本篇仍然使用飞桨的练习题和数据集来整理下pandas数据分组,仍然先抛出链接这十套练习,教你如何使用Pandas做数据分析 - 飞桨AI Studio,感谢提供数据集。本篇仍然会按照练习题进行,当然我不是照本宣科,仍然会有一些扩展和避坑。
目录
一、读取数据
三部曲:导入pandas库、设置最大行列、读取数据
import pandas as pd
# 设置显示的最大列、宽等参数,消掉打印不完全中间的省略号
pd.set_option('display.width', 1000)
# 显示所有列
pd.set_option('display.max_columns', None)
# 显示所有行
pd.set_option('display.max_rows', None)
# 读取csv文件
path1 = "exercise_data/drinks.csv"
data = pd.read_csv(path1)读取完数据,先head看下每一列代表什么。包括国家、啤酒消费数、雪碧消费数、红酒消费数、每升酒精含量、大陆:
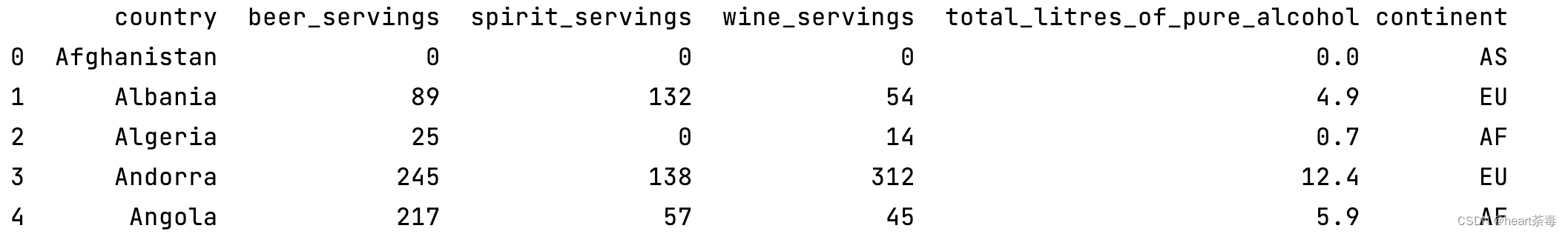
二、数据分析
1、每个大陆啤酒消费平均数
'beer_servings'求均值,'continent'groupby一下:
print(data.groupby('continent')['beer_servings'].mean())2、所有国家平均啤酒消费数
直接对'beer_servings'求均值:
print(round(data['beer_servings'].mean()))3、描述性统计
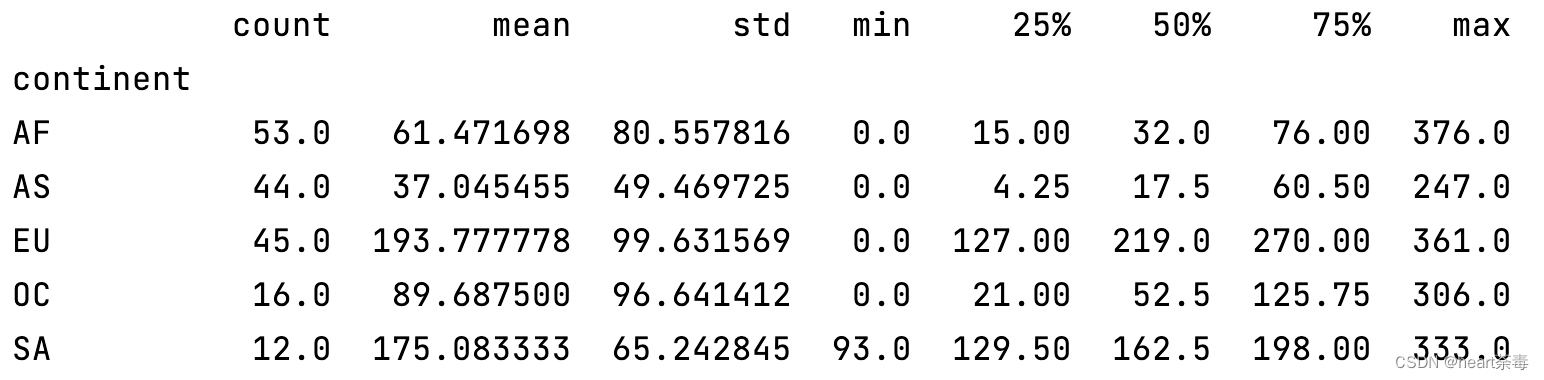
例如打印每个大洲的啤酒消费描述性统计:
print(data.groupby('continent')['beer_servings'].describe())打印出的描述性统计包括数量、平均值、标准差、最小值、25分位、50分位、75分位、最大值:
4、每个大陆各种饮料消费平均值
