Z Lab数据实验室成员 HeapOverflow
01
前言
去年又摸了一个比赛,这次基本上是自己主导完成大部分建模和优化工作的了。这次能拿下第一,一方面是比赛参加的人比较少(也是因为限制学生参加)来卷的大概也就几十个人,另一方面也是选对了方向+运气比较好。尽管如此,打榜的时候一直在面对后面几个佬的穷追猛打,还是有一些慌,最后能守住第一也实属不易。(或者说基本上真在做比赛的时间也就在搞做不出来的论文中间穿插两三周左右,其他时间基本都在慌明天第一会不会换人)
是的这已经是个去年的比赛了,线上评测11月结束,一直到最近5月份才决赛答辩确定结果,中间隔了近半年的时间。这个比赛开始时,还没有ChatGPT,结束的时候ChatGPT已经人尽皆知,笑了。
比赛网站:aicontest.msxf.com/nlp
02
赛题与数据分析
A
赛题简介


首先抄袭一段比赛官网的赛题说明:数字人新闻播音员是数字人的一个主要应用场景,基于关键新闻素材(如时间、地点、人物、事件等)生成一段通畅、易读的资讯新闻是数字人领域的一大挑战。这一技术可以大幅度节约新闻工作者的重复工作量,增加新闻采访、深度报道等创造性工作投入。
简单来说就是:输入新闻标题和若干个关键短语,要求输出新闻内容全文。
但是需要注意的是,主办方限制模型大小(文件大小)在500M以内,基本上稍大一些的模型都用不上,也没办法做模型集成了。
赛题给出的数据集包括三个字段:
ID:文本ID
Elements:新闻素材,包含新闻标题和由“#”符号分隔的若干关键短语
News:新闻内容全文,是我们需要预测的对象
e.g. (原文件为CSV,转成JSON方便展示):
{
"ID": "TR000001",
"Elements": "零壹智库|150份报告!把脉保险数字化及保险科技创新与发展[SEP]科技#大数据#人工智能#等为代表#推动#传统保险业加速数字化转型#科技投入#增加#保险业态#创新产品#吸引#资本#零壹智库报告显示#达到顶峰#中国市场#2020年三#保险科技投融资金额#2021年#全球#维持#高位#达到120.5亿元#中国保险业",
