上篇,我们使用pandas针对飞桨提供的练习题和数据集进行了简单的数据分析。中间也遇到了一些问题,并且提供了解决的方法。本篇,我们仍然使用跟着飞桨的练习题这十套练习,教你如何使用Pandas做数据分析 - 飞桨AI Studio进行操作和总结。本篇主要通过一个2012欧洲杯的例子,实现对数据的过滤和排序。绝非完全follow,会有一些拓展或优化。
目录
一、读取数据
导入pandas库,同样的,设置显示最大区域,防止显示不开。同时,读取飞桨提供的2012欧洲杯的数据集:
import pandas as pd
# 设置显示的最大列、宽等参数,消掉打印不完全中间的省略号
pd.set_option('display.width', 1000)
# 显示所有列
pd.set_option('display.max_columns', None)
# 显示所有行
pd.set_option('display.max_rows', None)
# 读取csv文件
path1 = "exercise_data/Euro2012_stats.csv"
data = pd.read_csv(path1)二、显示数据
1、只读取某一列
例如只读取Goals列:
print(data.Goals)2、统计行数
行数在该例子里面代表的是参与比赛的队伍数:
print(data.shape[0])3、显示概要信息
一般来讲,我们在做数据分析前,先看下每一列的信息比较好,这样才能更好地做后续的数据分析工作。
print(data.info())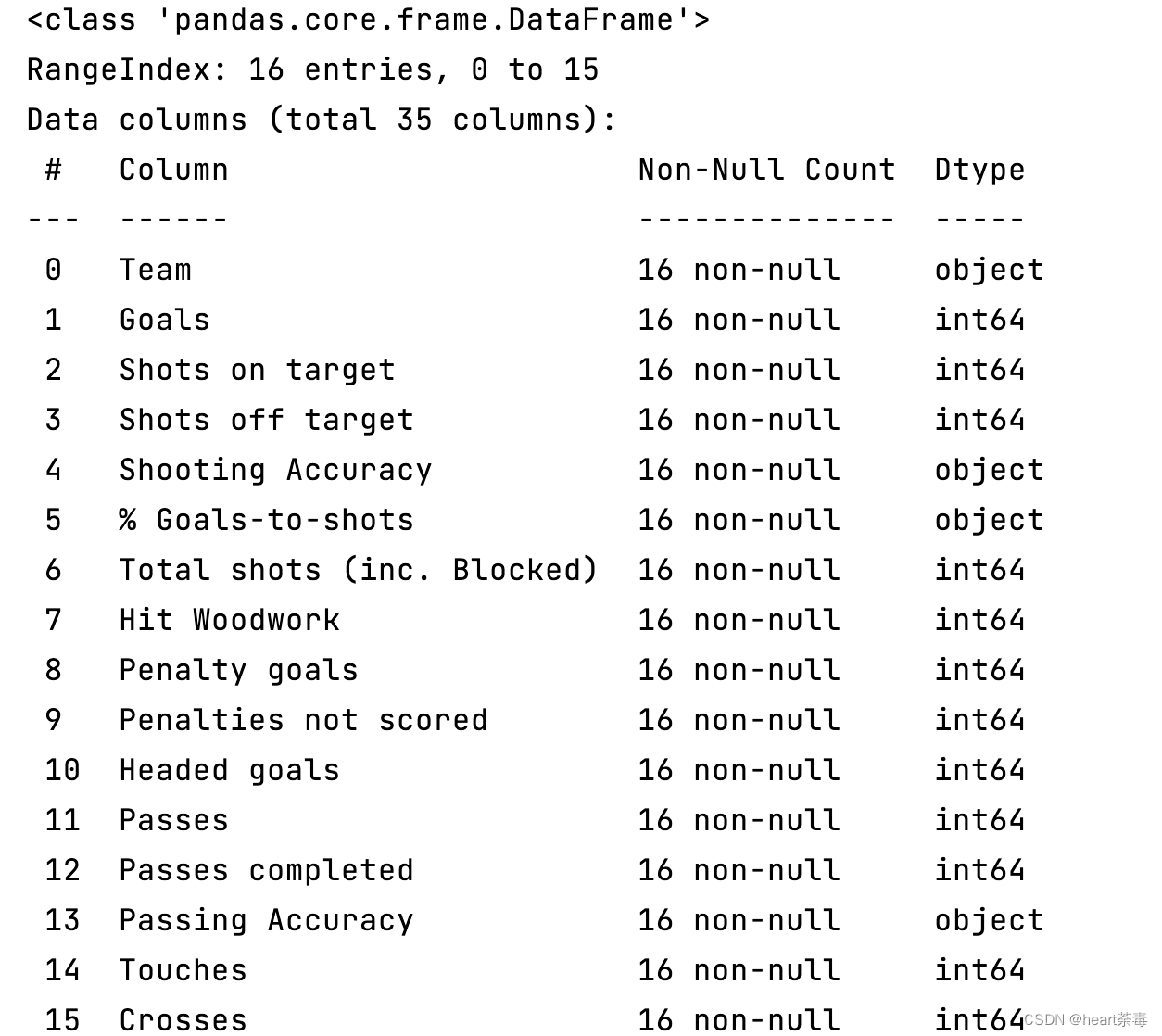
注:data.info()是输出基本信息,比较重要的例如:行列数、每一列的数据类型等。
4、显示整个表格
区别于上面提到的data.info(),data.info直接打印完整的数据表格:
print(data.info)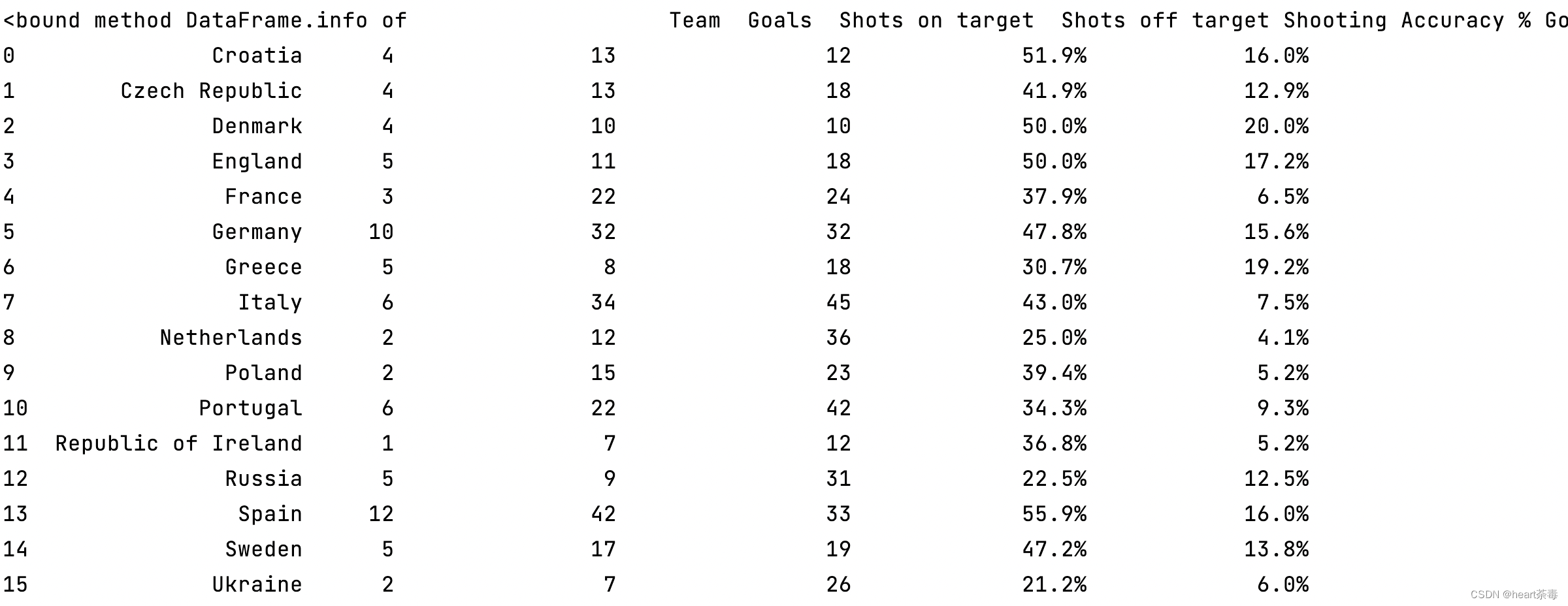
三、局部数据分析
1、选中三列组成新的数据框
这个表格一共有35列,也就是说包含36个纬度的数据,假如我们只想看各队伍得到的红牌和黄牌数量,可以圈一下相关的三列:
# 选中表格中的三列组成数据框
discipline = data[['Team', 'Yellow Cards', 'Red Cards']]
print(discipline)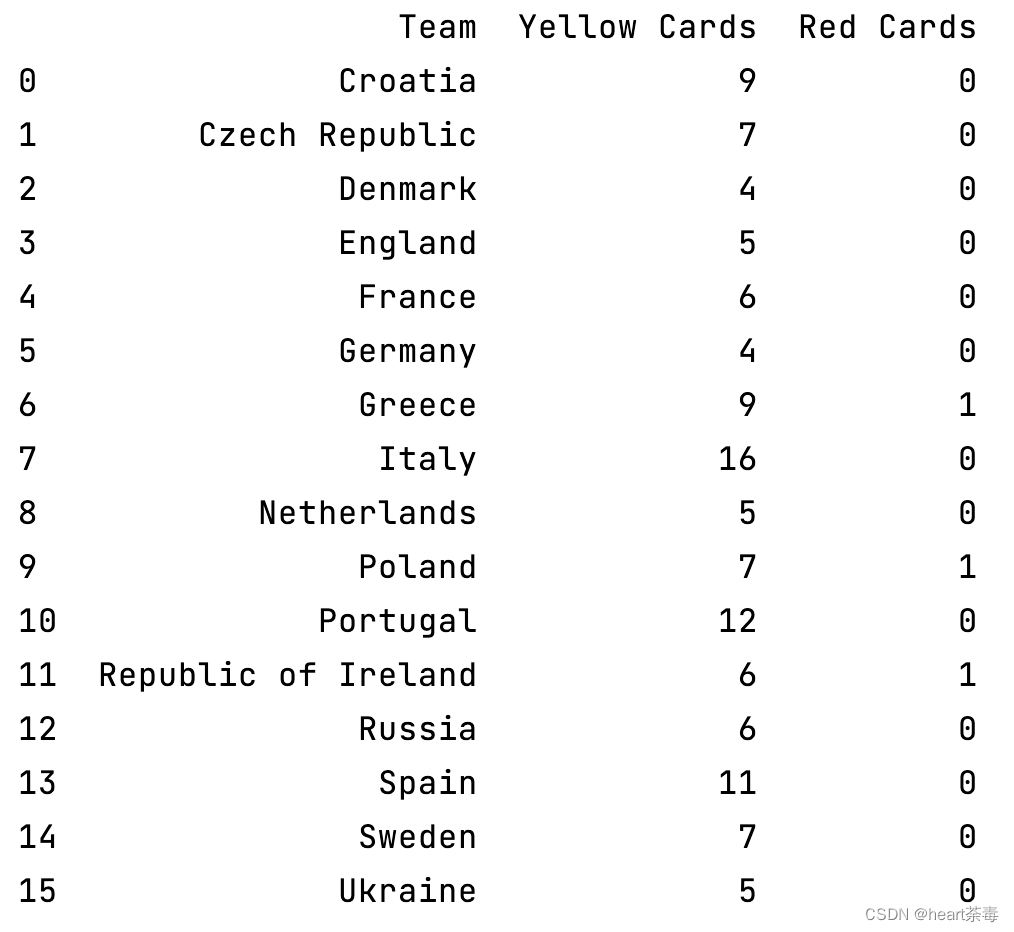
2、主次要依据排序
在Excel统计和分析数据时,我们经常使用一个排序功能。通常,我们会选择一列按照某个规则排序,但是更多的时候我们需要多个依据。例如,在这个例子中,我们按照先红牌次黄牌排序:
print(discipline.sort_values(['Red Cards', 'Yellow Cards'], ascending=False))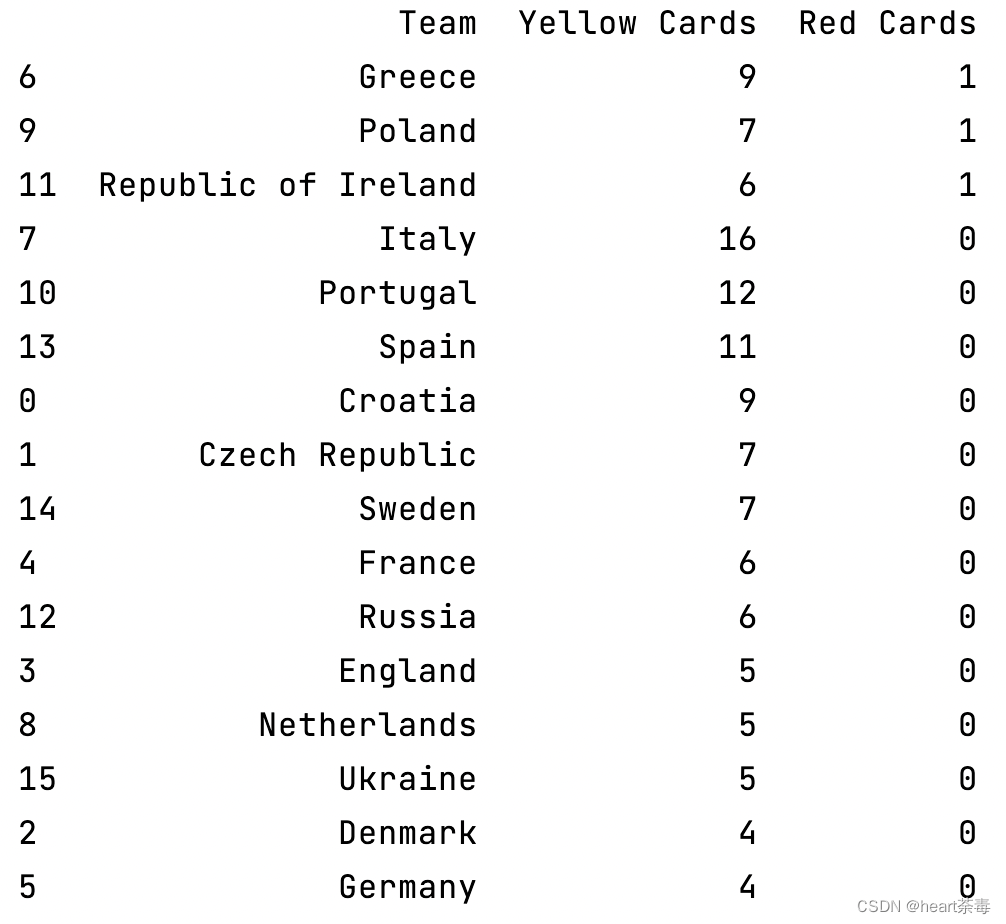
