
论文:《SFPN: SYNTHETIC FPN FOR OBJECT DETECTION》
链接:https://arxiv.org/pdf/2203.02445.pdf
代码:https://github.com/nguyendinhson-kaist/MMSports23-Seg-AutoID
导读
本文集中讨论了在 CV 领域中的一个长期存在的问题,即遮挡问题,尤其是在实例分割任务中。相信不少小伙伴都或多或少会碰到这个“棘手”的问题,今天我们一起根据文章的脉络来观摩学习下。
本文的背景是 ACM MMSports 2023 DeepSportRadar 竞赛,该比赛中公开了一个开源数据集,专注于在篮球场景中对人体进行分割,并引入了一种专门用于遮挡场景的评估指标。鉴于数据集的规模相对较小,并且要分割的对象具有高度可变的特性,因此这个挑战需要应用强大的数据增强技术和合适的深度学习架构。
当然,既然能被介绍到,肯定是取得了优异的成绩。本文的工作在本次竞赛中排名第一,首次提出了一种新的数据增强技术,能够生成更广泛分布的训练样本。然后,他们采用了一种新的深度学习架构——混合任务级联(Hybrid Task Cascade,HTC)框架,并使用 CBNetV2 作为骨干网络和 MaskIoU 头来提高分割性能。此外,团队采用了随机权重平均(Stochastic Weight Averaging,SWA)的训练策略来提高模型的泛化能力,当然都是非常常规的比赛 trick。最终,他们在竞赛数据集上实现了显著的遮挡分数(OM)为0.533,占据了排行榜的第一位。
可喜可贺的是,文中还提供了源代码的链接,大家不妨点开来看看,看了下是基于 OpenMMLab 生态框架搭建的。
背景
实例分割的应用领域非常广泛,包括自动驾驶、医学图像分析和今天介绍的体育分析等。实例分割的老帮主便是大家熟悉的 Mask R-CNN,后面从 ViT 出来后就慢慢衍生出 MaskFormer 为代表的系列模型了,可以通过注意机制从图像中获得丰富且有意义的特征表示。
尽管近年来有了很多进展,但实例分割仍然面临两个主要挑战:
- 识别由于因素如姿势或角度改变而导致的物体形状变化(变形);
- 识别部分或完全隐藏在其他物体后面的物体(遮挡);
当然,这些复杂性不仅在实例分割中存在,还在相关领域如目标检测和图像分类中出现。另一方面,传统的 COCO 度量指标依赖于 IoU(交并比)值,用于比较模型预测与地面真实值在目标检测和分割任务中的一致性。然而,这些度量标准可能不足以满足遮挡场景下模型性能的评估需求。
因此,为了应对这一问题,ACM MMSports 2023竞赛引入了一种新颖的专门用于遮挡场景的评估指标,称为遮挡度量(OM),挺有意思的。OM 指标主要关注由于遮挡而部分可见的实例,这是由 GT 标注验证的。OM指标强调重新连接遮挡像素。该指标通过两个组成部分的乘积来计算,即遮挡实例召回(OIR),用于测量视觉上分割的实例的召回率,和断开像素召回(DPR),用于评估与这些分割实例的主要结构分离的像素的召回率。
这里提一嘴,由于竞赛的主要目标是在篮球场上对人体主体进行分割,包括球员和裁判可能重叠的情况。鉴于只有324个训练图像的数据集,这个竞赛组织者向所有参与者提出了一个极具挑战性的任务(避免大力出奇迹现象)。好了,话不多说,下面我们一起看看本文方法。
方法