print(data.groupby('continent').mean())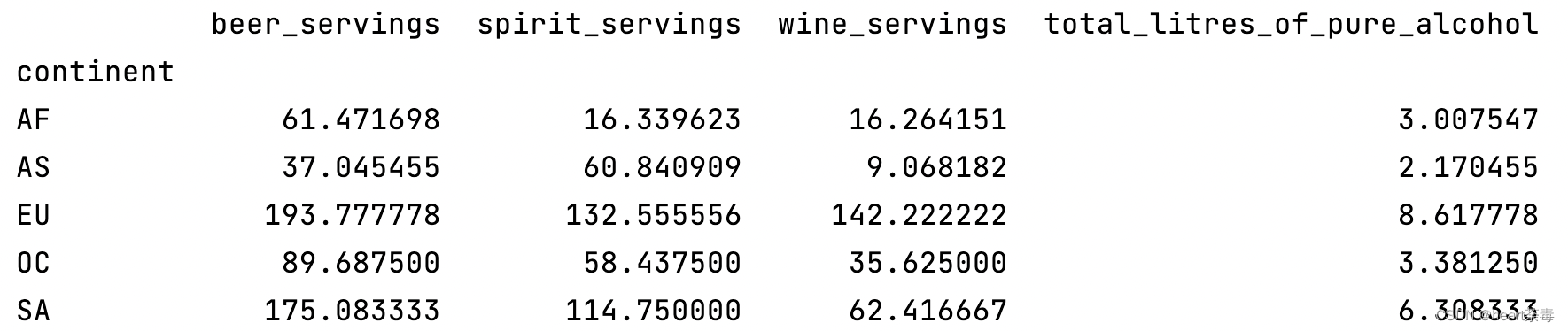 注意,这里报了一个FutureWarning: The default value of numeric_only in DataFrameGroupBy.mean is deprecated. In a future version, numeric_only will default to False. Either specify numeric_only or select only columns which should be valid for the function.
注意,这里报了一个FutureWarning: The default value of numeric_only in DataFrameGroupBy.mean is deprecated. In a future version, numeric_only will default to False. Either specify numeric_only or select only columns which should be valid for the function.
print(data.groupby('continent').mean())
意思是,mean()函数默认为numeric_only=True,也就是仅对数字类型的列生效。但是后面的版本可能会默认为false,这样必须选取数字类型的列或者指定为True才可以使用。因此,我们直接指定为True:
print(data.groupby('continent').mean(numeric_only=True))5、每个大陆各种饮料消费中位数
print(data.groupby('continent').median(numeric_only=True))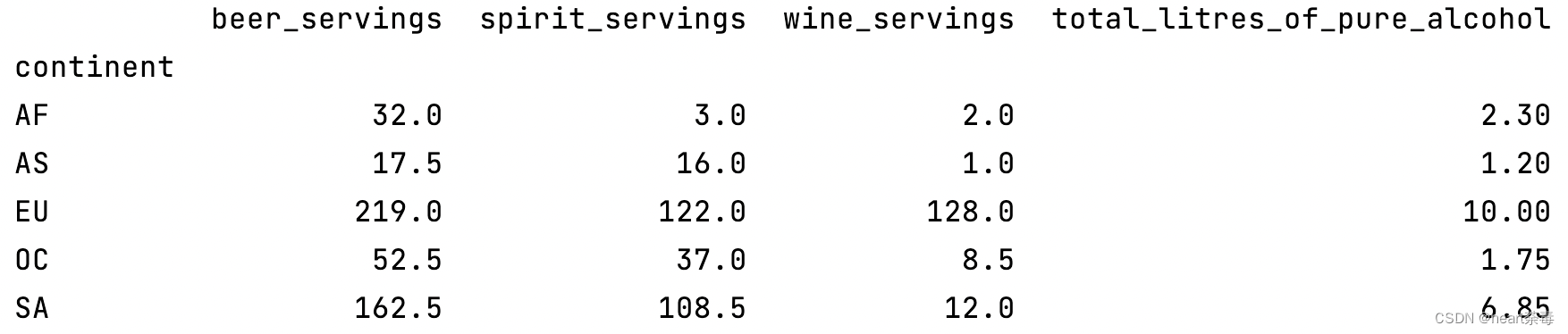
6、每个大陆spirit饮品消耗的平均值,最大值和最小值
print(data.groupby('continent')['spirit_servings'].agg(['mean', 'min', 'max']))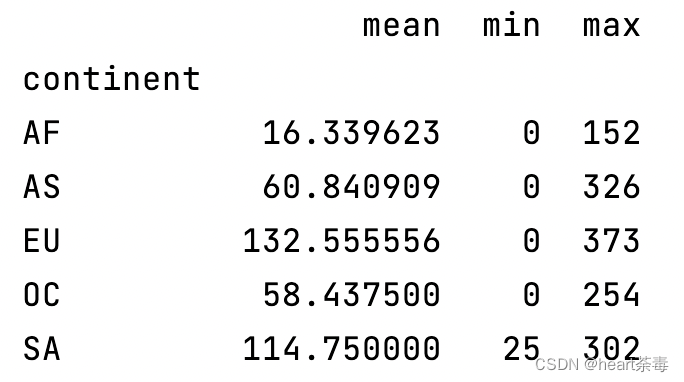
7、避坑
到这里,我们本篇随着练习题走完了。但是,不知道各位有没有发现一个非常大的问题?地球上不是有七大洲吗?我们掰掰手指头:亚洲、欧洲、非洲、大洋洲、南极洲、南美洲、北美洲,但是,为什么我们按照洲的纬度groupby后,只有5个了?南极洲没有人居住我们忽略,数据集里面确实也没有南极洲。另外缺少的是北美洲?那么北美洲去哪了?