"News": "科技与金融的融合正在加速。以大数据、人工智能、生物科技、区块链、物联网等为代表的技术不断成熟,推动了保险科技的蓬勃发展。一方面,传统保险业加速数字化转型,科技投入不断增加;另一方面,新型的保险业态应运而生,创新产品层出不穷,并吸引了各种资本的角逐。零壹智库报告显示,2020年全球保险科技领域融资金额出现井喷,达到276.2亿元创历史新高,特别是在2020年下半年达到顶峰,巨额融资频现。在中国市场,2020年三四季度保险科技投融资金额平稳在16亿元左右。2021年第一季度,全球及中国保险科技股权融资规模继续在维持在高位,分别达到120.5亿元和18.7亿元。中国保险业巨大的市场空间,为保险科技的发展提供了良好的市场基础。"
}评价指标:Rouge-L,不展开了。
很显然,这是一个典型的序列到序列(Seq2Seq)文本生成任务。
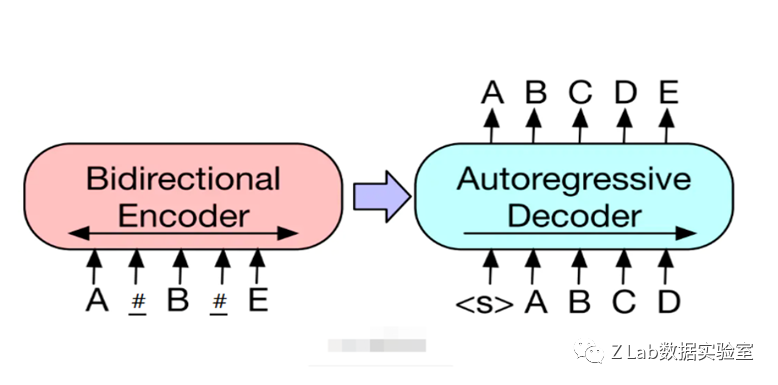
本赛题的Seq2Seq生成任务(直接拿BART的图改了改)
B
数据分析

首先去除训练集中一些没有内容的脏数据。然后针对新闻素材长度、新闻全文长度、新闻素材数量等特征进行一些简单分析。
下图是训练集中新闻文本长度的频次图,横坐标表示新闻内容的长度,纵坐标表示对应长度新闻出现的次数。
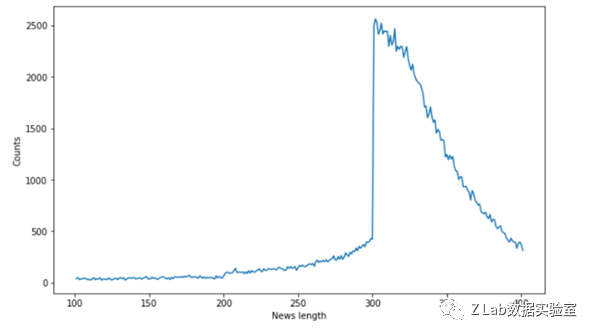
新闻长度频次图
可以看出大部分新闻的长度都在300-400字之间。
下两图是训练集和测试集中新闻标题(Elements中根据[SEP]划分后的第一段)长度分布。
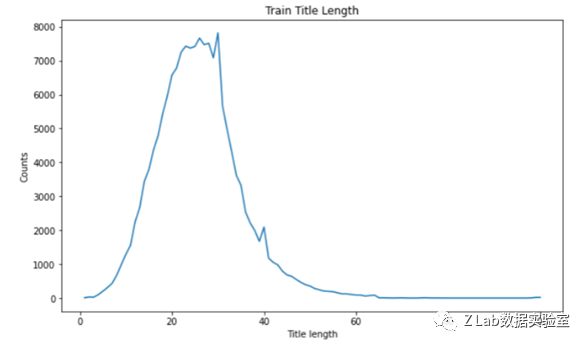
训练集新闻标题长度分布
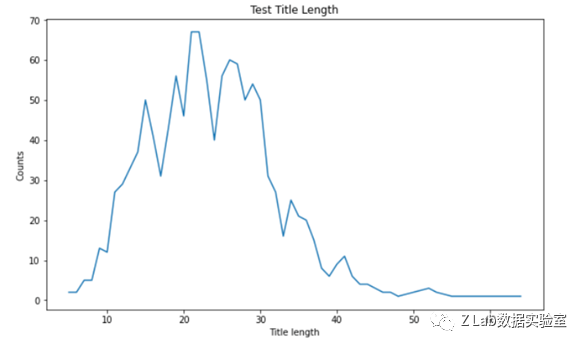
测试集新闻标题长度分布
可以说明训练集和测试集标题长度基本一致。
下两图是训练集和测试集中新闻素材(Elements中根据[SEP]划分后的第二段)个数分布。
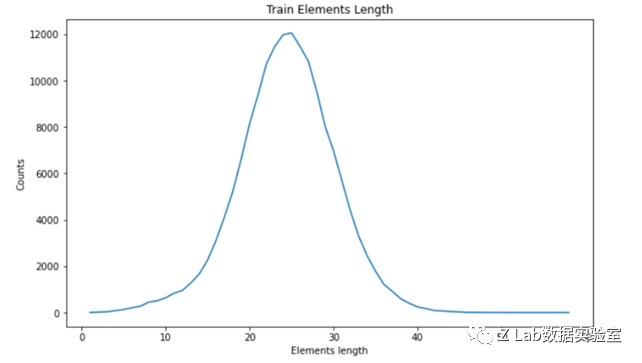
训练集新闻素材个数分布
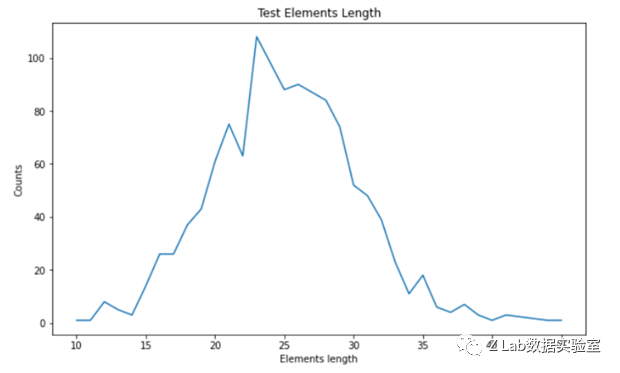
测试集新闻素材个数分布
可以看出训练集和测试集新闻素材个数基本一致。
简单分析赛题和数据后可以得到如下结论:
本题不是from-scratch式的文本生成任务,更接近于文本扩写任务