方法部分主要涉及三个方面,包括数据增强技术、模型设计和训练策略。
数据增强策略
我们首先看一下数据增强策略,这是在实例分割数据集大小受限的情况下,为了获得一致的模型性能而必不可少的部分。考虑到 DeepSportRadar 实例分割数据集的有限规模,数据增强对于获得一致的模型性能至关重要。因此,在本研究中,除了传统的几何和光度变换(如平移、旋转或颜色扰动)之外,还引入了一种专门的复制粘贴数据增强技术。下面将详细介绍这个数据增强技术。
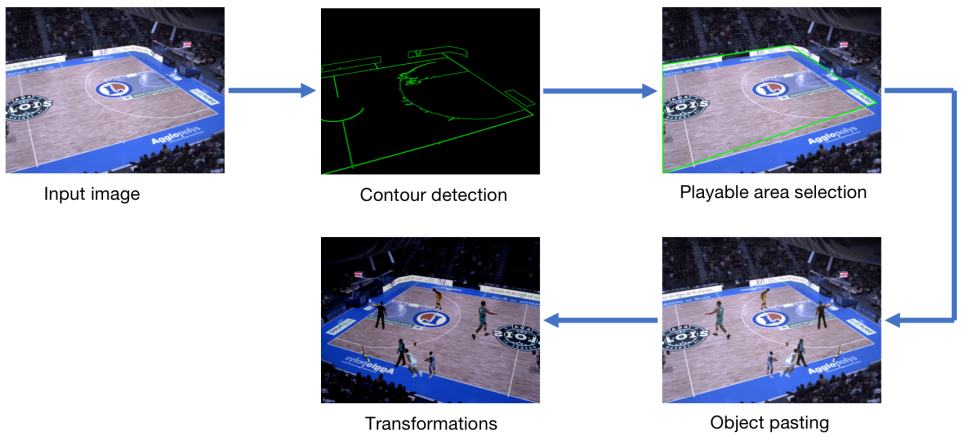
上图展示了复制粘贴数据增强技术的示意图。在这里,作者将数据集中的真实实例(人体对象或篮球球员)称为"entities"(实体)。为了准确地定位和粘贴这些实体在球场上,作者构建了一个自定义的篮球场检测器。这个检测器利用传统的计算机视觉技术,如轮廓检测、颜色检测和霍夫线变换,准确绘制出篮球场的边界。然后,这些实体被随机粘贴到检测到的可播放区域内的坐标上。如果篮球场检测器出现故障或无法精确识别边界,将使用以下默认坐标粘贴实体:
- 对于拍摄篮球场左侧的图像,0 ≤ xmin ≤ w - w/5
- 对于拍摄篮球场右侧的图像,w/5 ≤ xmin ≤ w
这里,w和h分别表示输入图像的宽度和高度,(xmin, ymin)表示要粘贴的实体的坐标。
在这种新颖的复制粘贴方法中,作者使用训练样本的 GT 分割掩码从中提取实体。每个训练图像有80%的概率在篮球场区域内粘贴附加实体。粘贴的实体数量是随机的,但在实践中受到最多40名球员的限制。在复制粘贴后,作者还应用了一个遮挡模块。也就是说,一旦粘贴了一个实体,这个模块将有70%的概率在初始实体的左上象限上叠加另一个实体,从而模拟出在训练集中观察到的现实遮挡情景。这种方法有助于训练模型更好地处理遮挡情况。
模型设计

在模型设计部分,我们主要看下模型架构以及一些关键设计决策。
首先,作者选择了混合任务级联(Hybrid Task Cascade,HTC)作为他们的主要模型架构。与传统的使用ResNet骨干网络不同,他们决定使用CBSwin-Base骨干网络,并结合一个名为CB-FPN的特征金字塔网络。这个选择是在充分考虑模型大小和可用训练资源之间的权衡之后作出的。此决策意味着他们使用了更轻量级的骨干网络,以便在有限的训练资源下提高模型性能。
此外,他们采用了MaskIoU头部来帮助模型学习生成高质量的分割掩码,与传统的方法不同,传统方法通常将置信度分数与分类头部共享。在遮挡场景的情况下,分割掩码的质量至关重要,因此他们选择增强分割掩码预测。为实现这一目标,他们将ROIPooling层提取的掩码特征大小从14×14扩展到20×20。这个修改不仅提高了掩码质量,还帮助模型在严重遮挡的情况下重建物体的细节。
训练策略
最后便来到重要的训练环节。作者从零开始(即没有预训练权重)训练和评估他们的模型。在训练之前,他们需要准备要被复制粘贴算法粘贴的对象。因此,他们从训练数据中提取了所有人体实例以及它们相应的掩码注释和裁剪后的图像,然后将它们保存在本地。在数据增强过程中,复制粘贴算法会随机选择候选对象并为每个对象定义粘贴区域。完成复制粘贴后,他们继续进行其他基本转换的预处理,包括随机调整大小、光度扭曲和几何变换。增强后的图像然后被裁剪和填充到固定尺寸,然后输入到模型中进行训练。