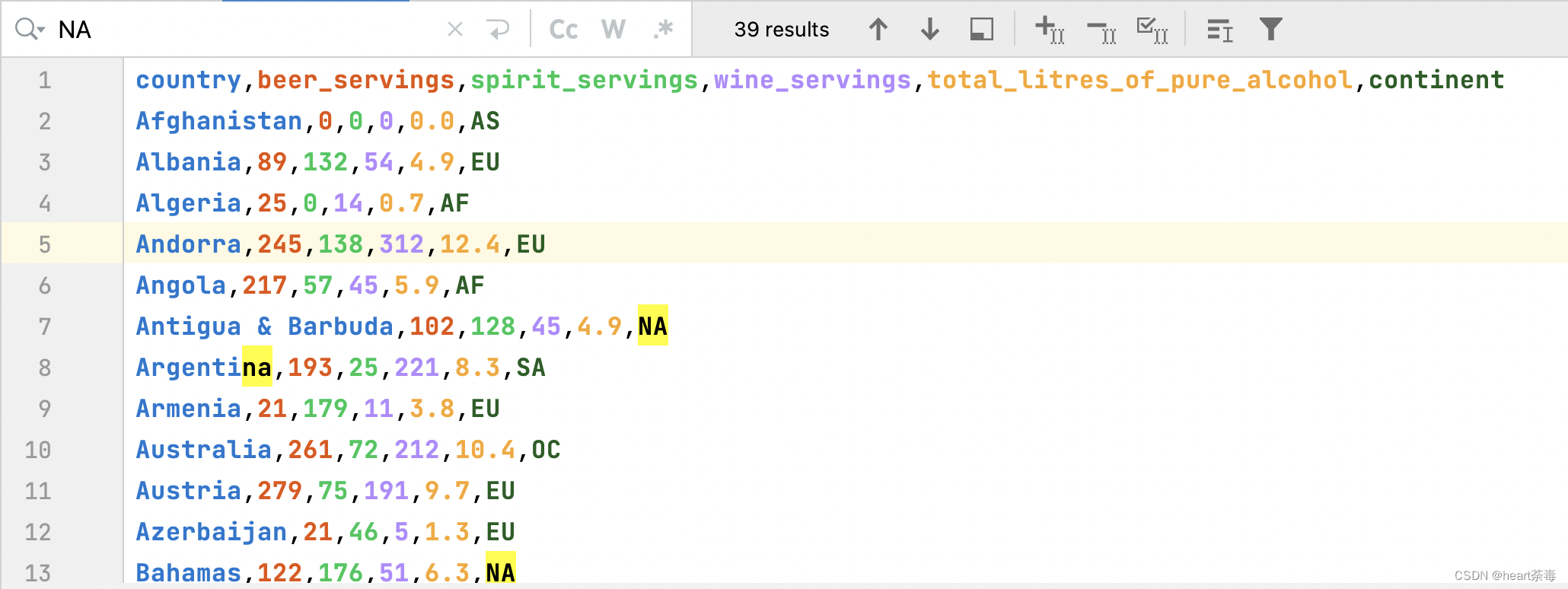
如上,北美洲简称为NA,而pandas自动忽略了NA,认为NA为非法的。那么如何解决这个问题?pandas提供了dropna和fillna来解决这种问题,dropna可以这样:
print(data.groupby('continent', dropna=False)['spirit_servings'].agg(['mean', 'min', 'max']))这样做,pandas就不会忽略NA了,但是会显示为NaN:
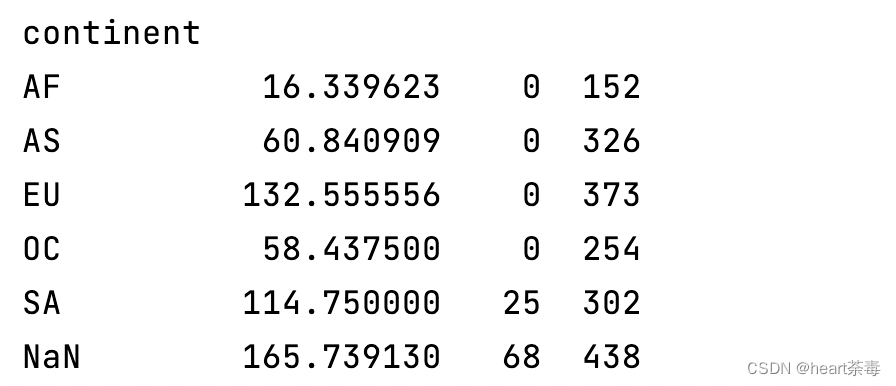
那如何让其正确的显示为NA呢?可以使用fillna来做:
print(data.fillna({'continent': 'NA'}).groupby('continent')['spirit_servings'].agg(['mean', 'min', 'max']))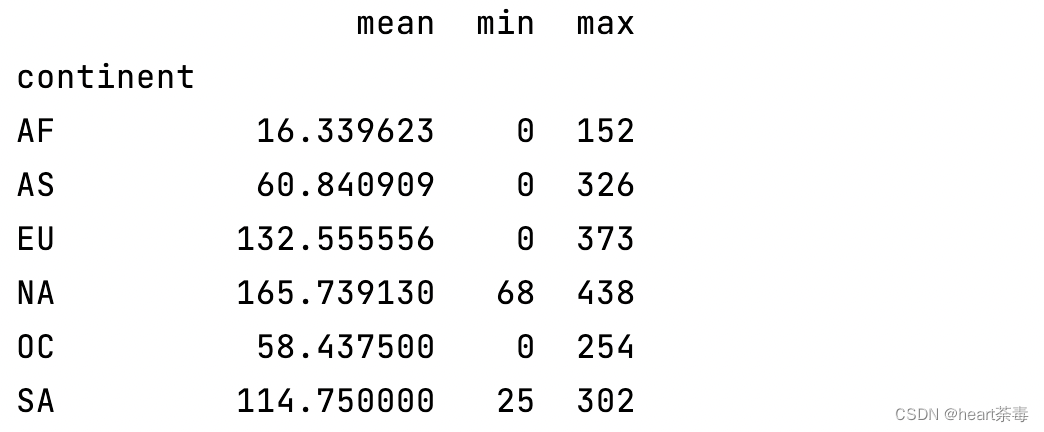
注意:很多情况下,我们不能直接丢弃NA。当然,也不能直接让它显示为NA。本次case的特殊性在于:北美洲的简称为NA,跟python的NA碰巧了。。。。
三、完整代码
import pandas as pd
# 设置显示的最大列、宽等参数,消掉打印不完全中间的省略号
pd.set_option('display.width', 1000)
# 显示所有列
pd.set_option('display.max_columns', None)
# 显示所有行
pd.set_option('display.max_rows', None)
# 读取csv文件
path1 = "exercise_data/drinks.csv"
data = pd.read_csv(path1)
print(data.head())
# 每个大陆的啤酒消费平均数
print(data.groupby('continent')['beer_servings'].mean())
# 所有国家平均啤酒消费数
print(round(data['beer_servings'].mean()))
# 每个大陆的啤酒消费的描述性统计值
print(data.fillna({'continent': 'NA'}).groupby('continent')['beer_servings'].describe())
# 每个大陆各种饮料消费平均值
print(data.fillna({'continent': 'NA'}).groupby('continent').mean(numeric_only=True))
# 每个大陆各种饮料消费中位数
print(data.fillna({'continent': 'NA'}).groupby('continent').median(numeric_only=True))
# 每个大陆spirit饮品消耗的平均值,最大值和最小值
print(data.fillna({'continent': 'NA'}).groupby('continent')['spirit_servings'].agg(['mean', 'min', 'max']))
到这里,我们真的就完成了。我个人一点小吐槽,飞桨平台虽然提供了一些pandas的练习题和数据集,但是有些坑可能他们自己也没有注意到,或者说对新手来讲不太友好。我最近这一系列的博客,会跟随练习题的同时,尽量把一些坑和发现的问题给整理和纠正出来。