本题文本长度不算短,属于中长文本的生成任务,所以长文本生成该有的问题都会有
训练集和测试集之间没有发现明显的分布偏差,可以认为应该是同分布的,不需要额外考虑领域适应的问题
03
基础模型选用
该任务是一个Seq2Seq任务,因此适合使用Encoder-Decoder架构的模型。我们决定使用中文预训练的BART模型,这是因为BART的预训练任务和本赛题的任务相当接近。BART的预训练任务去噪自编码器(DAE),即输入一段通过片段增加、删除、掩蔽、乱序等方式添加了噪声的文档,训练模型来还原出原始的文档。本赛题其实就相当于从原始文本中掩蔽了一些片段,要求模型完整还原被掩蔽掉的片段,同时尽量保证文本的流畅性。(甚至我上面任务说明的图都是用BART改的)
为什么不使用GPT等Decoder模型:不适合扩写任务,强行使用估计要大1个数量级以上的参数才能达到相同效果。
为什么不用中文T5:T5的无监督训练任务和BART思想一致,但做法有一些差别。T5预训练中会随机MASK一些Span,但在Decoder端只需要模型输出被MASK的部分而不是像BART一样让模型输出完整的原始文本。因此BART的任务形式和本题更为接近。(当然,T5其实不是不能用,只要把任务改造成类似T5的填空任务形式就好了,但想了想会有些很麻烦的细节问题所以就没用这个方案)
具体到模型,我们选用了IDEA研究院开源的封神榜系列模型中的139M参数量的“燃灯”中文BART模型,半精度格式保存的模型文件大小278M,符合比赛要求。
实际上,我们也比较了几种不同的预训练模型,包括mT5-small,复旦ChineseBART,燃灯T5,燃灯BART。线下比较的结果是燃灯BART > 复旦ChineseBART > 燃灯T5 > mT5-small。
BART和T5的比较已在上面说明,但为什么燃灯BART比复旦BART效果好,我个人无责猜测:燃灯BART使用的是类似T5的Tokenizer,使用SentencePiece分词机制,Tokenize的结果是字词混合的;而复旦BART使用BertTokenizer,对中文Tokenize的结果是按字切分。所以燃灯BART输入的文本长度其实会比复旦BART输入的文本短一些,而且新闻文本很多也是常见词组合,词组的稀疏问题也不明显,文本长度短就减少了对长文本建模的压力。