3、计算平均值
例如,在这个例子中,我们去计算黄牌数的平均值:
print(round(discipline['Yellow Cards'].mean()))4、对某一列数据进行条件过滤
比如,我们想看一下奖牌数量超过6个的队伍的信息:
print(data[data.Goals > 6])需要注意的是:当某一列的列名带空格时,我们这样写:
print(data[data['Goals'] > 6])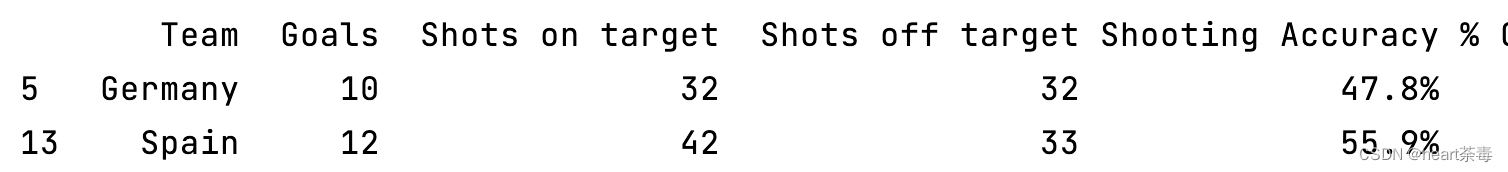
再比如,我们筛选下队名为G开头的队伍信息:
print(data[data['Team'].str.startswith('G')])
5、打印表格的N列/N行
pandas支持类似切片的方式去选取特定的列:
# 前5列
print(data.iloc[:, 0:5])
# 除后3列以外的
print(data.iloc[:, :-3]) 
在这里我们也复习一下选取前N行的函数:
# 前7行
print(data.head(7))6、选取特定行的特定列
例如原练习题中,找到英格兰(England)、意大利(Italy)和俄罗斯(Russia)的射正率(Shooting Accuracy),我不知道射正率是个啥,还是找奖牌数吧。。。。