为了调整模型的超参数,他们将324个训练图像分为两组:260个用于训练,64个用于验证。在确定了最佳的超参数集之后,他们固定这些值并在整个训练数据上训练最终的模型。为了提高模型的泛化能力,他们还采用了随机权重平均(Stochastic Weight Averaging,SWA)的训练策略。具体来说,在主要的训练过程之后,他们继续训练模型12个额外的时期,并为每个时期保存一个检查点。在SWA训练之后,他们对保存的12个检查点进行平均以获取最终的权重,然后提交这个模型。
实验
训练细节
- 使用
MMDetection工具箱进行模型训练,这有助于快速开发过程。 - 所有实验是在两块NVIDIA A100-SXM4 GPU上进行的,每块GPU配备了40GB的内存。
- 复制粘贴数据增强之后,图像会被随机调整到以下尺度之一:(3680, 3080), (3200, 2400), (2680, 2080), (2000, 1400), (1920, 1440), (1800, 1200), (1600, 1024), (1333, 800), (1624, 1234), (2336, 1752), (2456, 2054)。
- 随后,训练数据会随机应用一系列光度扭曲、几何变换和裁剪操作。
- 最后,所有图像都会被一致地调整大小和填充到标准分辨率1760×1280。
在整个训练过程中,作者使用Adam优化器,带有分离的权重衰减(AdamW)。学习率设置为1e-4,权重衰减配置为2e-2,以防止过拟合。当模型开始收敛时,他们使用SWA训练策略来对模型进行额外的12个时期的微调。在整个SWA训练过程中,优化器仍然是AdamW,具有固定的学习率1e-4。
此外,在训练过程中,他们调整了掩码头部的损失权重,将其从1.0提高到2.0。这个修改旨在强调模型学习过程中准确掩码生成的重要性。
效果

根据上面我们讲到的训练策略,作者的CBSwin-Base + HTC模型再经过720个时期的训练后,获得了0.514的OM(遮挡)分数(见上表)。基于这些结果,他们保持相同的配置,对更多样本(即训练集+验证集)进行模型训练。在测试集上的初始尝试中,他们获得了0.433的OM分数。意识到可以进行更长时间的训练,他们决定从上次实验的点恢复训练。经过从720个时期延长到1200个时期的训练,作者获得了0.495的OM分数。这显示出比之前尝试的提高了0.062分的显著改进。
最终,他们利用SWA训练策略获得了0.533的最终OM分数,从而在MMSports 2023挑战中获得了最高分!
总结
在这篇技术报告中,我们介绍了用于解决 ACM MMSports 2023 实例分割问题的关键方法和技术。为了解决分割任务中的遮挡问题,作者利用了性能优异的 HTC 架构,搭载特征提取能力较强的 CBSwin-Base 骨干网络,并引入了一种新颖的位置感知复制粘贴数据增强技术,可以随意应用于数据稀缺的分割应用。实验结果表明,本文方法在不需要额外数据或预训练的情况下,在测试集上实现了最先进的结果(以0.533的OM得分排名第一)。这突出了所提方法在处理遮挡场景下的显著性能提升,以及在有限的数据条件下实现出色的效果。
写在最后
如果你也对人工智能或计算机视觉领域等相关技术感兴趣,欢迎添加小编微信:cv_huber,备注"技术交流",与千万研究人员与AI从业者一起交流学习吧!