04
优化思路与方法
主要是一些简单有效的改进点,拒绝花里胡哨。
A
词表扩充

经过对实验结果和模型词表的分析,我们发现各个预训练模型使用的Tokenizer都缺失了一部分常用的中文字符,主要是一些常见的中文标点符号(复旦BART和燃灯BART的词表都缺了很多全角中文标点,但复旦后来更新了中文BART的词表应该没有这个问题了)。如果不对词表进行扩充的话会对训练和生成的过程造成很大的影响。
扩充词表对结果影响比较大,是关键的上分点(当然,也可以考虑把训练集中不在词表里的标点符号映射到在词表里的,后处理的时候再映射回去)。
B
对Decoder端输入的随机替换

曝光偏差(Exposure Bias)是生成模型中老生常谈的问题。训练过程中使用Teacher Forcing的方式并行训练,Decoder端的输入和输出只差别一个Token的Shift,训练每一个Token的时候模型看到的上文都是正确答案,然而推理过程模型依赖的上文是模型自身生成的结果,如果模型前面生成错了,就容易把自己带到沟里去,引起误差传播的问题。
所以有一个大家都知道的简单方法来缓解曝光偏差问题:在构造训练样本时随机选取Decoder端输入的一部分Token,将其替换为其他随机Token,模拟生成过程中出错的情况。
当然,也有更复杂的替换策略,比如首先随机选取替换多少个Token,然后再选取要替换的位置,或者替换的时候一部分Token选择替换为输入序列中存在的Token模拟重复生成的情况,不过这里我就没有考虑。
明显上大分。

随机替换示例
C
数据清洗与后处理

数据清洗:
删除了标题和素材文本过短的数据以及新闻原文过短的数据。
发现部分训练数据中存在大量的“.”符号,可能是爬取中出现的分隔符,将过多连续的“.”删除掉以避免对模型训练带来影响。
后处理(主要还是弥补模型生成能力不够的问题,上了小分):
将生成出的繁体文本转化为简体。
去除一些形如“ID:XXX”等与训练集中的特定作者相关的信息(这些信息在测试集中应该是不正确的)。
将多次重复的短语(2-gram及以上)替换为一次。
对部分标点符号进行规范化。
后处理示例:
“同比下降同比下降30.6%。”->“同比下降30.6%。”
“文丨志钛媒体(ID:pedaily2012)”->“文丨志钛媒体”
D
