3.6M)+ 方向分类器(1.4M)+ 识别(12M)= 17.0M
- 超轻量PP-OCRv2系列:检测(3.1M)+ 方向分类器(1.4M)+ 识别(8.5M)= 13.0M
- 超轻量PP-OCR mobile移动端系列:检测(3.0M)+方向分类器(1.4M)+ 识别(5.0M)= 9.4M
- 通用PP-OCR server系列:检测(47.1M)+方向分类器(1.4M)+ 识别(94.9M)= 143.4M
- 支持中英文数字组合识别、竖排文本识别、长文本识别
- 支持多语言识别:韩语、日语、德语、法语等约80种语言
模型库链接: https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/doc/doc_ch/models_list.md
2.环境配置
2.1在Anaconda3下创建PaddleOCR 环境,根据具体的 Python 版本创建 Anaconda 虚拟环境:
conda create --name paddleocr python=3.82.1.1 进入 Anaconda 虚拟环境
activate paddleocr2.2 安装paddlepaddle
根据cuda版本选择合适的paddlepaddle,飞桨PaddlePaddle-源于产业实践的开源深度学习平台
conda install paddlepaddle-gpu==2.4.2 cudatoolkit=11.2 -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/ -c conda-forge 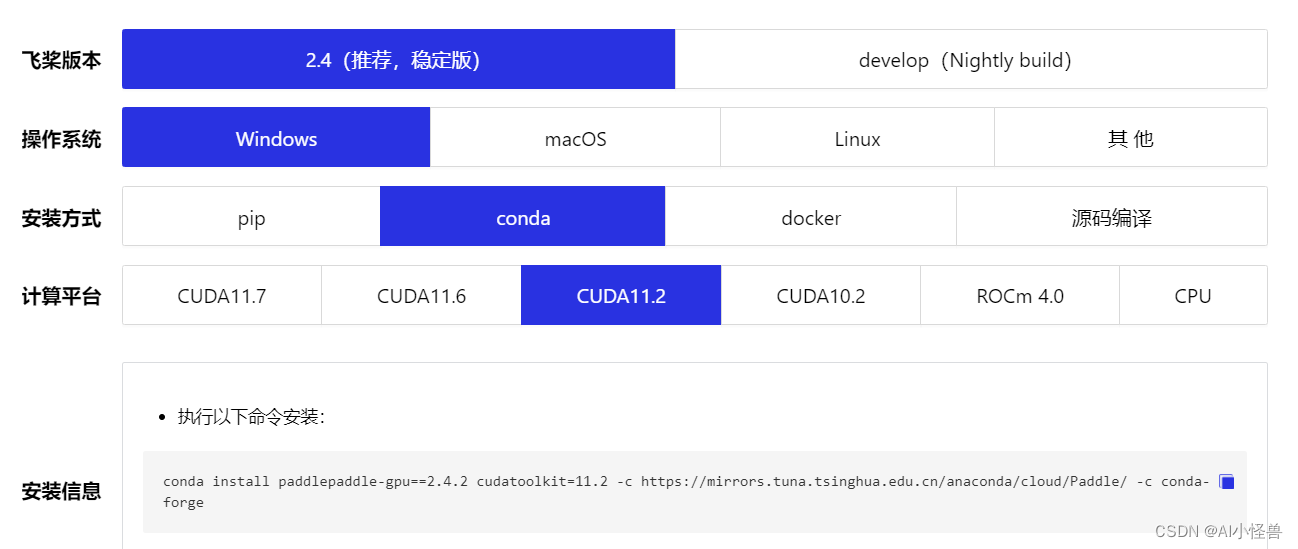
2.2.1 验证安装是否成功
使用 python 进入 python 解释器
import paddle
paddle.utils.run_check()3.PaddleOCR源码
源码下载链接:
https://github.com/PaddlePaddle/PaddleOCR进入cd PaddleOCR-release-2.6
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple3.1 验证是否配置成功
# 下载超轻量中文检测模型:
https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar
python tools/infer/predict_det.py --image_dir="./doc/imgs/11.jpg" --det_model_dir="model/ch_PP-OCRv3_det_infer/"

