前言
接上篇博文的总结,本篇博客来总结简答题和编程题。
一、简答题
1、简述python中利用数据统计方法检测异常值的常用方法及其原理。
答:①散点图:通过散点的分布,可以观察出偏离拟合模型的异常数据点;②箱线图:大于上限max,小于下限min的为异常值。
③3σ法则:在正态分布的假设下,距离平均值3σ之外的值出现的概率小于0.003.因此根据小概率事件,可以认为超出3σ之外的值为异常数据。
2、简述数据分析与数据挖掘的区别与联系。

3、简述pandas删除空缺值方法dropna中参数thresh的使用方法。
答:dropna中的参数thresh当传入thresh=N时,表示要求一行至少具有N个非NaN才能存活。
4、简述数据分析中要进行数据标准化的主要原因。
答:不同特征之间往往具有不同的量纲,由此造成数值间的差异很大。因此为了消除特征之间量纲和取值范围的差异可能会造成的影响,需要对数据进行标准化处理。
5、简述pandas中利用cut方法进行数据离散化的用法。
答:将数据的值域分成具有相同宽度的区间,区间个数由数据本身的特点决定或由用户指定。pandas中提供了cut函数,可以进行连续型数据的等宽离散化。
二、编程题
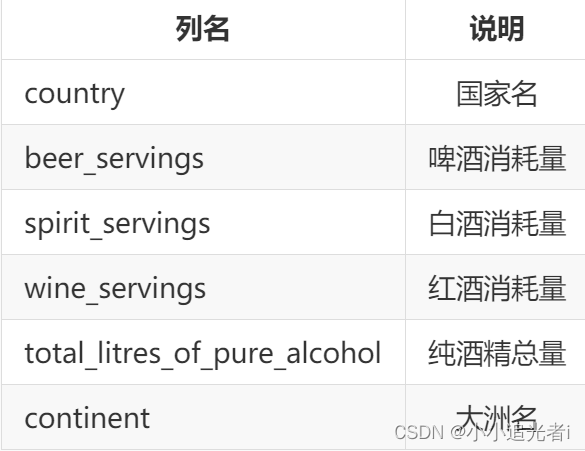
1.使用Pandas中的read_csv()函数读取step1/drinks.csv中的数据,数据的列名如下表所示,请根据continent分组并求每个大洲红酒消耗量的最大值与最小值的差以及啤酒消耗量的和。
代码如下:
import pandas as pd
import numpy as np
def sub(df):
return df.max()-df.min()
def main():
data=pd.read_csv("step1/drinks.csv")
df=pd.DataFrame(data)
mapping={
"wine_servings":sub,"beer_servings":np.sum}
t1=df.groupby("continent").agg(mapping)
print(t1)
if __name__ == '__main__':
main()
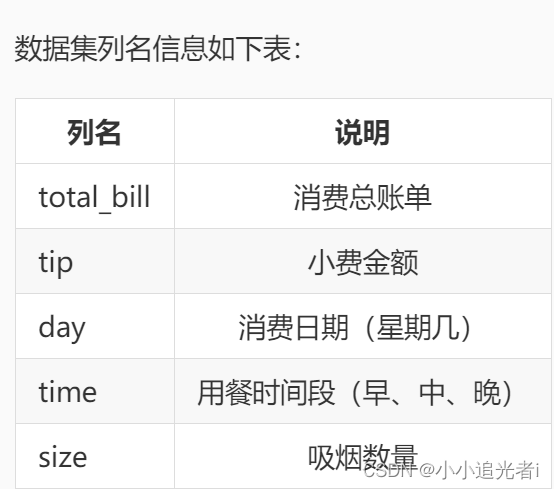
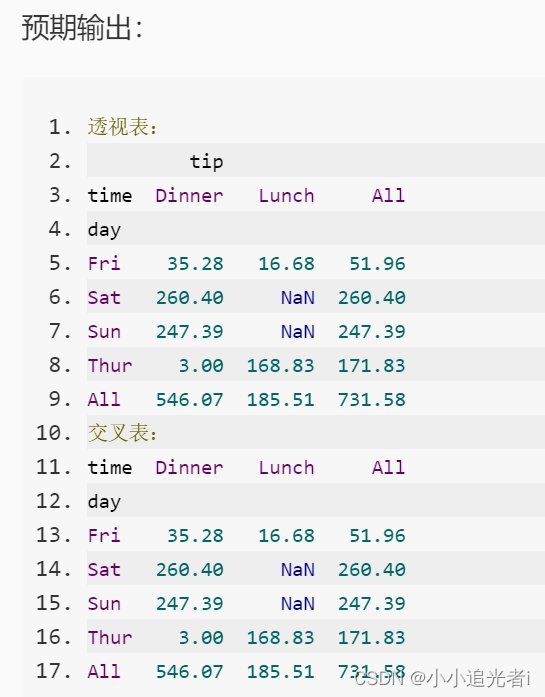
2、使用Pandas中的read_csv函数加载step2/tip.csv文件中的数据集,分别用透视表和交叉表统计顾客在每种用餐时间(time) 、每个星期下(day) 的 小费(tip)总和情况。
import pandas as pd
#创建透视表
def create_pivottalbe(data):
return data.pivot_table(index=["day"],values=["tip"],columns=["time"],margins=True,aggfunc=sum)
#创建交叉表
def create_crosstab(data):
return pd.crosstab(index=[data.day],columns=[data.time],values=data.tip,aggfunc=sum ,margins=True)
def main():
#读取csv文件数据并赋值给data
data=pd.read_csv("step2/tip.csv")
piv_result = create_pivottalbe(data)
cro_result = create_crosstab(data)
print("透视表:\n{}".format(piv_result))
print("交叉表:\n{}".format(cro_result))
if __name__ == '__main__':
main()
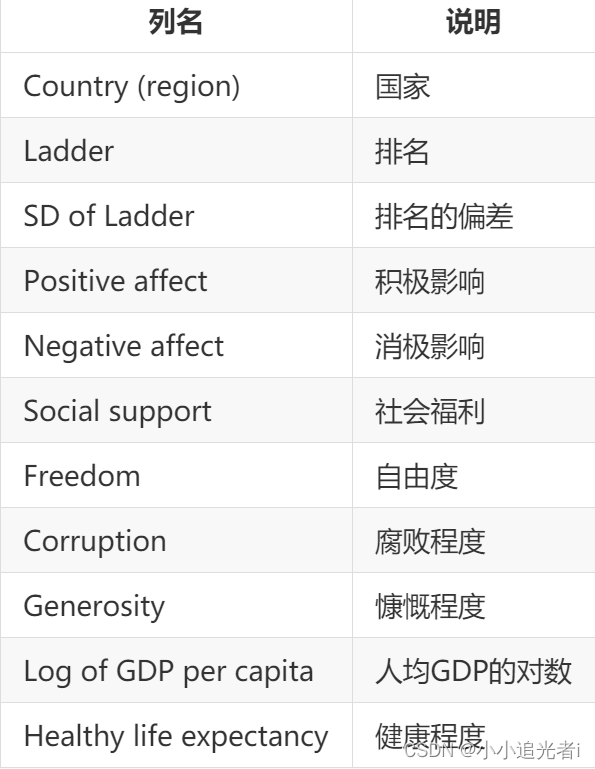
3、data.csv和data1.csv是两份与各国幸福指数排名相关的数据,为了便于查看排名详情,所以需要将两份数据横向合并。数据列名含义如下:

import pandas as pd
def task1():
data=pd.read_csv('step1/data.csv')
data1=pd.read_csv('step1/data1.csv')
result=pd.concat([data,data1],axis=1)
result=result.T.drop_duplicates().T#删除重复的列
result.index.name='Ladder'
result=result.fillna(0)
return result
4、
预期输出:
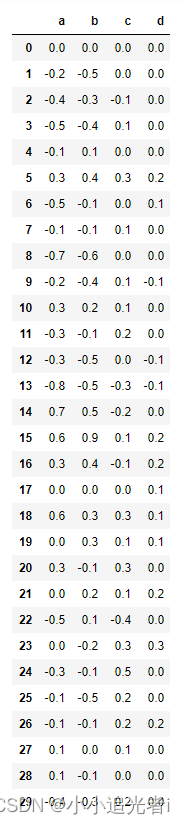
import pandas as pd
from sklearn import datasets
def demo1():
iris = datasets.load_iris().data # 鸢尾花数据集,返回的是array
t=iris[:30,:]
pd1=pd.DataFrame(t,columns=['a','b','c','d'])
print(pd1-pd1.iloc[0])
5、
预期输出:

import numpy as np
import pandas as pd
from sklearn import datasets
def demo3():
iris = datasets.load_iris().data
p=pd.DataFrame(iris,columns=list('abcd'))
t=p.head(30)
t=t.sub(t.iloc[0])
t[t<0]=np.nan
t=t.dropna(axis=0,thresh=2)
print(t.fillna(method='ffill'))
总结
这篇博客接着上篇博客继续总结,主要围绕简答题和编程题。若要查看选择题和判断题,请大家移步上篇博客。
如果本篇文章对大家有帮助,请大家点赞+收藏,您的支持是我继续创作的最大动力!