指针式生成网络(Pointer-Generator Network)

PGN是前BERT时代提出的一个经典方法了。在这个方法中,模型一方面通过指针(Pointer)从源文本中复制Token,增强模型忠于原文的程度,另一方面保留了生成模型(Generator),可以生成源文本中没有的Token以保证输出的流畅性。在原文中,Pointer部分利用的是生成过程中Cross Attention部分的权重。另外,文中还提出了Coverage机制来追踪已复制的Token,减少重复复制的问题。
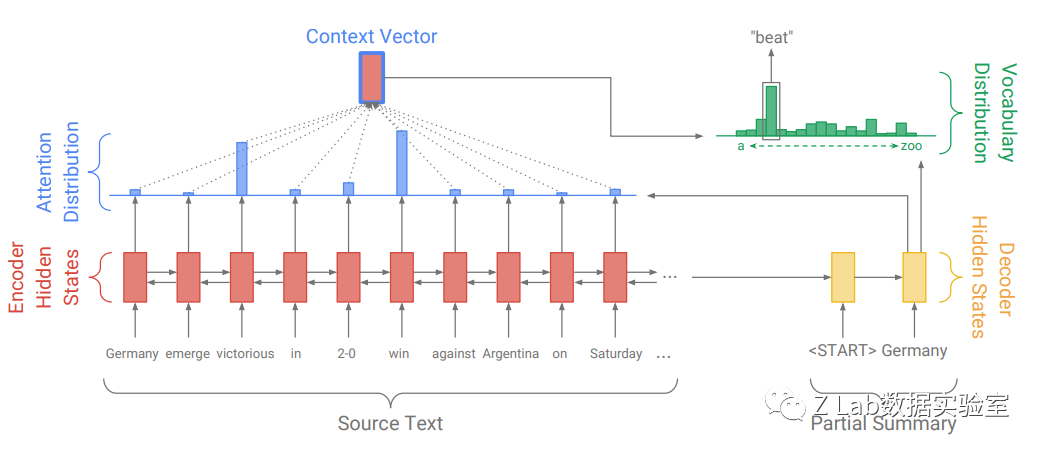
Pointer-Generator Network
考虑到本任务需要模型生成时也与输入的新闻素材保持一致,所以实现了基于BART的指针式生成网络。参考之前为数不多的实现,我们使用了一个额外的Attention网络来计算对原文进行复制的概率(而非模型中已有的Attention层)。对于Coverage机制,串行地计算Coverage向量实在是太慢了(10倍时间以上,只适合RNN时代的模型),所以我偷懒地实现了一个并行版本的Coverage,即训练过程中直接对所有Token的复制概率平方求和(相当于惩罚所有概率都集中到很少Token上的情况)。
有可能是因为我写得比较垃圾,所以只有微小的提升(不能排除随机影响的那种提升)。
05
没什么用的尝试
FGM对抗训练:训练过程中对Embedding层加入基于梯度的扰动以增强模型的鲁棒性,线下降低
Child Tuning:每次梯度更新时只更新一个随机子网络,相当于梯度正则化减少过拟合,线下无提升,可能是因为本题训练过程过拟合问题不突出
EMA指数滑动平均:训练过程中复制一份备份权重,梯度更新模型权重时对备份权重进行指数滑动平均更新,训练结束后用备份权重替换模型权重,使模型训练更平滑,线下无提升
基于BERT和对比学习的结果重排序(SimCLS):使用生成模型对每个输入生成多个输出样本,使用对比学习训练BERT模型进行排序,并用于推理过程选择生成模型生成的候选样本,线下效果降低(炸了),排序模型选择不出最优结果。大概率是因为这个中长文本生成问题中生成出的不同样本之间太相似了,而生成结果和输入之间又太相似了,直接让BERT歇逼了,而SimCLS原文中的摘要生成任务,要生成的摘要都很短,不同的生成结果之间差异比较大,所以重排序方法能取得较好的增益。