print(data.loc[data['Team'].isin(['England', 'Italy', 'Russia']), ['Team', 'Goals']])
注意:loc和iloc都是定位某一行的函数,loc是location的意思,而iloc中的 i 指的是Integer,二者的区别如下:
- loc:通过行标签名称索引行数据
- iloc:通过行号索引行数据
四、完整代码
import pandas as pd
# 设置显示的最大列、宽等参数,消掉打印不完全中间的省略号
pd.set_option('display.width', 1000)
# 显示所有列
pd.set_option('display.max_columns', None)
# 显示所有行
pd.set_option('display.max_rows', None)
# 读取csv文件
path1 = "exercise_data/Euro2012_stats.csv"
data = pd.read_csv(path1)
# 打印Goals这一列
print(data.Goals)
# 打印行数
print(data.shape[0])
# 打印info
print(data.info())
# 打印整个表格
print(data.info)
# 选中表格中的三列组成新的表格
discipline = data[['Team', 'Yellow Cards', 'Red Cards']]
print(discipline)
# 主红牌次黄牌排序
print(discipline.sort_values(['Red Cards', 'Yellow Cards'], ascending=False))
# 黄牌平均值
print(round(discipline['Yellow Cards'].mean()))
# 获得奖牌超过6个的队伍信息
print(data[data['Goals'] > 6])
print(data[data['Team'].str.startswith('G')])
print(data.iloc[:, 0:5])
print(data.iloc[:, :-3])
print(data.head(7))
print(data.loc[data['Team'].isin(['England', 'Italy', 'Russia']), ['Team', 'Goals']])
至此,我们跟着第二篇练习走完了。开篇提到的,不只是follow练习,也会有些拓展和优化。本篇主要是对局部数据集的过滤和排序,比较重要的知识点:
(1)loc和iloc两个定位行的函数
(2)选取某一列推荐data['xxx'],不推荐data.xxx,因为当xxx含有空格时不work
后续,当我们把这一套练习题捋完后,有必要整理一下pandas的常用api以及坑和误区。