06
实验细节及测评结果
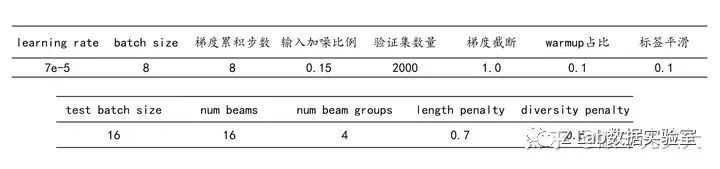
Loss函数:交叉熵带标签平滑
优化器:AdamW
学习率调度:Warmup + Cosine Decay
梯度累积(Gradient Accumulation), 梯度截断(Gradient Clipping)
解码方法:Diverse Beam Search 替换普通Beam Search(没完全想通这为什么能涨点,有可能是因为Diverse可以同时生成多个有差异的序列,最后再挑一个好的,相当于扩大了模型的选择空间?)
调参:随便调了调,差不多就行了
训练和推理中使用的超参数:
超参数
线上评测A榜、B榜、决赛答辩均为第一名,线上指标超过第二名0.3%+。
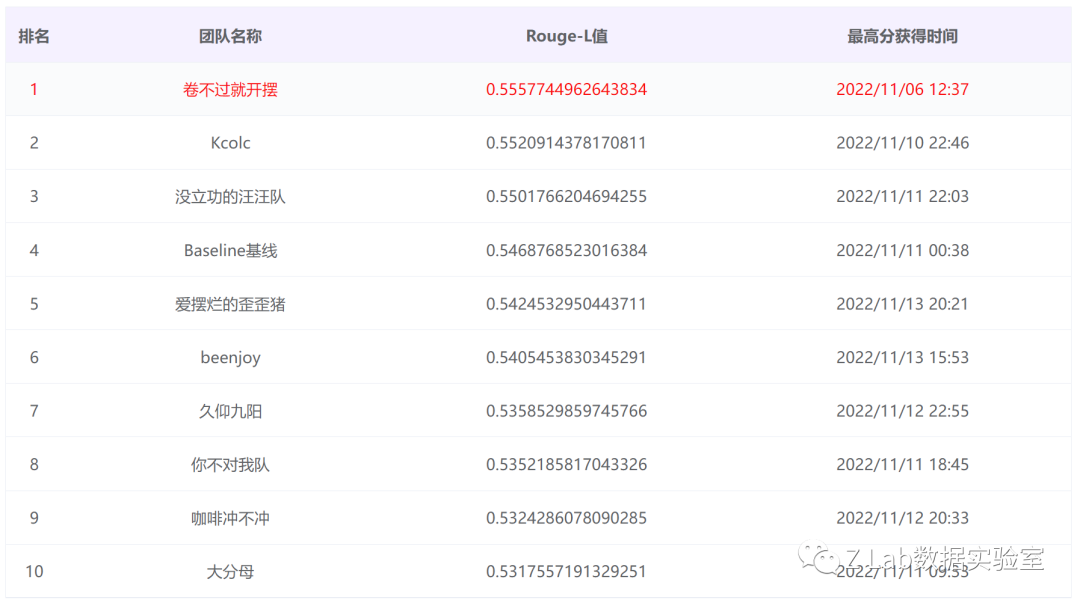
A榜
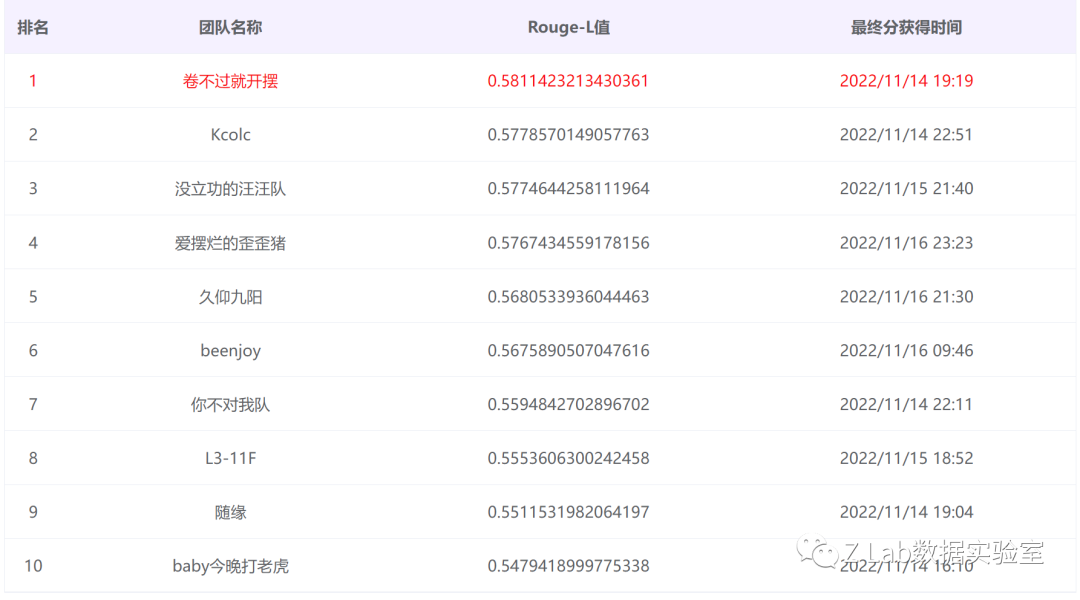
B榜
07
总结与思考
本次比赛中我们使用的核心技术点:
选用“燃灯”中文BART模型作为Seq2Seq基础模型
对预训练模型的词表进行扩充以更好地适应新闻语料的性质
训练过程中对Decoder输入端进行随机加噪,以减少推理过程中的曝光偏差
对训练数据集和推理预测结果分别设计规则进行了适当的前处理和后处理
尝试引入指针式生成网络等模型结构来改善模型忠实原文的程度(虽然最后作用不大)
但其实最后实际生成的新闻,效果只能说勉强能看,流畅性问题不大,但逻辑性、连贯性、事实性等都存在不少问题,很大程度是由于模型参数量和数据量都不够导致的,但方法本身也还有一些改进空间。
针对比赛本身,还可以考虑的改进方向:
改进解码方法:引入对比搜索解码(Contrastive Search Decoding)等更先进的解码技术,进一步减少Degeneration的问题
改进曝光偏差:增加对比学习、预测未来K个Token等其他更复杂的训练方法继续减少曝光偏差问题
改进Copy机制:可能我的PGN目前写得有点垃圾
如果是针对实际的应用场景,改进的方向:
增加模型参数量
增加数据量
没了,大部分花里胡哨其实都没啥用